Python 프로그래머가 저지르는 20가지 초보자 실수
Python으로 코딩하는 동안 피해야 할 일반적인 실수 모음
프로그래밍(Python뿐만 아니라 모든 프로그래밍 언어)의
가장 좋은 점은 동일한 로직을 구현하는 방법이 다양하다
는 것입니다.
한 가지 방법만 있다는 것이 아니죠.
다음과 같은 다양한 이유로
상황에 따라서 조금 더 효율적인 프로그래밍 코드가
존재할 수 있어요.
- 적은 메모리 사용량
- 런타임 효율성
- 더 적은 코드 라인
- 이해하기 쉬운 간단한 논리 등
이번 포스팅에서는 Python 프로그래머가 자신도 모르게
복잡한 Python 코드를 작성하는 함정에 빠지는
20가지 특정 상황을 소개하고자 합니다.
그렇게 되면, 결국 Python의 진정한 잠재력을
발휘하지 못하게 합니다.
이와 함께 이러한 실수를 수정하는 데 도움이 되는
코드도 제공하고자 합니다.
서로 비교해 보시면, Python으로 프로그래밍 실력을
향상시키는데에 많은 도움이 될 것이라고 확신합니다.
그럼 이제 시작해 볼까요!!!!
#1 여러 개의 Print 문 사용
일반적 접근
여러 변수를 출력하려는 경우
일반적 접근 방식은 각 변수를
각각의 print() 문으로 가져오는 것입니다.
a, b, c = 10, 5, 3
print(a)
print(b)
print(c)
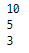
세련된 접근
여러 개의 print 문을 사용하는 것은
일반적으로 초보자가
파이썬으로 코딩하는 동안 저지르는
가장 흔한 실수입니다.
print()를 사용하면 다음과 같이
단일 print 문에 여러 변수를
출력할 수 있습니다.
a, b, c = 10, 5, 3
print(a, b, c, sep = "\n")
위의 sep 인수는
동일한 print 문(위의 a, b 및 c)을 사용하여
출력된 다양한 변수 사이의
구분 기호를 지정합니다.
참고로 end 인수는
print 문의 종료 문자를 지정하는 데
사용됩니다.
a, b, c = 10, 5, 3
print(a, end = "\n---\n")
print(b, end = "\n---\n")
print(c)
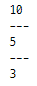
위의 코드에서 end='\n---\n' 매개변수는
개행 문자, --- 및 추가 개행 문자를 출력합니다.
#2 FOR 루프를 사용하여 같은 변수 출력하기
일반적 접근
제목에서 알 수 있듯이
목표는 동일한 변수를
여러 번 출력하는 것입니다.
물론 FOR 루프를 만들고
변수를 출력하고 싶은 횟수만큼
반복하면 됩니다.
repeat = 10
a = "ABC"
for _ in range(repeat):
print(a, end = "")
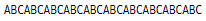
세련된 접근
FOR 루프를 작성해도 문제가 없고
모든 것이 잘 작동하지만
동일한 변수를 여러 번 출력하기 위해
FOR 루프를 작성할 필요는 없습니다.
repeat = 10
a = "ABC"
print(a*repeat)
#3–4 루프에서 인덱스를 추적하기 위해 별도의 변수 만들기
일반적 접근 - 1
일반적으로 아래와 같이
인덱스 값을 추적하고
반복할 때마다 값을 증가시키는
새 변수(idx)를 정의합니다.
idx = 0
charList = ["a", "b", "c", "d", "e", "f"]
for i in charList:
print("index =", idx, "value =", i, sep = " ")
idx += 1
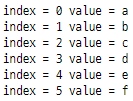
일반적 접근 - 2
다른 일반적 접근은
아래 코드와 같이
인덱스를 추적하기 위해
범위 반복자를 만들 것입니다.
charList = ["a", "b", "c", "d", "e", "f"]
for idx in range(len(charList)):
print("index =", idx, "value =", charList[idx], sep = " ")
idx += 1
세련된 접근
enumerate() 메서드를 사용하는 것입니다!!
기본적으로 이 방법을 사용하면
다음과 같이 인덱스(idx)와 값(i)을
모두 추적할 수 있습니다.
charList = ["a", "b", "c", "d", "e", "f"]
for idx, i in enumerate(charList):
print("index =", idx, "value =", i, sep = " ")
#5 FOR 루프를 사용하여 리스트를 문자열로 변환(ex. A,B,C,D,E -> ABCDE)
일반적 접근
아래와 같이 FOR 루프를 사용하여
리스트의 요소를 한 번에 하나씩
수집할 수 있습니다.
charList = ["A", "B", "C", "D", "E"]
finalStr = ""
for i in charList:
finalStr += i
print(finalStr)

