1. ddply() 함수: plyr 패키지가 필요하지만 사용하기 가장 쉬워요. 2. summaryBy() 함수: doBy 패키지가 필요하지만 사용하기가 쉬운 편이에요. 3. aggregate() 함수: 사용하기가 어려운 편이지만, R의 base에 포함되어 있어요.
어떤 데이터가 존재하고, 각 그룹에 대한 N(수), 변화 평균, 표준 편차 및 표준 오차를 찾고자 한다고 가정해 보죠.
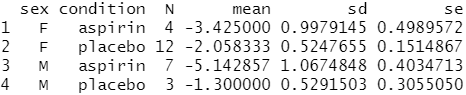
여기서 그룹은 성별과 조건의 각 조합(F-placebo,F-aspirin,M-placebo, andM-aspirin)으로 지정된다고 가정해요.
data <- read.table(header=TRUE, text=' subject sex condition before after change 1 F placebo 10.1 6.9 -3.2 2 F placebo 6.3 4.2 -2.1 3 M aspirin 12.4 6.3 -6.1 4 F placebo 8.1 6.1 -2.0 5 M aspirin 15.2 9.9 -5.3 6 F aspirin 10.9 7.0 -3.9 7 F aspirin 11.6 8.5 -3.1 8 M aspirin 9.5 3.0 -6.5 9 F placebo 11.5 9.0 -2.5 10 M placebo 11.9 11.0 -0.9 11 F aspirin 11.4 8.0 -3.4 12 M aspirin 10.0 4.4 -5.6 13 M aspirin 12.5 5.4 -7.1 14 M placebo 10.6 10.6 0.0 15 M aspirin 9.1 4.3 -4.8 16 F placebo 12.1 10.2 -1.9 17 F placebo 11.0 8.8 -2.2 18 F placebo 11.9 10.2 -1.7 19 M aspirin 9.1 3.6 -5.5 20 M placebo 13.5 12.4 -1.1 21 M aspirin 12.0 7.5 -4.5 22 F placebo 9.1 7.6 -1.5 23 M placebo 9.9 8.0 -1.9 24 F placebo 7.6 5.2 -2.4 25 F placebo 11.8 9.7 -2.1 26 F placebo 11.8 10.7 -1.1 27 F aspirin 10.1 7.9 -2.2 28 M aspirin 11.6 8.3 -3.3 29 F aspirin 11.3 6.8 -4.5 30 F placebo 10.3 8.3 -2.0 ')
ddply 사용
library(plyr) # plyr 패키지 로드
# 성별 + 상태로 분류된 각 그룹의 "change" 값에 대해 length, mean 및 sd 함수 실행 cdata <- ddply(data, c("sex", "condition"), summarise, N = length(change), mean = mean(change), sd = sd(change), se = sd / sqrt(N) ) cdata
<누락된 데이터 처리>
데이터에 NA가 있는 경우 각 함수에 na.rm=TRUE 플래그를 전달해야 해요.
length()는 na.rm을 옵션으로 사용하지 않으므로
이 문제를 해결하는 한 가지 방법은
sum(!is.na(...))을 사용하여 NA가 아닌 항목이 얼마나 있는지를 계산하면 돼요.
# 몇 개의 데이터를 임의로 NA 세팅 dataNA <- data dataNA$change[11:14] <- NA
cdata <- ddply(dataNA, c("sex", "condition"), summarise, N = sum(!is.na(change)), mean = mean(change, na.rm=TRUE), sd = sd(change, na.rm=TRUE), se = sd / sqrt(N) ) cdata
<평균, 개수, 표준 편차, 평균의 표준 오차 및 신뢰 구간에 대한 함수>
위에 표시된 것처럼 원하는 모든 값을 수동으로 지정한 다음 표준 오차를 계산하는 대신
이 함수는 아래에 설명된 이러한 모든 세부 사항을 처리할 수 있어요.
1. 평균, 표준 편차 및 개수 찾기(N)
2. 평균의 표준 오차 찾기
3. 95% 신뢰 구간(또는 원하는 경우 다른 값) 찾기
4. 결과 데이터 프레임이 더 쉽게 작업할 수 있도록 열 이름 변경
사용하려면 이 함수를 코드에 넣고 아래와 같이 호출하면 돼요.
