본 포스팅은 pandas 공식 홈페이지를 기반으로 작성하였습니다. data.frame
pandas는 R을 사용하는 많은 데이터 조작 및 분석 기능을 제공하는 것을 목표로 하기 때문에, 본 포스팅에서는 pandas와 관련된 R 언어 및 R 언어의 많은 라이브러리에 대한 자세한 내용을 비교하여 설명하려고 합니다. R 및 CRAN 라이브러리와 주요 비교는 아래와 같습니다.
- 기능 및 유연성 : 각 Tool로 할 수 있는 것과 할 수 없는 것
- 성능 : 작업이 얼마나 빠른지. 어려운 숫자 및 벤치마크가 바람직합니다.
- 사용의 용이성 : 판단이 쉽도록 코드를 비교표 형식으로 제공
이 페이지는 또한 이러한 R 패키지 사용자를 위한 약간의 설명을 제공합니다. pandas에서 R로 DataFrame 개체를 전송하는 경우 한 가지 옵션은 HDF5 파일을 사용하는 것입니다. 예제는 외부 호환성을 참조하세요.
1. 빠른 참조
dplyr(데이터 처리를 위한 R의 대표적인 패키지.)과 pandas를 사용하는 몇 가지 일반적인 R 작업을 빠르게 비교해 보겠습니다.
1.1. 쿼리 / 필터링 / 샘플링
| R | pandas |
| dim(df) | df.shape |
| head(df) | df.head |
| slice(df, 1:10) | df.iloc[:9] |
| filter(df, col1 == 1, col2 == 1) | df.query('col1 == 1 & col2 == 1') |
| df[df$col1 == 1 & df$col2 == 1,] | df[(df.col1 == 1) & (df.col2 == 1)] |
| select(df, col1, col2) | df[['col1','col2']] |
| select(df, col1:col3) | df.loc[ : , 'col1':'col3' ] |
| select(df, -(col1:col3)) | df.drop(cols_to_drop, axis=1)* |
| distinct(select(df, col1)) | df[['col1']].drop_duplicates() |
| distinct(select(df, col1, col2)) | df[['col1', 'col2']].drop_duplicates() |
| sample_n(df, 10) | df.sample(n=10) |
| sample_frac(df, 0.01) |
df.sample(frac=0.01) |
* 열의 하위 범위(select(df, col1:col3))에 대한 R의 약어는 열 목록이 있는 경우 pandas에서 깔끔하게 접근할 수 있습니다(예: df[cols[1:3]]
또는 df.drop(cols[ 1:3]). 그러나 열 이름으로 이 작업을 수행하는 것은 약간 지저분합니다.
1.2. 정렬(sorting)
| R | pandas |
| arrange(df, col1, col2) | df.sort_values(['col1', 'col2']) |
| arrange(df, desc(col1)) | df.sort_values('col1', ascending=False) |
1.3. 변수 변환
| R | pandas |
| select(df, col_one = col1) | df.rename(columns={'col1': 'col_one'})['col_one'] |
| rename(df, col_one = col1) | df.rename(columns={'col1': 'col_one'}) |
| mutate(df, c=a-b) | df.assign(c=df['a']-df['b']) |
1.4. 그룹화 및 요약
| R | pandas |
| summary(df) | df.describe() |
| gdf <- group_by(df, col1) | gdf = df.groupby('col1') |
| summarise(gdf, avg=mean(col1, na.rm=TRUE)) | df.groupby('col1').agg({'col1': 'mean'}) |
| summarise(gdf, total=sum(col1)) | df.groupby('col1').sum() |
2. R Base
2.1. R slicing with c
R을 사용하면 이름으로 data.frame 열에 쉽게 접근할 수 있습니다.
# a, b, c, d, e 열을 가지는 데이터 프레임(df) 생성
df <- data.frame(a=rnorm(5), b=rnorm(5), c=rnorm(5), d=rnorm(5), e=rnorm(5))
# 데이터프레임에서 a, c, e 열 선택
df[, c("a", "c", "e")]
또는 정수 위치로도 가능합니다.
# 10개의 행과 100개의 열을 가지는 데이터 프레임(df) 생성
df <- data.frame(matrix(rnorm(1000), ncol=100))
# 1 ~ 10번째 열 선택 & 25 ~ 30번째 열 선택 & 40번째 열 선택 & 50 ~ 100번째 열 선택
df[, c(1:10, 25:30, 40, 50:100)]
pandas에서 이름으로 여러 열을 선택하는 것은 간단합니다.
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(10,3), columns= list("abc"))
df
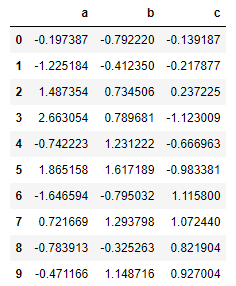
df[["a", "c"]]

df.loc[: , ["a", "c"]]
정수 위치로 여러 개의 비연속 열을 선택하는 것은 iloc 인덱서 속성과 numpy.r_의 조합으로 달성할 수 있습니다.
named = list("abcdefg")
n = 30
columns = named + np.arange(len(named), n).tolist()
df = pd.DataFrame(np.random.randn(n, n), columns=columns)
df.iloc[:, np.r_[:10, 24:30]]