세련된 접근
리스트를 문자열로 변환하는 세련된 방법은
아래와 같이 join() 메서드를 사용하는 것입니다.
charList = ["A", "B", "C", "D", "E"]
finalStr = "".join(charList)
print(finalStr)

이렇게 하면 불필요하게 긴 코드를
작성하지 않아도 될 뿐만 아니라
for 루프 접근 방식만큼 직관적입니다.
#6 FOR 루프를 사용하여 리스트에서 중복 제거(ex. A,B,A,C,D,E -> A,B,C,D,E)
일반적 접근
구조를 위한 FOR-루프를 다시 한 번!
일반적 접근 방식은 입력 리스트를 반복하고
고유한 요소를 새 리스트에 저장하는 것입니다.
charList = ["A", "B", "A", "D", "C", "B", "E"]
finalList = []
for i in charList:
if i not in finalList:
finalList.append(i)
print(finalList)
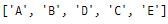
세련된 접근
그러나 아래와 같이
Python 코드 한 줄로 리스트에서
중복 항목을 제거할 수 있습니다.
charList = ["A", "B", "A", "D", "C", "B", "E"]
set(charList)

위는 set 형식을 반환하면서
다음과 같이 리스트 형태로 다시 반환할 수 있습니다.
charList = ["A", "B", "A", "D", "C", "B", "E"]
list(set(charList))
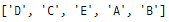
#7 FOR 루프를 사용하여 목록에서 요소 검색
일반적 접근
요소가 리스트(또는 집합)에 있는지 여부를
부울 응답으로 반환한다고 가정해 보겠습니다.
charList = ["A", "B", "A", "D", "C", "B", "E"]
searchChar = "D"
found = False
for i in charList:
if i == searchChar:
found = True
break
print(found)

세련된 접근
in 키워드를 사용하여
한 줄로 구현해 보겠습니다.
charList = ["A", "B", "A", "D", "C", "B", "E"]
searchChar = "D"
searchChar in charList

#8 인덱스 변수를 사용하여 동일한 크기의 두 iterable 반복
#3-4에서 수행한 것과 유사하게,
즉 인덱스에 대해 특별히 변수를 정의하는 것입니다.
일반적 접근
여기서 일반적인 방법은 아래와 같이
동일한 것을 채택하는 것입니다.
list1 = [1, 3, 6, 2, 5]
list2 = [0, 4, 1, 9, 7]
for idx in range(len(list1)):
print("value1 =", list1[idx], "value2 =", list2[idx], sep = " ")
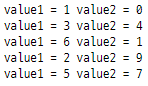
세련된 접근
zip() 함수를 사용하는 것입니다.
두 개의 iterables에서 해당 값을 쌍으로 지정합니다.
list1 = [1, 3, 6, 2, 5]
list2 = [0, 4, 1, 9, 7]
for i, j in zip(list1, list2):
print("value1 =", i, "value2 =", j, sep = " ")

#9 FOR 루프를 사용하여 리스트 요소 뒤집기(ex. 1,2,3,4,5 -> 5,4,3,2,1)
일반적 접근
아래와 같이 리스트를 역순으로 반복하고
새 리스트에 요소를 추가할 수 있습니다.
inputList = [1, 2, 3, 4, 5]
outputLlist = []
for idx in range(len(inputList), 0, -1):
outputLlist.append(inputList[idx-1])
print(outputLlist)

세련된 접근
Python의 슬라이싱을 이해한다면
간단히 한 줄로 코딩이 가능합니다.
inputList = [1, 2, 3, 4, 5]
outputLlist = inputList[::-1]
print(outputLlist)
#10 FOR 루프를 사용하여 Palindrome 확인하기
일반적 접근
위의 상황(#9 — 목록 반전)에 대한 아이디어를 확장하면
반전된 리스트가 입력 리스트와 동일한지 확인할 수 있습니다.
inputList = [1, 2, 3, 2, 1]
outputLlist = []
for idx in range(len(inputList), 0, -1):
outputLlist.append(inputList[idx-1])
print(outputLlist == inputList)