## 데이터 요약 ## 개수, 평균, 표준 편차, 평균의 표준 오차 및 신뢰 구간(기본값 95%) 제공 ## data: 데이터 프레임 ## measurevar: 요약할 변수를 포함하는 열의 이름 ## groupvars: 그룹화 변수를 포함하는 열의 이름을 포함하는 벡터 ## na.rm: NA를 무시할지 여부를 나타내는 부울 ## conf.interval: 신뢰 구간의 백분율 범위(기본값은 95%) summarySE <- function(data=NULL, measurevar, groupvars=NULL, na.rm=FALSE, conf.interval=.95, .drop=TRUE) { library(plyr)
# NA를 처리할 수 있는 length의 새 버전: na.rm==T인 경우 계산 X length2 <- function (x, na.rm=FALSE) { if (na.rm) sum(!is.na(x)) else length(x) }
# 요약 수행: 각 그룹의 데이터 프레임에 대해 N, mean 및 sd가 있는 벡터 반환 datac <- ddply(data, groupvars, .drop=.drop, .fun = function(xx, col) { c(N = length2(xx[[col]], na.rm=na.rm), mean = mean(xx[[col]], na.rm=na.rm), sd = sd(xx[[col]], na.rm=na.rm) ) }, measurevar )
# "mean" 칼럼명 변경 datac <- rename(datac, c("mean" = measurevar))
datac$se <- datac$sd / sqrt(datac$N) # 평균의 표준 오차 계산
# 표준 오차에 대한 신뢰 구간 승수 # 신뢰 구간에 대한 t-통계량 계산: # e.g., conf.interval이 .95이면 .975(위/아래)를 사용하고 df=N-1을 사용합니다. ciMult <- qt(conf.interval/2 + .5, datac$N-1) datac$ci <- datac$se * ciMult
return(datac) }
사용 예(95% 신뢰 구간 포함).
이전에 수행한 것처럼 모든 단계를 수동으로 수행하는 대신
summarySE 함수는 모든 작업을 한 단계로 끝내 버려요.
summarySE(data, measurevar="change", groupvars=c("sex","condition"))
# NA가 있는 데이터 세트의 경우 na.rm=TRUE 사용 summarySE(dataNA, measurevar="change", groupvars=c("sex","condition"), na.rm=TRUE)
<빈 조합을 0으로 채우기>
때때로 요약 데이터 프레임에 빈 요소 조합이 있을 수 있어요.
즉, 이론적으로 가능하지만 원래 데이터 프레임에서 실제로 발생하지 않는 factor 조합이라고 할 수 있죠.
NA로 요약 데이터 프레임의 해당 조합을 자동으로 채우는 것이 종종 유용할 때가 있어요.
이렇게 하려면 ddply 또는 summarySE에 대한 호출에서 .drop=FALSE를 설정하시면 돼요.
# 데이터를 요약하면 이 조합에 사례가 없었기 때문에 Male+Placebo에 대해 누락된 행 존재 summarySE(dataSub, measurevar="change", groupvars=c("sex", "condition")) # .drop=FALSE를 설정하여 해당 조합 삭제 방지 summarySE(dataSub, measurevar="change", groupvars=c("sex", "condition"), .drop=FALSE)
summaryBy 사용
summaryBy() 함수를 사용하여 데이터를 요약하려면,
library(doBy)
# 각 그룹의 "change" 값에 대해 length, mean 및 sd 함수를 # sex + condition으로 분류하여 실행 cdata <- summaryBy(change ~ sex + condition, data=data, FUN=c(length,mean,sd)) cdata # 변수명 변경: change.length을 N으로 names(cdata)[names(cdata)=="change.length"] <- "N"
# 평균의 표준 오차 계산 cdata$change.se <- cdata$change.sd / sqrt(cdata$N) cdata
개체 내 변수가 있는 경우 이러한 표준 오류 값은 그룹을 비교하는 데 유용하지 않을 수 있어요. 개체 내 변수가 있는 그래프의 오차 막대를 생성하여 그래프로 표현하는 것이 더 효과적이에요.
방법에 대한 정보는 제 블로그 "ggplot2을 활용한 R 그래픽" 카테고리를 참고하세요.
<누락된 데이터 처리>
데이터에 NA가 있으면 na.rm=TRUE 플래그를 함수에 전달하는 것이 필요해요.
당연히, summaryBy()에도 전달할 수 있으며 호출된 각 함수에 전달되지만,
length()는 이를 인식하지 못하므로 작동하지 않아요.
이를 해결하려면 NA를 처리하는 새로운 길이 함수를 정의하시면 돼요.
# NA를 처리할 수 있는 길이의 새 버전: na.rm==T인 경우 계산 X length2 <- function (x, na.rm=FALSE) { if (na.rm) sum(!is.na(x)) else length(x) }
# 데이터에 일부 NA를 삽입 dataNA <- data dataNA$change[11:14] <- NA
아래에서 정의한 함수는 이러한 모든 세부 사항을 처리하였고, 아래에서 설명된 모든 작업을 수행합니다.
1. 평균, 표준 편차 및 개수 찾기(N)
2. 평균의 표준 오차 찾기
3. 95% 신뢰 구간(또는 원하는 경우 다른 값) 찾기
4. 결과 데이터 프레임이 더 쉽게 작업할 수 있도록 열 이름 변경
실제 데이터 분석에서 사용하시려면 아래 함수를 코드에 넣고 아래와 같이 호출하시면 돼요.
