
데이터 처리 시 알아야 할 7가지 메모리 최적화 기술
실제 적용 가능한 기계 학습 모델을
설계하고 구축하는 것은 항상
데이터 과학자에게 큰 관심입니다.
이로 인해 불가피하게 최적화되고
효율적이며 정확한 방법을
대규모로 활용하게 되었습니다.
런타임 및 메모리 수준의 최적화는
실제 및 사용자 대면 소프트웨어 솔루션을
지속 가능하게 제공하는 데
기본적인 역할을 합니다.
이번 포스팅에서는 최적화의
또 다른 영역을 탐색하고
Pandas DataFrame의
메모리 사용을 최적화하는
몇 가지 기술을 소개하고자 합니다.
이러한 방법은 Pandas에서
일반적인 테이블 형식 데이터 분석,
관리 및 처리 작업을
효율적으로 수행하는 데 도움이 됩니다.
1. DataFrame에 대한 내부 수정
DataFrame을 Python 환경에 로드하면
일반적으로 DataFrame에 대해
많은 수정 작업을 진행합니다.
여기에는 새 열 추가, 머리글 이름 바꾸기,
열 삭제, 행 값 변경, NaN 값 바꾸기
등이 포함됩니다.
이러한 작업은 일반적으로 아래와 같이
두 가지 방법으로 수행할 수 있습니다.
1.1. 표준 할당(Standard Assignment)
표준 할당은 변환 후 DataFrame의
새 복사본을 만들고
원래 DataFrame은 그대로 둡니다.
import pandas as pd
import numpy as np
df = pd.DataFrame({"col1" : [1, 4, np.NaN],
"col2" : ["A", "B", "C"],
"col3" : [1.3, 2.9, 5.6]})
df

# 표준 할당
dfFillna0 = df.fillna(0)
dfFillna0
표준 할당의 결과로 두 개의 고유한
Pandas DataFrames(원본 및 변환됨)가
메모리(위의 df 및 dfFillna0)에 공존하여
메모리 사용률이 두 배로 증가합니다.
1.2. 내부 할당(Inplace Assignment Operations)
표준 할당 작업과 달리 내부 할당 작업은
새 Pandas DataFrame 개체를 만들지 않고
원래 DataFrame 자체를 수정하려고 합니다.
# 내부 할당 작업
df.fillna(0, inplace = True)
df
따라서 DataFrame의 중간 복사본(위의 df_copy)이
프로젝트에서 사용되지 않는 DataFrame이라면
내부 할당 경로를 사용하는 것이
메모리가 제한된 응용 프로그램에서
진행하는 이상적인 방법입니다.
1.3. 결론
중간에 생성한 DataFrame이 필요하고
입력을 변경하고 싶지 않을 때는
표준 할당(또는 inplace=False) 사용
메모리 제약으로 작업하고 중간 DataFrame을
특별히 사용하지 않는 경우
내부 할당(또는 inplace=True) 사용
2. CSV에서 필수 열(column)만 읽기
CSV 파일에 수백 개의 열이 있고
그중 관심 있는 열의 하위 집합만
필요한 경우를 가정해 봅시다.
예를 들어 Faker data set를 사용하여
15개 열과 10⁵ 행으로 만든
더미 DataFrame의 처음 5개 행을 출력합니다.
peopleData = pd.read_csv("D:/People_data.csv")
peopleData.head()
peopleData.columns
이 15개 열 중 가장 관심이 있는 5개의 열만
Pandas DataFrame으로 로드하려고 합니다.
이러한 열은 Name, Birth Date, State, Year, Link 입니다.
2.1. 모든 열 로딩하기
전체 CSV 파일을 python 환경으로 읽으려면
Pandas가 사용하지 않는 열을 로드하고
데이터 유형을 유추해야 하고,
이것은 런타임 및 메모리 사용량 증가로 이어집니다.
아래와 같이 info() 메서드를 사용하여
Pandas DataFrame의
메모리 사용량을 찾을 수 있습니다.
peopleData.info(memory_usage = "deep")
DataFrame은 15개 열이 모두 로드된 상태에서
메모리에 9.2MB의 공간을 보유합니다.
CSV 파일을 로드하는 런타임은
다음과 같이 계산됩니다.
%timeit pd.read_csv("D:/People_data.csv")