2.2. aggregate
R에서는 데이터를 하위 집합으로 나누고 각각의 평균을 계산할 수 있습니다. df라는 data.frame을 사용하고 by1 및 by2 그룹으로 분할
df <- data.frame( v1 = c(1, 3, 5, 7, 8, 3, 5, NA, 4, 5, 7, 9),
v2 = c(11, 33, 55, 77, 88, 33, 55, NA, 44, 55, 77, 99),
by1 = c("red", "blue", 1, 2, NA, "big", 1, 2, "red", 1, NA, 12),
by2 = c("wet", "dry", 99, 95, NA, "damp", 95, 99, "red", 99, NA, NA))
aggregate(x=df[, c("v1", "v2")], by=list(df$by1, df$by2), FUN = mean)

pandas의 groupby() 메서드는 기본 R aggregate 함수와 유사합니다.

2.3. match / %in%
R에서 데이터를 선택하는 일반적인 방법은 match 함수를 사용하여 정의된 %in%를 사용하는 것입니다. %in% 연산자는 일치 여부를 나타내는 논리 벡터를 반환하는 데 사용됩니다.
s <- 0:4 # s에 0, 1, 2, 3, 4 입력
s %in% c(2,4) # s에 2 혹은 4 포함 여부 확인

pandad의 isin() 메서드는 R의 %in% 연산자와 유사합니다.
import numpy as np
import pandas as pd
s = pd.Series(np.arange(5), dtype=np.float32)
s.isin([2, 4])

R에서 match 함수는 두 번째 인수에서 첫 번째 인수의 일치 위치 벡터를 반환합니다. 아래 예시를 보시면서 이해하시기 바랍니다.
s <- 0:4 # s에 0, 1, 2, 3, 4 입력
match(s, c(2,4))

2.4. tapply
tapply는 aggregate와 유사하지만 하위 클래스 크기가 불규칙할 수 있으므로 데이터가 불규칙한 배열에 있을 수 있습니다. baseball이라는 데이터 프레임을 생성하고, array 인 team을 기반으로 한 정보를 획득하는 예를 보겠습니다.
baseball <-
____data.frame(team = gl(5, 5,
____________________________labels = paste("Team", LETTERS[1:5])),
________________player = sample(letters, 25),
________________batting.average = runif(25, .200, .400))
tapply(baseball$batting.average, baseball$team,max)


pandas에서는 이것을 처리하기 위해 pivot_table() 메서드를 사용할 수 있습니다.
import random
import string
baseball = pd.DataFrame(
________________________________{ "team": ["team %d" % (x + 1) for x in range(5)] * 5,
__________________________________"player": random.sample(list(string.ascii_lowercase), 25),
__________________________________"batting avg": np.random.uniform(0.200, 0.400, 25),
_________________________________}
____________________________)
baseball
baseball.pivot_table(values="batting avg", columns="team", aggfunc=np.max)


2.5. subset
query() 메서드는 base R의 subset 함수와 유사합니다. R에서는 한 열의 값이 다른 열의 값보다 작은 data.frame의 행을 선택할 때, 아래와 같이 실행하면 됩니다.
df <- data.frame(a=rnorm(10), b=rnorm(10))
subset(df, a <= b) # 혹은 아래와 같이 실행해도 동일함
df[df$a <= df$b,] # , 를 주의하세요.

pandas에서는 subset을 수행하는 몇 가지 방법이 있습니다. query()를 사용하거나 인덱스/슬라이스 및 표준 bool 인덱싱인 것처럼 표현식을 전달할 수 있습니다.
df = pd.DataFrame({"a": np.random.randn(10), "b": np.random.randn(10)})
df.query("a <= b") # 혹은 아래와 같이해도 결과는 동일
df[df["a"] <= df["b"]] # 혹은 아래와 같이해도 결과는 동일
df.loc[df["a"] <= df["b"]]

