웹 스크래핑 배우기
웹 스크래핑은 마법과 같죠.
인터넷에는 무수히 많은 데이터가 있습니다.
기업은 가격을 비교하고,
고객을 이해하고, 경쟁하기 위해
인터넷에서 데이터를 수집합니다.
우리는 웹 스크래핑의 도움으로
인터넷에서 데이터를 스크래핑할 수 있습니다.
전제 조건:
데이터를 스크랩하려면
Python에 대한 기본 지식만 있으면 됩니다.
파이썬에 대한 기본 지식을 알고 있다고 가정하고
웹 스크래핑을 다뤄보겠습니다.
과제:
이름, 등급, 가격과 같이
Flipkart에 나열된 모든 노트북 세부 정보를
추출하여 비교하고 더 나은 거래를
하도록 도와드립니다.
1단계: 필요한 모든 라이브러리 다운로드
먼저 데이터 스크래핑에 필요한
모든 라이브러리를 다운로드해야 합니다.
BeautifulSoup:
Beautiful Soup은 HTML 및 XML 파일에서
데이터를 가져오기 위한 Python 라이브러리입니다.
pip install bs4

requests:
requests를 사용하면
HTTP/1.1 requests를 매우 쉽게 보낼 수 있습니다.
URL에 쿼리 문자열을 수동으로 추가하거나
POST 데이터를 형식 인코딩할 필요가 없습니다.
pip install requests
lxml:
lxml은 XML 및 HTML 파일을 쉽게 처리할 수 있는
Python 라이브러리이며 웹 스크래핑에도
사용할 수 있습니다.
이 라이브러리의 주요 이점은
사용이 간편하고 대용량 문서를 구문 분석할 때
매우 빠르고
문서화되어 있으며 데이터를 Python 데이터 유형으로
쉽게 변환할 수 있어 파일 조작이 더 쉽다는 것입니다.
pip install lxml
필요한 모든 라이브러리를 설치했습니다.
2단계: 라이브러리 가져오기
from bs4 import BeautifulSoup
import requests
3단계: 스크랩할 URL 가져오기
Flipkart로 이동하여 tv를 검색한 다음
URL을 복사합니다.
url = "https://www.flipkart.com/search?q=laptop&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off&page=1"
4단계: URL 가져오기 요청
r = requests.get(url)
r을 인쇄하면 응답 코드가 표시되고,
응답 코드가 200–299이면
스크랩할 웹 페이지의 HTML 파일을 가져올 수 있습니다.
r
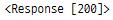
웹 페이지의 html 파일이나 콘텐츠를 가져오기 위해
콘텐츠 메서드를 사용합니다.
rContent = requests.get(url).content
5단계: BeautifulSoup 개체에서 HTML 파일 변환
BeautifulSoup 객체에서 HTML 파일을 변환하면
웹 스크래핑을 수행하고 필요한 모든 데이터를
매우 쉽게 스크래핑할 수 있습니다.
