Box Plot (분포에서 이상값 감지 및 제거)
머신 러닝에서 특정 데이터 포인트는
다른 데이터 포인트에 비해
모델의 성능이 좋거나 혹은 나쁘게 만듭니다.
이러한 데이터 포인트는
더 자세히 조사하면 데이터 영역 측면에서
매우 비현실적인 경향을 보입니다.
이러한 데이터 포인트를 이상값이라고 하며
이번 포스팅에서는 데이터 세트에서
이상값을 시각화한 다음
감지하고 제거하는 방법을 살펴보겠습니다.
통계에서 이상치는 다른 관측치와
크게 다른 데이터 포인트입니다.
이러한 이상값 데이터 포인트는
실험 오류, 측정의 가변성, 문서 오류 등과 같은
다양한 요인으로 인해 발생할 수 있습니다.
다섯 수치 요약 및 상자 그림(Box Plot)
데이터 세트에서 이상값을 감지하는
가장 널리 사용되는 방법 중 하나는
상자 그림 시각화를 사용하는 것이며,
이 그림을 사용하여 사분위수 범위를 감지하고 제거합니다.
아래와 같은 데이터 분포가 있고
이상값을 감지하고 제거해야 한다고 가정해 보죠.
dataDistribution = [1, 2, 2, 2, 3, 3, 4, 5, 5, 5, 6, 6, 6, 6, 7, 8, 8, 9,27]
먼저 분포의 다섯 수치 요약을 찾아야 합니다.
다섯 수치 요약은
최소, 1사분위수, 중앙값, 3사분위수, 최댓값을 의미하고,
그 의미는 다음과 같습니다.
- 최소값: 분포의 최솟값을 나타냅니다.
이 예에서는 1입니다. - 1사분위수: 25백분위수라고도 합니다.
백분위수는 관측치의 특정 백분율이
그 아래에 있는 값입니다.
여기서 첫 번째 사분위수는 3이며,
이는 분포의 관측치 중 25%가
값3 아래에 있음을 의미합니다. - 중앙값: 중앙값은 정렬된 숫자 목록의 중간 숫자입니다.
이 예에서 중앙값은 6.5입니다. - 3사분위수: 75백분위수라고도 합니다.
여기서 3사분위수는 5이며,
이는 분포의 관측치 중 75%가
값 5 아래에 있음을 의미합니다. - 최댓값: 분포의 최댓값을 나타냅니다. 이 예에서는 27입니다.
코드를 사용하여 위의 다섯 수치 요약 값을 찾아보겠습니다.
import numpy as np
import pandas as pd
data = pd.DataFrame({'dataDistribution' : [1, 2, 2, 2, 3, 3, 4, 5, 5, 5, 6, 6, 6, 6, 7, 8, 8, 9,27]})
# 최소
minValue = data['dataDistribution'].min()
# 1사분위수, 3사분위수
q1, q3 = np.percentile(data['dataDistribution'], [25, 75])
# 중앙값
median = data['dataDistribution'].median()
# 최대
maxValue = data['dataDistribution'].max()
minValue, q1, median, q3, maxValue
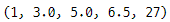
Box Plot
상자 그림은 중심 경향 측정값 중 하나를 포함하여
5자리 요약의 데이터를 표시하는 시각화 유형입니다.
상자 그림의 구성 요소는 다음과 같습니다.
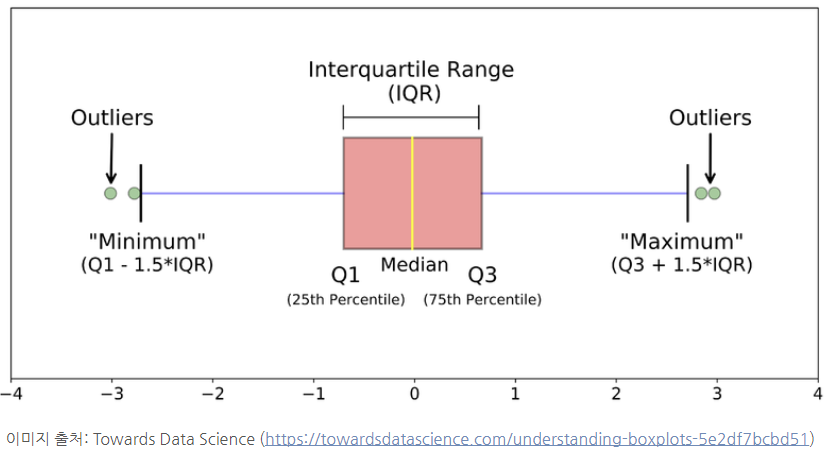
위의 상자 그림 정의에서 볼 수 있듯이 값
이 특정 기준을 넘어가면 이상값으로 정의합니다.
이제 분포를 시각화하고 해당 값들을
찾을 수 있는지 살펴보겠습니다.
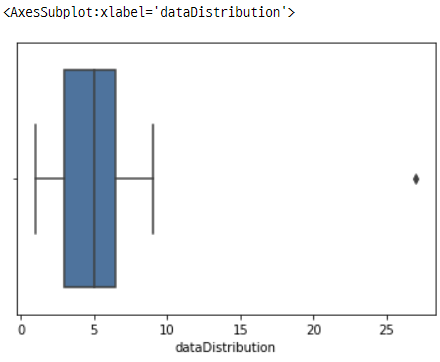
우리는 분포에서 이상값의 존재를 감지하고,
머신 러닝을 사용하여 예측 모델을 위해 학습하는 경우
모델에 영향을 줄 수 있으므로 이를 제거합니다.
사분위수 범위를 사용하여 이상값 제거
상위 사분위수와 하위 사분위수의 차이를
사분위수 간 범위라고 합니다. 다음과 같이 주어집니다.
Interquartile range(IQR) = Upper Quartile — Lower Quartile = Q3 — Q1
그런 다음 lower boundry와 upper boundry를 계산합니다.
이렇게 하면
데이터 포인트가 이상값 이하인 분포에서
가장 낮은 값을 제공하고
데이터 포인트가 이상값 이상인 가장 높은 값을 제공합니다.
lower_boundry = q1–1.5 * IQR
upper_boundry = q3 + 1.5 * IQR
그런 다음 데이터 포인트가
이상값을 벗어나는 범위를 얻습니다.
range = [lower_boundry, upper_boundry]
이것을 코드로 나타내면, 아래와 같습니다.
iqr = q3 - q1
lowBoundry = q1 - 1.5 * iqr
upperBoundry = q3 + 1.5 * iqr
Range = [lowBoundry, upperBoundry]
Range

이제 범위를 산출했으므로 값이 이상값인
이 범위를 벗어나는지 확인할 수 있습니다.
outlier = data[(data['dataDistribution'] < lowBoundry) | (data['dataDistribution'] > upperBoundry)]
outlier
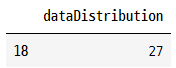
값 27이 이 분포에서 이상값임을 알 수 있으며,
동일한 값이 상자 그림 시각화에서도 나타납니다.
이제 이 이상값을 제거하기만 하면 됩니다.
finalData = data[(data['dataDistribution'] >= lowBoundry) | (data['dataDistribution'] <= upperBoundry)]
finalData.T

이상치를 성공적으로 제거했습니다.
결론
이상치는 거의 대부분의 실제 데이터 세트에 존재하며
적절하게 처리해야 합니다.
이번 포스팅에서는
이상값을 시각화하는 가장 효과적이고 간단한 방법
중 하나인 상자 그림(Box Plot)에 대해서
알아보았습니다.