데이터 랭글링(데이터 분석을 위한 15가지 Pandas 기능)
데이터 분석가를 위한 최고의 무기! Pandas!
Python의 이 강력한 라이브러리는
데이터 조작 및 탐색을 쉽고 즐겁게 만듭니다.
이번 포스팅에서는 "Palmer Penguins"라는
인기 있는 데이터 세트를 사용하여
Pandas의 고급 기능 중 일부를 살펴보고,
사용 방법의 예를 제공하도록 하겠습니다.
# Palmer Penguins 데이터 불러오기
pip install palmerpenguins # palmerpenguins 라이브러리 설치하기
import pandas as pd # pandas 라이브러리 로딩
import seaborn as sns #seaborn 라이브러리 로딩
from palmerpenguins import load_penguins
sns.set_style('whitegrid')
penguins = load_penguins()
penguins.head()

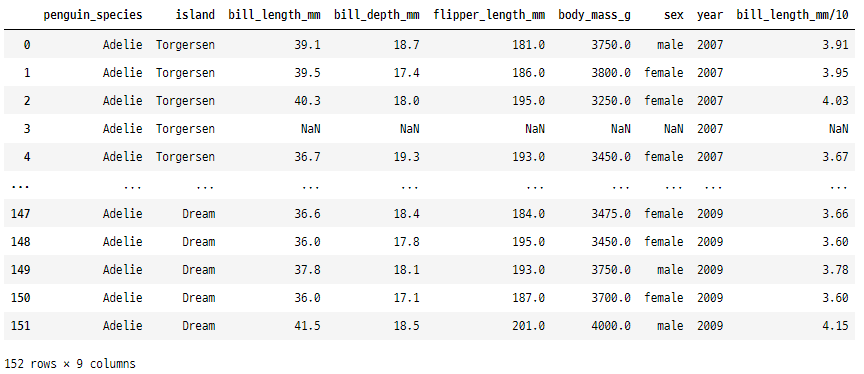
1. apply()
이 함수는 DataFrame 또는 Series의 각 요소 또는
행/열에 함수를 적용하는 데 사용됩니다.
# bill_length_mm 칼럼의 모든 값을 10으로 나누어 새로운 칼럼 bill_length_mm/10 생성하기
penguins["bill_length_mm/10"] = penguins["bill_length_mm"].apply(lambda x: x/10)
penguins.head()

2. nunique()
이 함수는 DataFrame 열의 고유한 값의
수를 계산하는 데 사용됩니다.
penguins["species"].nunique()

3. sort_values()
이 함수는 오름차순 또는 내림차순으로
하나 이상의 열을 기준으로
DataFrame을 정렬하는 데 사용됩니다.
penguins.sort_values("body_mass_g", ascending=False)

4. rename()
이 함수는 DataFrame의
열 이름을 변경하는 데 사용됩니다.
penguins = penguins.rename(columns = {"species":"penguin_species"})
penguins.head()

5 . groupby()
이 함수는 DataFrame의 데이터를
하나 이상의 열로 그룹화한 다음
그룹화된 데이터에 대해 계산을 수행하는 데 사용됩니다.
이것은 데이터 집계 및 분석에
자주 사용되는 강력한 기능입니다.
groupedPenguins = penguins.groupby("penguin_species").mean()
groupedPenguins

6. query()
이 함수는 쿼리 문자열을 기반으로
DataFrame의 행을 필터링하는 데 사용됩니다.
adeliePenguins = penguins.query('penguin_species == "Adelie"')
adeliePenguins
7. melt()
meltedPenguins = penguins.melt(id_vars=["penguin_species"], value_vars=["bill_length_mm", "bill_depth_mm"]) meltedPenguins

