Python의 Loop? NO! , Python의 Vectorization? OK!!!
소개
프로그래밍에서 루프는 매우 자연스럽고,
거의 모든 프로그래밍 언어로 루프에 대해 배웁니다.
기본적으로 반복 작업이 있을 때마다
루프를 사용합니다.
하지만 엄청나게 많은 수의
반복(수백만/수십억 행)으로 작업할 때
루프를 사용하는 것은 별로 좋은 방법이 아닙니다.
나중에 작동하지 않는다는 것을 깨닫기 위해
몇 시간 동안 갇혀있을 수 있습니다.
그렇기 때문에 파이썬에서는
벡터화를 구현하는 것이 매우 중요합니다.
벡터화(Vectorization)란?
벡터화는 데이터 세트에서
(NumPy) 배열 작업을 구현하는 기술입니다.
백그라운드에서 한 번에 하나의 행을 조작하는
'for' 루프와 달리 한 번에 배열(array) 또는 시리즈(Series)의
모든 요소에 작업을 적용합니다.
이번 포스팅에서는 파이썬 루프를
벡터화로 쉽게 대체할 수 있는
몇 가지 사용 사례를 살펴보겠습니다.
이렇게 하면 시간을 절약하고
코딩에 더 능숙해질 수 있습니다.
사용 사례 1: 숫자의 합 찾기
먼저 파이썬에서 루프와 벡터화를 사용하여
숫자의 합을 구하는 기본적인 예제를 살펴보겠습니다.
루프 사용 예
import time
start = time.time()
# for 루프를 활용한 합계 구하기
total = 0
for item in range(0, 60000):
total = total + item
print('sum is:' + str(total))
end = time.time()
print('소요 시간(초) :', end - start)

벡터화 사용
import numpy as np
start = time.time()
print(np.sum(np.arange(60000)))
end = time.time()
print('소요 시간(초) :', end - start)

벡터화 연산과 range 함수를 사용한 반복 연산을
비교해 볼 때, 약 8배 빠른 속도를 보여 주었습니다.
이 차이는 Pandas DataFrame으로
작업하는 동안 더욱 중요해집니다.
사용 사례 2: 수학 연산(DataFrame에서)
데이터 과학에서 Pandas DataFrame으로
작업하는 동안 개발자는 루프를 사용하고,
수학 연산을 사용하여 새로운 파생 열을 만듭니다.
다음 예에서는 이러한 사용 사례에서
루프를 벡터화로 얼마나 쉽게
변경할 수 있는지 확인할 수 있습니다.
데이터프레임 생성
DataFrame은 행과 열 형식의
테이블 형식 데이터입니다.
0에서 50 사이의 임의의 값으로 채워진
5백만 행과 4개의 열이 있는
pandas DataFrame을 만들겠습니다.
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(0, 50, size=(5000000, 4)), columns=('a','b','c','d'))
print(df.shape)
df.head()

열 'd'와 'c'의 비율을 찾기 위해 새 열 'ratio'을 만듭니다.
루프 사용
import time
start = time.time()
for idx, row in df.iterrows():
df.at[idx,'ratio'] = 100 * (row["d"] / row["c"])
end = time.time()
print(end - start)
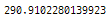
벡터화 사용
start = time.time()
df["ratio"] = 100 * (df["d"] / df["c"])
end = time.time()
print(end - start)
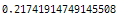
DataFrame에서 상당한 개선을 볼 수 있습니다.
벡터화 작업에 걸리는 시간은
Python의 루프에 비해 거의 1000배 더 빠릅니다.
사용 사례 3: If-else 문(DataFrame에서)
'If-else' 유형의 논리를 사용해야 하는
많은 코딩 작업이 있습니다.
이러한 논리를 파이썬의 벡터화 작업으로
쉽게 대체할 수 있습니다.
다음 예를 살펴보겠습니다
(사용 사례 2에서 생성한 DataFrame을 사용합니다).
기존 열 'a'의 일부 조건을 기반으로
새 열 'e'를 만들고 싶다고 가정합니다.
루프 사용
import time
start = time.time()
for idx, row in df.iterrows():
if row.a == 0:
df.at[idx,'e'] = row.d
elif (row.a <= 25) & (row.a > 0):
df.at[idx,'e'] = (row.b)-(row.c)
else:
df.at[idx,'e'] = row.b + row.c
end = time.time()
print('소요 시간(초): ', end - start)
벡터화 사용
벡터화 작업에 소요되는 시간은 if-else 문이 있는
파이썬 루프에 비해 600배 더 빠릅니다.
사용 사례 4(고급): 머신 러닝/딥 러닝 네트워크 해결
딥 러닝을 사용하려면 수백만, 수십억 행에 대해
여러 복잡한 방정식을 풀어야 합니다.
이러한 방정식을 풀기 위해
파이썬에서 루프를 실행하는 것은
매우 느리기 때문에 벡터화가 최적의 솔루션입니다.
예를 들어 다음과 같은 다중 선형 회귀 방정식에서
수백만 행에 대한 y 값을 계산하려면
다음과 같이 수행하세요.
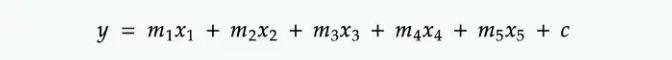
루프를 벡터화로 대체할 수 있습니다.
m1,m2,m3…의 값은 x1,x2,x3…에 해당하는
수백만 개의 값을 사용하여
위의 방정식을 풀면 결정됩니다.
(단순화를 위해 간단한 곱셈 단계만 살펴보겠습니다).
데이터 생성
import numpy as np
# 0과 1 사이의 1 by 5 배열의 난수 생성
m = np.random.rand(1,5)
m
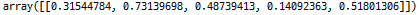
# input values for 5 million rows
x = np.random.rand(5000000,5)
x

루프 사용
import numpy as np
import time
m = np.random.rand(1,5)
x = np.random.rand(5000000,5)
total = 0
tic = time.process_time()
zer = np.repeat(0,5000000)
for i in range(0,5000000):
total = 0
for j in range(0,5):
total = total + x[i][j]*m[0][j]
zer[i] = total
toc = time.process_time()
print ("Computation time = " + str((toc - tic)) + "seconds")
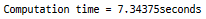
벡터화 사용
tic = time.process_time()
# 행렬 곱
np.dot(x,m.T)
toc = time.process_time()
print ("Computation time = " + str((toc - tic)) + "seconds")
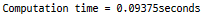
np.dot는 백엔드에서 벡터화된 행렬 곱셈을 구현합니다.
파이썬의 루프에 비해 약 73배 빠릅니다.
결론
Python의 벡터화는 매우 빠르기 때문에
매우 큰 데이터를 다룰 때는
루프 대신 벡터화를 주로 사용해야 합니다.
처음에는 익숙하지 않을 수도 있지만,
시간이 지남에 따라 구현을 시작하면
벡터화 방식으로 생각하는 데 익숙해질 것입니다.