세련된 접근
위에서 논의한 세련된 접근 방식은
슬라이싱을 사용하고 입력 리스트와 비교하는 것입니다.
inputList = [1, 2, 3, 2, 1]
outputLlist = inputList[::-1]
print(outputLlist == inputList)
#11 FOR 루프를 사용하여 iterable에서 요소의 발생 횟수 세기
일반적 접근
요소의 빈도를 찾는 일반적 접근 방식은
FOR 루프를 사용하여 리스트를 반복하고
발생 횟수를 세는 것입니다.
charList = ["A", "B", "A", "D", "C", "B", "E"]
searchChar = "B"
charCount = 0
for i in charList:
if searchChar == i:
charCount += 1
print(charCount)
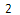
세련된 접근
이 경우 FOR 루프를 작성하지 않아도 되는
세련된 접근 방식은 count() 메서드를
사용하는 것입니다.
charList = ["A", "B", "A", "D", "C", "B", "E"]
charList.count("A")
문자열 입력에도
count() 메서드를 사용할 수 있습니다.
string = "ABADCBE"
string.count("A")
#12 FOR 루프를 사용하여 문자열의 하위 문자열 얻기
일반적 접근
startIndex 위치에서 시작하여
길이가 nChars인 하위 문자열을
반환하는 상황을 가정해 보겠습니다.
이 문제에 대한 초보자의 접근 방식은
아래와 같이 FOR 루프를 사용하는 것입니다.
inputStr = "ABCDEFGHIJKL"
startIndex = 4
nChars = 5
outputStr = ""
for i in range(nChars):
outputStr += inputStr[i+startIndex]
print(outputStr)

세련된 접근
그러나 한 줄짜리 접근 방식은
슬라이싱을 사용하는 것이므로
FOR 루프를 작성하지 않아도 됩니다.
inputStr = "ABCDEFGHIJKL"
startIndex = 4
nChars = 5
outputStr = inputStr[startIndex:startIndex+nChars]
print(outputStr)
#13 긴 정수 상수 정의하기
값이 10²¹인 정수 변수를 선언한다고 가정해 볼까요?
일반적 접근
x = 1000000000000000000000
x

연속해서 0을 쓰고 입력하는 대로 계산합니다.
만약 다른 사람이 이 코드를
참조하고 싶어 한다면 어떨까요?
0이 몇 개인지 일일이 세어봐야 하는 상황이 벌어집니다.
세련된 접근
가독성을 높이기 위해
아래와 같이 _(밑줄)로 0 그룹을
구분할 수 있습니다.
x = 1_000_000_000_000_000_000_000
x
하지만 여전히 번거로워 보입니다.
여전히 0을 세어야 하네요.
숫자를 a^b 형식으로 표현할 수 있으면
pow() 메서드를 사용하면 좋을 거 같아요.
x = pow(10, 21)
x
#14 IF 조건으로 문자열의 대소문자 바꾸기
일반적 접근
일반적 접근 방식은
모든 요소의 사례를 확인한 다음
각 사례에 대한 특정 조건을 갖는 것입니다.
inputStr = "AbCDeFGhIjkl"
outputStr = ""
for i in inputStr:
if i.islower():
outputStr += i.upper()
elif i.isupper():
outputStr += i.lower()
else:
outputStr += i
print(outputStr)
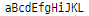
출력에는 아무 문제가 없습니다.
세련된 접근
swapcase() 메서드 사용!
inputStr = "AbCDeFGhIjkl"
outputStr = inputStr.swapcase()
print(outputStr)
#15 두 집합의 합집합 구하기
일반적 접근
두 집합을 반복하고 새 집합에 요소를 추가합니다.
setA = {1, 2, 4, 8}
setB = {3, 8, 7, 1, 9}
unionSet = set()
for i in setA:
unionSet.add(i)
for i in setB:
unionSet.add(i)
print(unionSet)
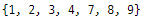
코드가 너무 많죠? 한 줄로 줄이겠습니다.
세련된 접근
Python의 집합 데이터 구조는
두 집합의 합집합에 union() 메서드를 제공합니다.
setA = {1, 2, 4, 8}
setB = {3, 8, 7, 1, 9}
unionSet = setA.union(setB)
print(unionSet)
원하는 수의 입력 세트로 확장도 가능합니다.
setA = {1, 2, 4, 8}
setB = {3, 8, 7, 1, 9}
setC = {5, 9, 10, 3, 2}
setD = {7, 2, 13, 15, 0}
unionSet = setA.union(setB, setC, setD)
print(unionSet)