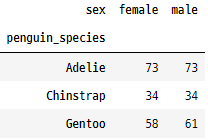
8. crosstab()
이 함수는 DataFrame에서 둘 이상의 열에 대한
교차 표를 만드는 데 사용됩니다.
두 범주형 변수 간의 관계를 분석하는 데 유용합니다.
crosstab = pd.crosstab(penguins['penguin_species'], penguins['sex'])
crosstab
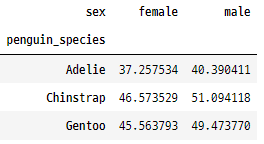
9. pivot_table()
이 함수는 DataFrame에서
피벗 테이블을 만드는 데 사용됩니다.
피벗 테이블은 하나 이상의 열로 그룹화된
데이터 요약이며
데이터 탐색 및 분석에 유용합니다.
pivot = penguins.pivot_table(index='penguin_species', columns='sex', values='bill_length_mm', aggfunc='mean')
pivot
10. iloc() and loc()
이 함수는 인덱스 또는 라벨로
DataFrame에서 행과 열을 선택하는 데 사용됩니다.
iloc 함수는 정수 기반 인덱싱으로
행과 열을 선택하는 데 사용되며,
loc 함수는 라벨 기반 인덱싱으로
행과 열을 선택하는 데 사용됩니다.
penguins.iloc[0, 0] # 결과는 'Adelie'
penguins.loc[0, "penguin_species"] # 결과는 'Adelie'
11. cut()
이 함수는 연속 데이터를 이산 간격으로
비닝하는 데 사용되며
데이터 탐색 및 시각화에 유용합니다.
penguins['body_mass_g_binned'] = pd.cut(penguins['body_mass_g'], bins=np.linspace(0, 6000, num=6))
penguins
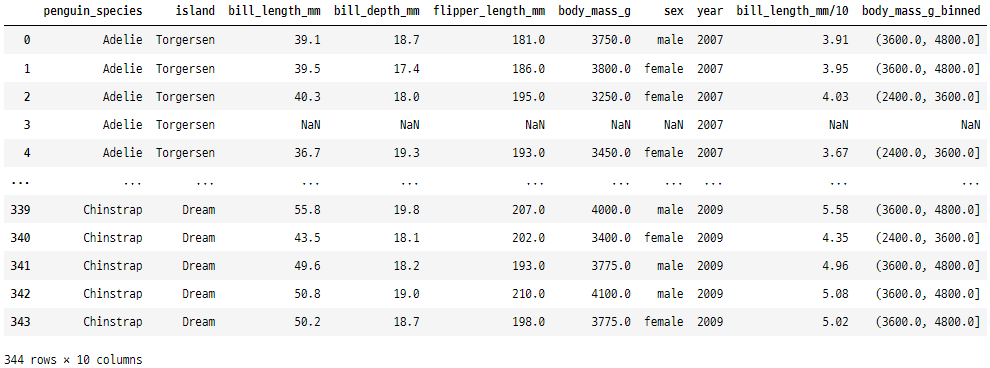
12. isin()
이 함수는 값 리스트와 값을 일치시켜
DataFrame을 필터링하는 데 사용됩니다.
species_list = ['Adelie', 'Chinstrap']
penguins[penguins['penguin_species'].isin(species_list)]
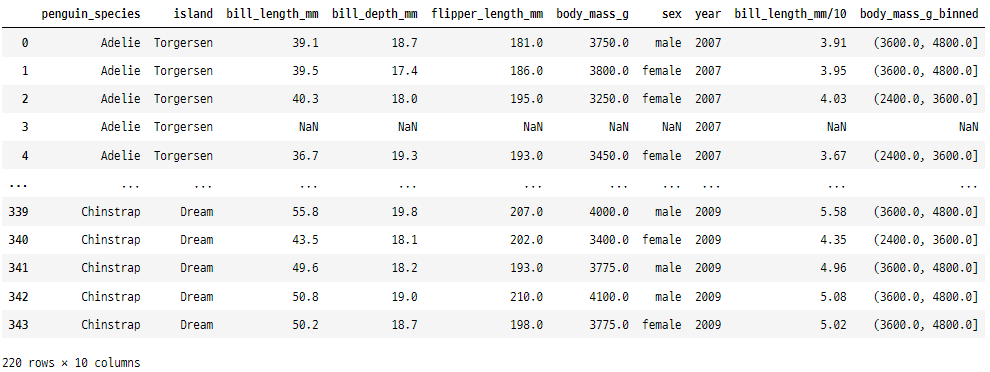
13. value_counts()
이 함수는 DataFrame의 열에서
각 고유 값의 발생 횟수를 계산하는 데 사용됩니다.
penguins['penguin_species'].value_counts()
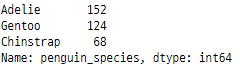
14. drop()
이 함수는 DataFrame에서
하나 이상의 열 또는 행을 삭제하는 데 사용됩니다.
penguins.drop("penguin_species", axis=1)
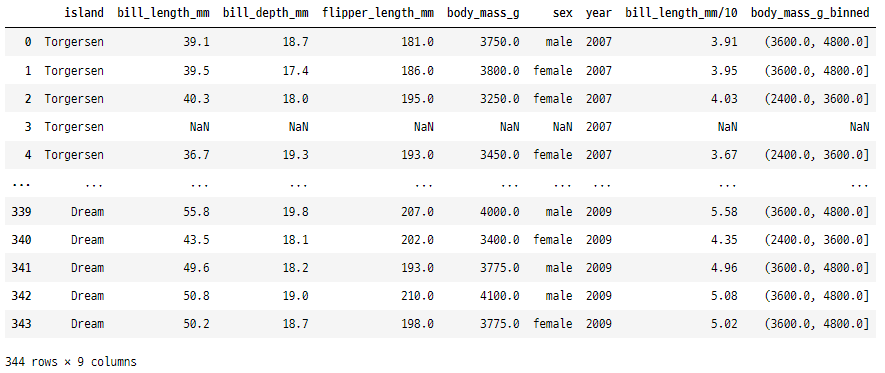
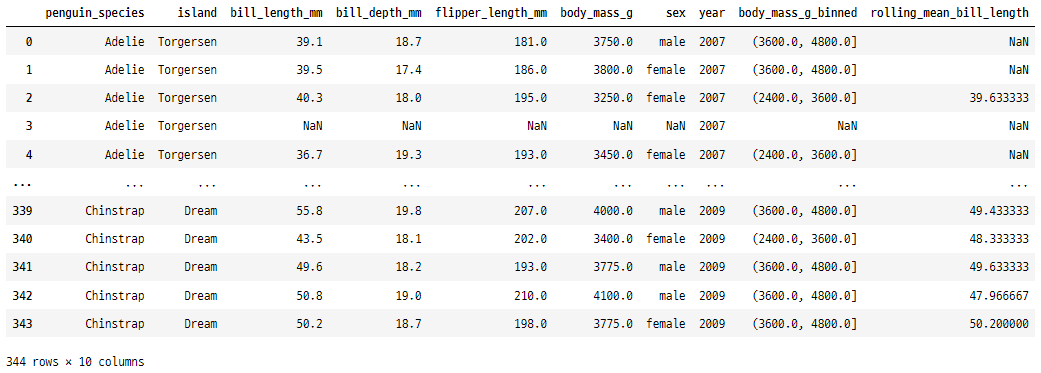
15 . rolling()
이 함수는 DataFrame 또는 Series에서
특정 크기의 롤링 창을 생성하여
각 창에 대한 통계 계산을 허용하는 데 사용됩니다.
penguins["rolling_mean_bill_length"] = penguins["bill_length_mm"].rolling(window=3).mean()
penguins.drop("bill_length_mm/10", axis = 1)