K-S통계량은 신용평가 모형의 주요 성능 검증 지표 중의 하나입니다. 해당 통계량이 신용평가 모형에 대한 검증에 어떻게 활용되는지는 2021.07.03 - [CSS(Credit Scoring System)/신용평가모형 검증지표] - [R실습]K-S 통계량 산출하기를 참고하시면 됩니다. 이번 포스팅에서는 파이썬을 활용해서 실습만 진행해 보겠습니다. 본 실습은 jupyter notebook을 사용했습니다.
1. 실습 데이터 준비
상위에 링크되어 있는 데이터를 그대로 사용하겠습니다.
test.csv에는 3개의 헤더 포함 33개의 row와 3개의 column이 있습니다.
- car_kind: 자동차 종류이지만, 여기서는 사람을 구별할 수 있는 id로 간주
- prob: 우량 고객일 확률(값이 클수록 우량 고객일 확률이 높음)
- engine_type: 일정 기간이 경과한 후 실제 우량/불량 고객에 대한 색인(1: 우량고객 / 0: 불량고객)
2. K-S 통계량 산출
Step1) 테스트 데이터를 파이썬으로 불러오기
K-S 통계량을 산출하기 위해서는 우선, 테스트 데이터를 파이썬으로 불러와야 합니다. 아래의 명령문을 입력합니다.
import numpy as np
import pandas as pd
import math
# D드라이브의 python_exer 폴더에 있는 test.csv 파일 불러오기
test_data = pd.read_csv("D:/python_exer/test.csv")
Step2) 불러온 데이터 확인하기
test.csv 파일을 잘 불러왔는지 확인합니다. 데이터의 전체 행과 열의 개수를 확인하고, 데이터의 구조를 대략적으로 탐색합니다.
test_data.shape

확인 결과, 테스트 데이터에는 총 32개의 행과 3개의 열을 가지고 있는 것을 알 수 있습니다. 데이터 구조를 살펴보겠습니다.
test_data.head()
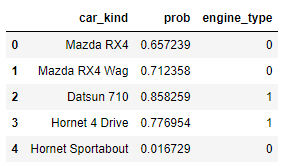
디폴트로 상위 5개의 데이터만 보여줍니다. ()안에 숫자를 입력하면 해당 숫자만큼 보여 줍니다.(Note: 3개의 칼럼 앞에 부여되어 있는 숫자는 idex값으로 테스트 데이터에는 존재하지 않는 값입니다.)
Step 3) 미래에 돈을 잘 갚을 확률(prob) 별 우량한 집단과 불량한 집단의 전체 수 산출
# id별로 불량회원 여부 색인하여 bad_yn 칼럼 생성
test_data['bad_yn'] = np.where(test_data.engine_type == 0, 1, 0)
# 우량한 집단과 불량한 집단의 pob별 건수 산출
test_data_summary = test_data.groupby("prob").sum().reset_index()
test_data_summary
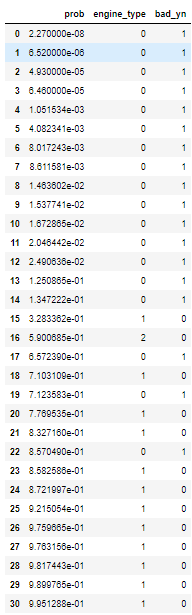
Step 4) 미래에 돈을 잘 갚을 확률이 증가함에 따른 두 집단의 누적 전체 수 산출
# 누적 우량한 집단 건수 산출
cum_good_cnt = np.arange(test_data_summary["prob"].size)
for i in range(test_data_summary["prob"].size):
____if i == 0:
________cum_good_cnt[i] = test_data_summary.loc[i,"engine_type"]
____else :
________cum_good_cnt[i] = cum_good_cnt[i-1] + test_data_summary.loc[i,"engine_type"]
# 누적 불량한 집단 건수 산출
cum_bad_cnt = np.arange(test_data_summary["prob"].size)
for i in range(test_data_summary["prob"].size):
____if i == 0:
________cum_bad_cnt[i] = test_data_summary.loc[i,"bad_yn"]
____else :
________cum_bad_cnt[i] = cum_bad_cnt[i-1] + test_data_summary.loc[i,"bad_yn"]
Step5) 미래에 돈을 잘 갚을 확률이 증가함에 따른 두 집단의 누적 구성비 산출
cum_good_pct = cum_good_cnt / cum_good_cnt.max() * 100
cum_bad_pct = cum_bad_cnt / cum_bad_cnt.max() * 100
cum_good_pct 결과 cum_bad_pct 결과

round(abs(cum_good_pct-cum_bad_pct).max(), 5)
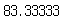
KS 통계량 값은 83.33333이고, 이 값은 2021.07.03 - [CSS(Credit Scoring System)/신용평가모형 검증지표] - [R실습]K-S 통계량 산출하기에서 산출한 KS 통계량 값과 동일함을 알 수 있다.
반응형
'CSS(Credit Scoring System) > 신용평가모형 검증지표' 카테고리의 다른 글
| [파이썬실습]신용평가 모형 검증(AUROC 산출하기) (0) | 2021.08.25 |
|---|---|
| [파이썬실습]신용평가 모형 검증(Information Value 산출하기) (0) | 2021.08.24 |
| [R실습]PSI 산출하기 (0) | 2021.07.07 |
| [R실습]AUROC 산출하기 (0) | 2021.07.04 |
| [R실습]Information Value 산출하기 (0) | 2021.07.04 |




댓글