soup = BeautifulSoup(rContent,'lxml')
6단계: 모든 정보가 포함된 div 태그 긁기
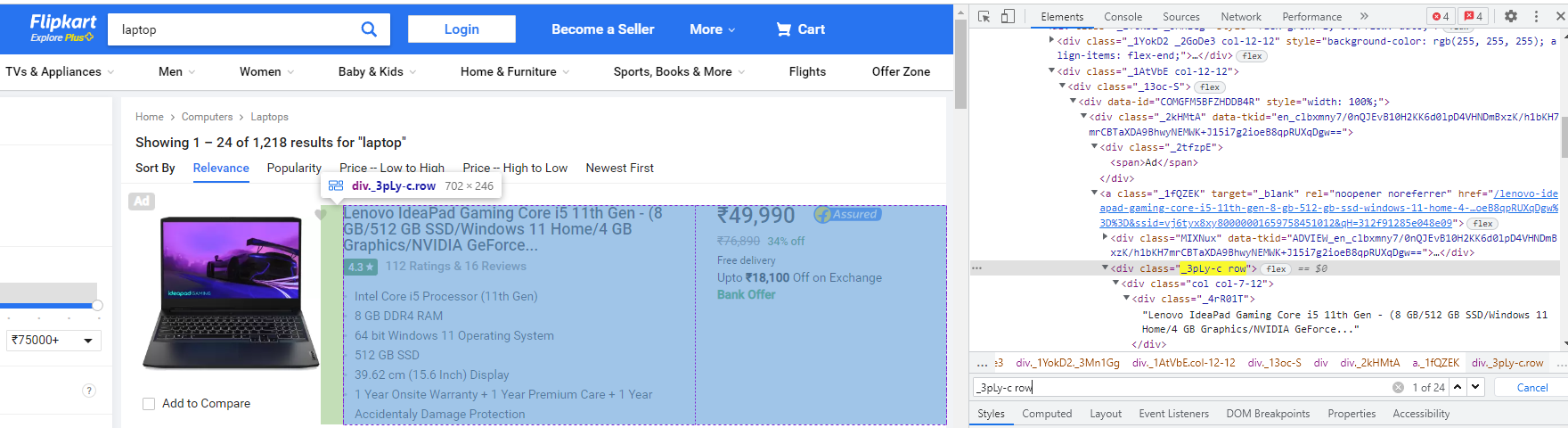
여기에서 class : _3pLy-c row를 사용하여
<div> 태그에서 긁어내고자 하는
모든 필요한 정보를 포함하는 태그를 지정할 수 있습니다.
전체 div 태그를 긁기 위해 find() 메서드를 사용합니다.
laptop = soup.find('div','_3pLy-c row')
7단계: laptop 이름 스크랩

name = laptop.find('div','_4rR01T')
name.text

8단계 : 스크랩 가격
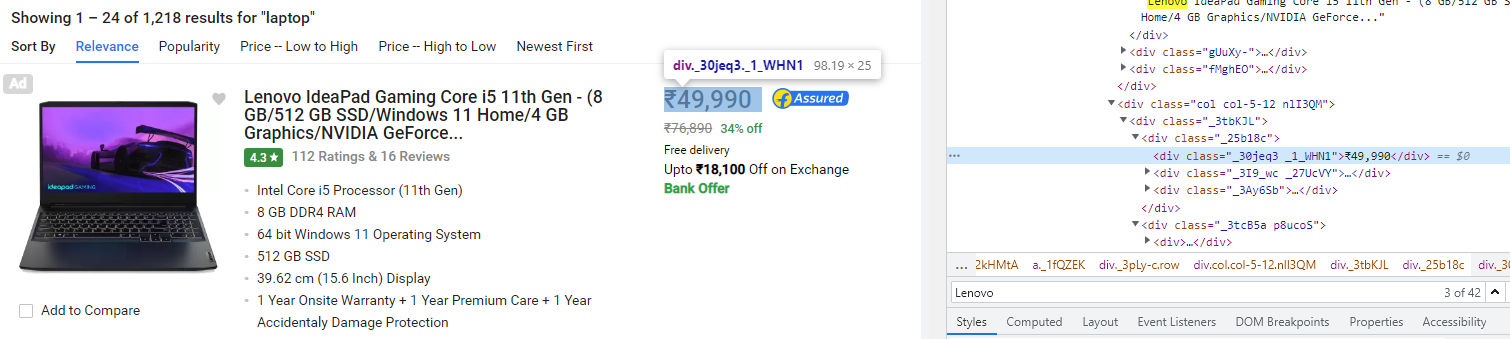
price = int(laptop.find('div','_30jeq3 _1_WHN1').text.replace('₹','').replace(',',''))
price
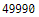
9단계 : 평점 스크래핑
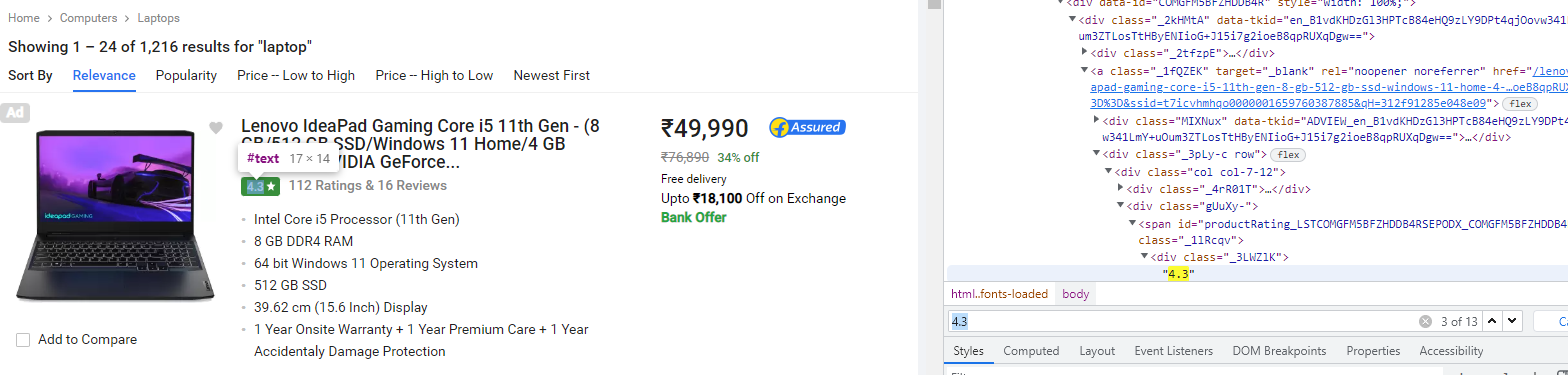
rating = float(soup.find('div','_3LWZlK').text)
rating
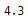
10단계: 모든 laptop의 세부 정보 스크래핑
find() 메서드를 사용하여 첫 번째 <div> 태그를 선택하고
단일 태그에서 데이터를 스크랩했습니다.
이제 find_all() 메서드를 사용하고
단일 페이지에서 모든 랩톱의 데이터를 스크랩합니다.
from bs4 import BeautifulSoup
import requests
url = "https://www.flipkart.com/search?q=laptop&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off&page=1"
r = requests.get(url).content
soup = BeautifulSoup(r,'lxml')
laptops = soup.find_all('div','_3pLy-c row')
for laptop in laptops:
name = laptop.find('div','_4rR01T').text
price = int(laptop.find('div','_30jeq3 _1_WHN1').text.replace('₹','').replace(',',''))