#16 두 집합의 교집합 구하기
일반적 접근
위에서 논의한 케이스와 유사하게
다음과 같이 두 세트 사이의
공통 요소를 찾을 수 있습니다.
setA = {1, 2, 4, 8}
setB = {3, 8, 7, 1, 9}
intersectionSet = set()
for i in setA:
if i in setB:
intersectionSet.add(i)
print(intersectionSet)

세련된 접근
Intersection() 메서드를 사용하여
동일한 결과를 얻을 수 있습니다.
setA = {1, 2, 4, 8}
setB = {3, 8, 7, 1, 9}
intersectionSet = setA.intersection(setB)
print(intersectionSet)
#17 IF 문에 여러 조건 쓰기
이에 대해 자세히 설명하기 위해
다음 로직을 구현한다고 가정해 보겠습니다.
입력은 정수 a입니다.
일반적 접근
여기에서 위의 논리를 구현하기 위해
여러 OR 분리 조건을 사용합니다.
a = 1
if a == 1 or a == 2 or a==3:
a += 1
elif a == 4 or a == 5 or a==6:
a += 5
else:
a *= 2
print(a)

세련된 접근
여러 조건문을 피하는 방법은
in 키워드를 사용하는 것입니다.
a = 1
if a in (1, 2, 3):
a += 1
elif a in (4, 5, 6):
a += 5
else:
a *= 2
print(a)
#18 목록에 있는 모든 요소의 데이터 유형 변경하기
정수를 나타내는 문자열 리스트가 주어지면
데이터 유형을 변경하여
문자열을 정수 리스트로 변환하는 것입니다.
일반적 접근
FOR 루프를 사용하여 리스트를 반복하고
개별 요소를 유형 변환합니다.
inputList = ["7", "2", "13", "15", "0"]
outputList = []
for idx, i in enumerate(inputList):
outputList.append(int(inputList[idx]))
print(outputList)
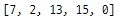
세련된 접근
아래와 같이 map()을 사용하는 것입니다.
inputList = ["7", "2", "13", "15", "0"]
outputList = list(map(int, inputList))
print(outputList)
첫 번째 인수로 map() 메서드는
함수(int)를 허용하고,
두 번째 인수는 iterable(inputList)입니다.
#19 변수 교환
두 개의 변수가 주어지면 목표는
첫 번째 변수의 값을 두 번째 변수로,
두 번째 변수의 값을 첫 번째 변수로 전달하는 것입니다.
일반적 접근
대부분의 C/C++ 프로그래머가 취하는 접근 방식은
새 변수(temp)를 정의하는 것이며
일반적으로 Python에서도 가능합니다.
a = "123"
b = "abc"
temp = a
a = b
b = temp
print(a, b)
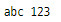
세련된 접근
Python은 단일 명령문에서
여러 할당을 허용하므로
임시 변수가 필요하지 않습니다.
a = "123"
b = "abc"
a, b = b, a
print(a, b)
#20 중첩 루프를 사용하여 두 목록의 모든 조합 생성
두 리스트(길이가 n인 a와 길이가 m인 b)가 주어지면
모든 n*m 조합을 생성합니다.
일반적 접근
두 개의 중첩된 FOR 루프를 작성하고
모든 조합을 리스트에 추가합니다.
list1 = ["A", "B", "C"]
list2 = [1, 2]
combinations = []
for i in list1:
for j in list2:
combinations.append([i, j])
print(combinations)

세련된 접근
아래와 같이 itertools 라이브러리의
product() 메서드를 사용하는 것입니다.
from itertools import product
list1 = ["A", "B", "C"]
list2 = [1, 2]
combinations = list(product(list1, list2))
print(combinations)
결론
이번 포스팅에서는
대부분의 Python 프로그래머가 겪었고
코딩에 대해 비효율적인 접근 방식을
취했을 수 있다고 생각하는 20가지 시나리오를
시연했습니다.
대부분의 상황에서 세련된 접근 방식은 주로
이전 접근 방식에서 사용된
FOR 루프의 명시적 코딩을
제거하는 데 중점을 둡니다.
이번 포스팅에서 중요한 점은
대부분의 경우 가장 먼저 떠오르는 방법이
이상적인 접근 방식이 아니라는 점을
항상 기억해야 한다는 것입니다.