2.2. 필요한 열만 로딩하기
모든 열을 읽는 것과 달리 관심 있는 열의
하위 집합만 있는 경우 pd.read_csv() 메서드의
usecols 인수에 리스트로 전달할 수 있습니다.
메모리 사용률 계산은 아래에 설명되어 있습니다.
colList = ["Name", "Birth Date", "State", "Year", "Link"]
data = pd.read_csv("D:/People_data.csv", usecols=colList)
data.info(memory_usage = "deep")
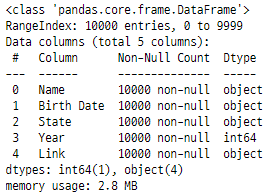
관심 있는 열만 로드하면
메모리 사용률이 거의 3배 감소하여
이전의 9.2MB에서
약 2.8MB의 공간을 차지했습니다.
%timeit pd.read_csv("D:/People_data.csv", usecols=colList)
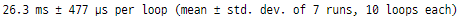
로딩 실행 시간도 감소하여
모든 컬럼을 로딩하는 것과 비교하여
거의 2배에 가까운 부스트를 제공합니다.
2.3. 결론
필요한 열만 로드하면
런타임 및 메모리 사용률이
크게 향상될 수 있습니다.
따라서 큰 CSV 파일을 로드하기 전에
몇 개의 행(예: 처음 5개)만 로드하고,
관심 있는 열만 나열하여 최종 로딩합니다.
열의 데이터 유형 변경
기본적으로 Pandas는 항상
가장 높은 메모리 데이터 유형을
열에 할당합니다.
예를 들어 Pandas가
열을 정수 값으로 해석한 경우
선택할 수 있는 4개의 하위 범주가 있을 수 있습니다.
- int8: [-2⁷, 2⁷] 사이 정수를 포함하는 8비트 정수
- int16: [-2¹⁵, 2¹⁵] 사이 정수를 포함하는 16비트 정수
- int32: [-2³¹, 2³¹] 사이 정수를 포함하는 32비트 정수
- int64: [-2⁶³, 2⁶³] 사이 정수를 포함하는 64비트 정수
그러나 Pandas는 열의 현재 값 범위에 관계없이
항상 정수 값 열의 데이터 유형으로 int64를 할당합니다.
float16, float32 및 float64와 같은
float 값 숫자에도 유사한 의미가 있습니다.
참고: 위에서 사용한 것과 동일한
더미 데이터 세트를 참조합니다.
DataFrame의 현재 메모리 사용률은
9.2MB입니다.
3. 정수 열의 데이터 유형 변경
Zip Code 열을 고려하여
최댓값과 최솟값을 찾습니다.
print("Zip Code 열의 데이터 유형은", peopleData["Zip Code"].dtype)
print("Zip Code 열의 최댓값은", peopleData["Zip Code"].max())
print("Zip Code 열의 최솟값은", peopleData["Zip Code"].min())

Zip Code열은 잠재적으로
int32(2^(-31) < 99949 < 2^(31))로
해석될 수 있지만
Pandas는 여전히 열에 int64 유형을 채택했습니다.
Pandas는 astype() 메서드를 사용하여
열의 데이터 유형을 변경할 수 있는
유연성을 제공합니다.
변환 전후의 메모리 사용량과 함께
Zip Code 열의 변환은 다음과 같습니다.
print("데이터 유형 변환 전 메모리 사용량:", peopleData["Zip Code"].memory_usage())
peopleData["Zip Code"] = peopleData["Zip Code"].astype(np.int32)
print("데이터 유형 변환 후 메모리 사용량:", peopleData["Zip Code"].memory_usage())

Zip Code 열에서 사용하는 총메모리는
이 간단한 한 줄 데이터 유형 변환으로
절반으로 줄었습니다.
유사한 최소-최대 분석을 사용하여
다른 정수 및 부동 소수점 값 열의
데이터 유형을 변경할 수도 있습니다.
4. 범주형 데이터를 나타내는 열의 데이터 유형 변경
이름에서 알 수 있듯이 범주형 열은
전체 열에서 계속해서 반복되는
몇 가지 고유 값으로 구성된 열입니다.
예를 들어 아래와 같이
nunique() 메서드를 사용하여
몇 개의 열에서 고유한 값의 수를 알아보겠습니다.
print("레코드 수 :", peopleData.shape[0])
print("고유한 Prefix 수 :", peopleData.Prefix.nunique())
print("고유한 City 수 :", peopleData.City.nunique())
print("고유한 State 수 :", peopleData.State.nunique())

DataFrame의 크기와 관련하여
이러한 열의 고유한 값의 수는
범주형 열임을 나타냅니다.
기본적으로 Pandas는
이러한 모든 열의 데이터 유형을
본질적으로 문자열 유형인 객체(object)로
유추했습니다.
print("Prefix 데이터 유형 :", peopleData.Prefix.dtype)
print("City 데이터 유형 :", peopleData.City.dtype)
print("State 데이터 유형 :", peopleData.State.dtype)

astype() 메서드를 사용하면
범주형 열의 데이터 유형을
범주로 변경할 수 있습니다.
메모리 사용률 감소는 다음과 같습니다.
print("데이터 유형 변환 전 메모리 사용량:", peopleData["Prefix"].memory_usage())
peopleData["Prefix"] = peopleData["Prefix"].astype("category")
print("데이터 유형 변환 후 메모리 사용량:", peopleData["Prefix"].memory_usage())