if laptop.find('div','_3LWZlK') == None :
rating = 0.0
else :
rating = float(laptop.find('div','_3LWZlK').text)
print('Name : ',name)
print('Price : ',price)
print('Rating : ',rating)

11단계: N 페이지에서 세부 정보 스크래핑하기
모든 페이지의 URL이 동일하다는 것을 알면
페이지 수만 증가시키는 루프를 사용하여
n개의 페이지에서 모든 데이터를 추출할 수 있습니다.
from bs4 import BeautifulSoup
import requests
import pandas as pd
# 페이지 수
n = 10
for page in range(1, n + 1):
url = f'https://www.flipkart.com/search?q=laptop&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off&page={page}'
r = requests.get(url).content
soup = BeautifulSoup(r,'lxml')
laptops = soup.find_all('div','_3pLy-c row')
for idx, laptop in enumerate(laptops):
name = laptop.find('div','_4rR01T').text
price = int(laptop.find('div','_30jeq3 _1_WHN1').text.replace('₹','').replace(',',''))
if laptop.find('div','_3LWZlK') == None :
rating = 0.0
else :
rating = float(laptop.find('div','_3LWZlK').text)
temp = pd.DataFrame([name, price, rating]).T
temp.columns = ["name","price","rating"]
if idx == 0 :
final = temp
else :
final = pd.concat([final, temp])
if page == 1:
totLabTopInfo = final
else:
totLabTopInfo = pd.concat([totLabTopInfo, final])
totLabTopInfo
