이번 포스팅에서는 파이썬 초보자가
효율적이고 깔끔한 코드를 작성하는 데
도움이 되는 모범 사례를 제시할 예정입니다.
파이썬의 중급 프로그래머이더라도
이번 포스팅을 통해 새로운 트릭과
팁을 찾을 수 있을 것으로 기대합니다.
List Comprehensions:
List Comprehensions는 기존의 for 문보다
효율적인 파이썬 고유의 코드입니다.
for 문을 작성하는 더 짧고, 더 빠릅니다.
파이썬에서 for 문을 사용하는 대신
List Comprehensions를 사용해야 합니다.
# List Comprehensions 기본 코드
[표현 for 항목 in 반복구문]
# List Comprehensions 기본 코드 + if 문 사용
[표현 for 항목 in 반복구문 if 조건]
# List Comprehensions 기본 코드 + if else문 사용
[표현 if 조건 else 표현 for 항목 in 반복구문]
# list 구문 이외에 set과 dictionary에서도 가능
{표현 for 항목 in 반복구문} # set
{key:value for 항목 in 반복구문} # dictionary
Generator Expressions:
이미지 리스트를 저장해야 하는 경우를 고려해 보면,
어떤 데이터 구조가 떠오르나요?
분명히 값 리스트를 저장하려면
먼저 파이썬 리스트에 값을 저장해야 하지만
이 접근 방식은 많은 양의 데이터를
저장해야 할 때 메모리를 매우
비효율적으로 사용합니다.
대신 Generator를 사용하면 리스트보다
훨씬 더 메모리를 효율적으로
사용할 수 있습니다.
# Generator expressions 구문
(표현 for 항목 in 반복구문)
import sys
lst = [i * 10 for i in range(100)]
print("메모리 사용 : ", sys.getsizeof(lst))
gen = (i * 10 for i in range(100))
print("메모리 사용 : ", sys.getsizeof(gen))

Type Hinting:
데이터 유형과 반환 유형을 지정하면
다른 프로그래머가 코드를 더 잘 이해할 수 있습니다.
파이썬이 동적으로 유형이 지정되지만
여전히 데이터 유형을 지정해도
아무것도 변경되지 않아요.
이는 단지 코드의 가독성을
향상하기 위한 것입니다.
def add(x: int, y: int) -> int :
return x + y
정렬:
파이썬은 sort() 및 sorted()를 사용하여 정렬합니다.
sort는 내부 알고리즘인 반면
sorted는 정렬된 요소 리스트를 반환합니다.
또한 sort()는 파이썬의 리스트에서만
사용할 수 있는 반면
sorted는 파이썬의 모든 이터러블에
적용할 수 있습니다.
각 튜플에 학생 명부 번호와
해당 점수가 포함된 튜플 리스트가 있다고 가정하고,
번호 기준으로
리스트를 정렬하는 예시를 살펴보겠습니다.
lst = [(5, 65), (1, 80), (4, 90), (2, 67), (3, 99)]
# sorted 사용
print(sorted(lst))

# sort 함수 사용
lst.sort()
print(lst)
# 점수 기준으로 내림차순 정렬하기
sorted(lst, key = lambda x: x[1], reverse = True)

key 인수와 reverse 인수 모두
sort() 함수에서 인수로 사용할 수도 있습니다.
Copy and Deepcopy:
파이썬에서 객체는 함수에 대한 참조로 전달됩니다.
따라서 함수 내부에서 수행된
모든 변경 사항도 다시 반영됩니다.
lst = [[1,2], [3,4], [5,6], [7,8], [9,10]]
def change(var):
var[0] = [11, 12]
var[1][0] = 20
print(lst)
change(lst)
print(lst)

위의 결과에서 알 수 있듯이 change 함수가
원래 리스트를 변경했습니다.
이러한 상황을 피하기 위해 copy 함수를
사용할 수 있습니다.
lst = [[1,2], [3,4], [5,6], [7,8], [9,10]]
def change(var):
var = var.copy()
var[0] = [11, 12]
var[1][0] = 20
print(lst)
change(lst)
print(lst)

뭔가 이상하네요!!!
copy 함수는 리스트의 얕은 복사본을 만듭니다.
따라서 중첩된 요소는 change 함수에 의해 변경됩니다.
이것을 방지하기 위해서는
deepcopy를 사용해야 합니다.
from copy import deepcopy
lst = [[1,2], [3,4], [5,6], [7,8], [9,10]]
def change(var):
var = deepcopy(var)
var[0] = [11, 12]
var[1][0] = 20
print(lst)
change(lst)
print(lst)

deepcopy를 사용하면 실제 매개변수의 변경에 대해
걱정할 필요가 없습니다.
The f-문자열:
코드를 작성하려면 다른 형식 대신
f-문자열을 더 깔끔하고 간결하게 사용하세요.
a = 7
b = 5
print("a = %s b = %s a + b = %s"%(a, b, a+b))
# 다른 표현 1
print("a = {} b = {} a + b = {}".format(a, b, a+b))
# 추천 표현 - f 문자열
print(f"a = {a} b = {b} a + b = {a+b}")
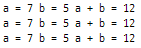
리스트 초기화 - 간단한 방법:
많은 경우에 상수 값으로 리스트를 초기화해야 합니다.
이러한 작업을 대부분의 사람들은 리스트를 선언한 다음
리스트에 값을 추가하는 for 문을 사용하는 방법을
생각합니다.
하지만 이러한 작업을 위한
훨씬 더 효율적인 방법이 있습니다.
value = 10
length = 10
# 방법 1
lst1 = []
for i in range(length):
lst1.append(value)
# 방법 2
lst2 = [value for i in range(length)]
# 방법 3
lst3 = [value] * length
# 결과는 모두 동일하지만, 방법 3이 가장 빠릅니다.
print(lst1)
print(lst2)
print(lst3)