## 데이터 요약 ## 개수, 평균, 표준 편차, 평균의 표준 오차 ## 신뢰 구간(기본값 95%) 제공 ## data: 데이터 프레임 ## measurevar: 요약할 변수를 포함하는 열 이름 ## groupvars: 그룹화 변수를 포함하는 열 이름을 포함하는 벡터 ## na.rm: NA를 무시할지 여부를 나타내는 부울 ## conf.interval: 신뢰 구간의 백분율 범위(기본값은 95%)
datac$se <- datac$sd / sqrt(datac$N) # 평균의 표준 오차 계산
# 표준 오차에 대한 신뢰 구간 승수 # 신뢰 구간에 대한 t-통계량 계산: # 예를 들어 conf.interval이 .95이면 .975(위/아래)를 사용하고 df=N-1을 사용 ciMult <- qt(conf.interval/2 + .5, datac$N-1) datac$ci <- datac$se * ciMult
return(datac) }
사용 예(95% 신뢰 구간 포함).
이전에 수행한 것처럼 모든 단계를 수동으로 수행하는 대신
summarySE 함수는 한 단계에서 모든 작업을 수행할 수 있는 것을 확인할 수 있어요.
summarySE(data, measurevar="change", groupvars=c("sex","condition")) # NA가 있는 데이터 세트의 경우 na.rm=TRUE 사용 summarySE(dataNA, measurevar="change", groupvars=c("sex","condition"), na.rm=TRUE)
<빈 조합을 0으로 채우기>
때때로 요약 데이터 프레임에 빈 요소의 조합이 있을 수 있어요.
즉, 가능하지만 원래 데이터 프레임에서 실제로 발생하지 않는 요소 조합인 거죠.
요약 데이터 프레임에서 이러한 조합을 자동으로 0으로 채우는 것이 종종 유용할 때가 있어요.
# 데이터를 요약하면 이 조합에 사례가 없었기 때문에 Male+Placebo에 대해 누락된 행 존재 cdataSub <- summarySE(dataSub, measurevar="change", groupvars=c("sex", "condition")) cdataSub # 누락된 조합을 0으로 채우기 fillMissingCombs(cdataSub, factors=c("sex","condition"), measures=c("N","change","sd","se","ci"))
aggregate 사용
aggregate 함수는 사용하기가 더 어렵지만 R base에 포함되어 있기 때문에,
별도 패키지를 설치할 필요가 없어요.
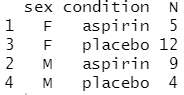
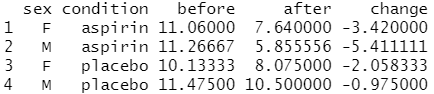
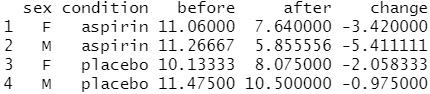
# 각 범주(sex*condition)의 subject 수 계산 cdata <- aggregate(data["subject"], by=data[c("sex","condition")], FUN=length) cdata # "subject" 열의 이름을 "N"으로 변경 names(cdata)[names(cdata)=="subject"] <- "N" cdata # sex로 정렬 cdata <- cdata[order(cdata$sex),] cdata # __before__ 및 __after__ 열 유지 # sex 및 condition별 평균 효과 크기 구하기 cdata.means <- aggregate(data[c("before","after","change")], by = data[c("sex","condition")], FUN=mean) cdata.means # 데이터 프레임 결합 cdata <- merge(cdata, cdata.means) cdata
# "change"에 대한 샘플(n-1) 표준 편차 구하기 cdata.sd <- aggregate(data["change"], by = data[c("sex","condition")], FUN=sd)
# 열 이름을 "change" 에서 "change.sd"로 변경 names(cdata.sd)[names(cdata.sd)=="change"] <- "change.sd" cdata.sd # 결합 cdata <- merge(cdata, cdata.sd) cdata # 평균의 표준 오차 계산 cdata$change.se <- cdata$change.sd / sqrt(cdata$N) cdata
데이터에 NA가 있고 이를 무시하려면, na.rm=TRUE를 사용하시면 돼요.
cdata.means <- aggregate(data[c("before","after","change")], by = data[c("sex","condition")], FUN=mean, na.rm=TRUE)





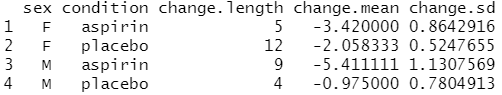

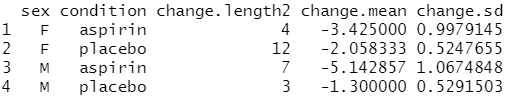













댓글