문자열에서 범주형으로 변환하면
메모리 사용률이 87% 감소하는 것을
알 수 있습니다.
유사한 고유 요소 분석을 사용하여
다른 잠재적 범주형 열의
데이터 유형을 변경할 수 있습니다.
5. NaN 값으로 열의 데이터 유형 변경
실제 데이터 세트에서
missing 값은 불가피합니다.
missing 값을 가지는 데이터 세트에서
열을 예비 데이터 구조로 표시하면
상당한 메모리 효율성을 제공할 수 있습니다.
astype() 메서드를 사용하여
희소 열의 데이터 유형을
Sparse[str]/Sparse[float]/Sparse[int]
데이터 유형으로 변경할 수 있습니다.
예시 데이터에서 missing 값이 없어
명령문만 알아보도록 하겠습니다.
data["missing값을 가지는 열이름"] = data["missing값을 가지는 열이름"].astype("Sparse[float32]")
3 ~ 5. 결론
Pandas는 항상 메모리 데이터 유형이
가장 큰 열을 할당합니다.
열의 값 범위가 데이터 유형의 범위에
걸쳐 있지 않으면 열의 데이터 유형을
가장 최적의 유형으로 다운그레이드 하는 것이 좋습니다.
6. CSV를 읽는 동안 열 데이터 유형 지정
위의 섹션 #3-#5에서 논의된 팁은
Python 환경에 Pandas DataFrame이
이미 로드되어 있음을 가정합니다.
즉, 메모리 활용을 최적화하기 위한
사후 입력 팁이었습니다.
그러나! 데이터 세트를 로드하는 것이
주요 문제인 상황에서는
입력 중에 Pandas가 수행하는
데이터 유형 해석 작업을 제어하고
열을 유추할 특정 데이터 유형을
지정할 수 있습니다.
다음과 같이 pd.read_csv() 메서드에
dtype 인수를 전달하여
이를 수행할 수 있습니다.
colList = ["Name", "Birth Date", "State", "Year", "Link"]
data = pd.read_csv("D:/People_data.csv", usecols=colList,
dtype = {"Year":np.int16, "State":"category"})
data.info(memory_usage = "deep")
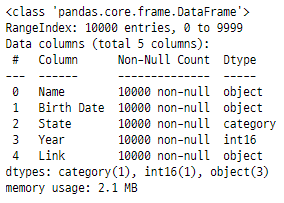
위에 표시된 것처럼
dtype 인수는 column-name에서
데이터 유형으로의 딕셔너리 매핑을
기대할 수 있습니다.
결론
데이터 딕셔너리나 다른 소스를 통해
CSV의 일부(또는 모든) 열에 있는
데이터 유형을 알고 있는 경우
가장 적합한 데이터 유형을 직접 추론하고
pd.read_csv의 dtype 인수에 전달하여
DataFrame으로 변환할 수 있습니다.
7. CSV에서 청크로 데이터 읽기
마지막으로 팁 #6에서 할 수 있는
모든 작업을 수행했지만
메모리 제약으로 인해
CSV를 로드할 수 없다고 가정해 보겠습니다.
이번에 알려드릴 마지막 팁이
순 메모리 사용률을 최적화하는 데
도움이 되지는 않지만
극단적인 상황에서 사용할 수 있는
대규모 데이터 세트를
로드하기 위한 해결 방법이 될 수 있습니다.
Pandas의 입력 방법은 직렬화됩니다.
따라서 CSV 파일에서
한 번에 하나의 행(또는 라인)만 읽습니다.
행 수가 너무 많아 한 번에
메모리에 로드할 수 없는 경우
대신 행의 세그먼트(또는 청크)를
로드하고 처리한 다음
CSV 파일의 다음 세그먼트를
읽을 수 있습니다.
다음과 같이 chunksize 인수를
pd.read_csv() 메서드에 전달하여
청크 기반 입력 프로세스를 활용할 수 있습니다.
for chunk in pd.read_csv("D:/People_data.csv", chunksize=5000):
## process chunk
pass
모든 청크 개체는 Pandas DataFrame이며
다음과 같이 Python에서
type() 메서드를 사용하여 이를 확인할 수 있습니다.
for chunk in pd.read_csv("D:/python_exer/People_data.csv", chunksize=5000):
print(type(chunk))
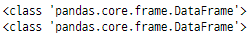
결론
CSV 파일이 너무 커서 메모리에 맞지 않으면
청킹 방법을 사용하여
CSV 세그먼트를 로드하고 하나씩 처리합니다.
이 방법의 한 가지 주요 단점은
전체 DataFrame이 필요한 작업을
수행할 수 없다는 것입니다.
예를 들어 열에 대해
groupby() 작업을 수행하려고 한다고
가정해 보겠습니다.
여기서, 그룹에 해당하는 행은
서로 다른 청크에 있을 수 있습니다.
최종 결론
이번 포스팅에서는 대용량 데이터를 다루는
프로젝트에서 직접 활용할 수 있는
Pandas의 7가지 놀라운
메모리 최적화 기술에 대해 논의했습니다.
이번 포스팅에서 논의한 영역은
메모리 사용을 최적화하는 방법입니다.
용량이 크지 않은 데이터 분석에서는
중요성이 다소 떨어질 수 있지만,
대용량 데이터를 다룰 때에는
중요한 내용이기 작성해 보았습니다.