큰 숫자의 가독성 향상:
파이썬에서는 밑줄 '_'을 사용하여
큰 숫자를 더 읽기 쉽게 만들 수 있습니다.
print(10_000)
print(100_000_000)
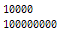
Reversing list or strings:
문자열이나 리스트를 뒤집기 위해
매번 함수를 작성하는 대신
슬라이싱을 사용하면
한 줄로 이를 수행할 수 있습니다.
lst = [1, 2, 3, 4, 5]
string = "Python"
print(lst[::-1])
print(string[::-1])

'is'와 '=='의 차이점 이해:
둘 사이에는 약간의 차이가 있습니다.
'is'는 두 변수가 동일한 위치를 가리키는지
여부를 확인하고,
"=="는 값이 동일한지 여부를 확인합니다.
a = [1, 2, 3]
b = [1, 2, 3]
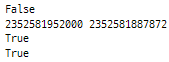
print(a is b) # False, a와 b의 메모리 주소가 다르기 때문
print(id(a), id(b))
print(a == b) # True, a와 b의 값이 동일하기 때문
c = a
print(c is a) # True, c와 a는 같은 메모리 주소를 공유하기 때문
Iterable 풀기:
파이썬은 '*' 연산자를 사용하여
이터러블을 압축 해제하는 쉬운 방법을 제공합니다.
name, age, occupation = ["John", "24", "Engineer"]
print(name)
print(age)
print(occupation)
# * 연산자 사용
a, *b = [1, 2, 34]
# a에는 리스트의 첫 번째 요소가 저장되고,
# b에는 리스트의 나머지 요소가 저장됩니다.
print(a,b)

unpacking은 for 루프를 사용하지 않고
리스트의 공백으로 구분된 요소를
출력하는 데에도 사용할 수 있습니다.
lst = [1, 2, 3, 4]
print(*lst)
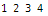
Dictionary merge operator(‘|’):
이 연산자는 python 3.9 이상에서 사용 가능합니다.
이 연산자를 사용하면
두 개의 딕셔너리를 병합할 수 있습니다.
두 딕셔너리에 동일한 키가 있으면,
값이 오른쪽 딕셔너리에서 업데이트됩니다.
dict1 = {'a':1, 'b':2, 'c':3}
dict2 = {'b':4, 'd':4}
# 파이썬 3.9 버전
print(dict1|dict2)
# 오래된 파이썬 버전
print({**dict1, **dict2})

딕셔너리 get 함수:
딕셔너리에서 값을 검색하기 위해
dct[key] 구문을 사용하지 마세요.
이 메서드는 key가 딕셔너리에 없으면
예외를 반환합니다.
dct.get(key) 메서드는 키가 존재하지 않는 경우,
예외를 발생시키지 않습니다.
key가 존재하지 않는 경우
해당 값을 사용하도록 이 함수에
두 번째 인수를 제공할 수 있습니다.
dict1 = {'a':1, 'b':2, 'c':3}
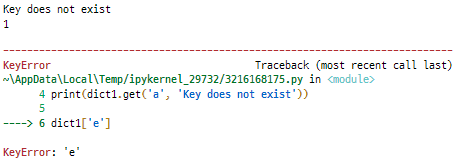
print(dict1.get('e', 'Key does not exist'))
print(dict1.get('a', 'Key does not exist'))
dict1['e']
리스트를 문자열로, 문자열을 리스트로 변환:
리스트를 단일 문자열로 변환하려면,
join() 함수를 사용하시면 됩니다.
lst = ["Python", "is", "widely", "used", "in", "Data", "Science"]
# 공백으로 문자열 결합
print(" ".join(lst))
# 쉼표(',')로 문자열 결합
print(",".join(lst))

split() 함수를 사용하여 문자열을 리스트로
변환할 수 있습니다.
기본적으로 split() 함수는 문자열을 공백으로 분할하고,
다른 문자로 분할하려면 split 함수에서
해당 문자를 작성하시면 됩니다.
# 방법 1
string = "Python is widely used in Data Science"
print(string.split())
# 방법 2
string = "Python"
print(list(string))
# 이건 어떨까?
stringList = "[[1,2,3], [4,5,6]]"
print(list(stringList))

위의 3번째 리스트 생성자는
문자열에서 문자 리스트를 만듭니다.
우리가 원하는 리스트 형식이 아니네요.
원하는 결과, 즉 리스트의 리스트를 얻으려면
json.loads() 함수를 사용해야 합니다.
import json
stringList = "[[1,2,3], [4,5,6]]"
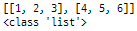
lst = json.loads(stringList)
print(lst)
print(type(lst))
'Python' 카테고리의 다른 글
| Python 프로그래머가 저지르는 20가지 초보자 실수 (0) | 2023.04.22 |
|---|---|
| 파이썬 클래스 변수 사용법 (2) | 2022.09.30 |
| 파이썬의 유용한 4가지 함수 (0) | 2022.09.17 |
| 파이썬의 10가지 유용한 팁 (0) | 2022.09.05 |
| 웹 스크래핑 배우기 (0) | 2022.08.06 |
댓글