2.6. with
R에서 a와 b 열이 있는 df라는 data.frame을 생성한 후 두열을 더하는 표현식은 다음과 같습니다.
df <- data.frame(a=rnorm(10), b=rnorm(10))
df

with(df, a + b) # 혹은 아래와 같이해도 결과는 동일함
df$a + df$b

pandas에서 eval() 메서드를 사용하는 동일한 표현식은 다음과 같습니다.
df = pd.DataFrame({"a": np.random.randn(10), "b": np.random.randn(10)})
df

df.eval("a + b")

df["a"] + df["b"]
3. plyr
plyr은 데이터 분석을 위한 split-apply-combine 전략을 위한 R 라이브러리입니다. 함수는 R의 세 가지 데이터 구조(a는 array, l은 list, d는 data.frame)를 중심으로 회전합니다. 아래 표는 이러한 데이터 구조가 Python에서 매핑되는 방법을 보여줍니다.
| R | Python |
| array | list |
| list | dictionary or list of objects |
| data.frame | dataframe |
3.1. ddply
R에서 df라는 data.frame에 대해서 x를 월별로 요약하려 할 때 사용하는 표현식은 아래와 같습니다.
require(plyr)
df <- data.frame(
______________________x = runif(120, 1, 168),
______________________y = runif(120, 7, 334),
______________________z = runif(120, 1.7, 20.7),
______________________month = rep(c(5,6,7,8),30),
______________________week = sample(1:4, 120, TRUE)
___________________)
ddply(df, .(month, week), summarize, mean = round(mean(x), 2), sd = round(sd(x), 2))
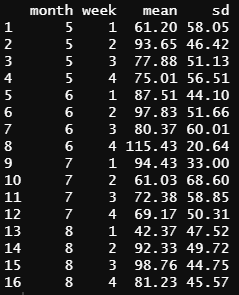
pandas에서 groupby() 메서드를 사용하는 동일한 표현식은 다음과 같습니다.
df = pd.DataFrame(
________________________{
_____________________________"x": np.random.uniform(1.0, 168.0, 120),
_____________________________"y": np.random.uniform(7.0, 334.0, 120),
_____________________________"z": np.random.uniform(1.7, 20.7, 120),
_____________________________"month": [5, 6, 7, 8] * 30,
_____________________________"week": np.random.randint(1, 4, 120),
_________________________}
______________________)
grouped = df.groupby(["month", "week"])
grouped["x"].agg([np.mean, np.std])

4. reshape / reshape2
4.1. melt.array
R에서 data.frame으로 녹여서 a라고 하는 3차원 배열을 사용하는 표현식은 아래와 같습니다.
a <- array(c(1:23, NA), c(2,3,4))

require(reshape2)
data.frame(melt(a))

Python에서는 a가 list이기 때문에 단순히 list를 사용할 수 있습니다.
a = np.array(list(range(1, 24)) + [np.NAN]).reshape(2, 3, 4)
pd.DataFrame([tuple(list(x) + [val]) for x, val in np.ndenumerate(a)])

4.2. melt.list
R에서 data.frame으로 녹이고 싶은 a라는 list를 사용하는 표현식은 아래와 같습니다.
a <- as.list(c(1:4, NA))

data.frame(melt(a))

Python에서 이 list는 tuple 목록이므로 DataFrame() 메서드는 필요에 따라 이를 데이터 프레임으로 변환합니다.
a = list(enumerate(list(range(1, 5)) + [np.NAN]))
pd.DataFrame(a)

4.3. melt.data.frame
R에서 data.frame을 재구성하려면 cheese라는 data.frame을 사용하면 됩니다.
cheese <- data.frame( first = c('John', 'Mary'),
_________________________last = c('Doe', 'Bo'),
_________________________height = c(5.5, 6.0),
_________________________weight = c(130, 150)
_______________________)
melt(cheese, id=c("first", "last"))


Python에서 melt() 메서드는 R과 동일합니다.
cheese = pd.DataFrame(
_____________________________{
________________________________"first": ["John", "Mary"],
________________________________"last": ["Doe", "Bo"],
________________________________"height": [5.5, 6.0],
________________________________"weight": [130, 150],
______________________________}
___________________________)
cheese

pd.melt(cheese, id_vars=["first", "last"])

4.4. cast
R에서 acast는 더 높은 차원의 배열로 만들기 위해 R에서 df라는 data.frame을 사용하는 표현식입니다.
df <- data.frame( x = runif(12, 1, 168),
____________________y = runif(12, 7, 334),
____________________z = runif(12, 1.7, 20.7),
____________________month = rep(c(5,6,7),4),
____________________week = rep(c(1,2), 6) )
df

mdf <- melt(df, id=c("month", "week"))
mdf

acast(mdf, week ~ month ~ variable, mean)

Python에서 가장 좋은 방법은 pivot_table()을 사용하는 것입니다.
df = pd.DataFrame( {
_________________________"x": np.random.uniform(1.0, 168.0, 12),
_________________________"y": np.random.uniform(7.0, 334.0, 12),
_________________________"z": np.random.uniform(1.7, 20.7, 12),
_________________________"month": [5, 6, 7] * 4,
_________________________"week": [1, 2] * 6, } )
df

mdf = pd.melt(df, id_vars=["month", "week"])
mdf

pd.pivot_table( mdf,
_________________values="value",
_________________index=["variable", "week"],
_________________columns=["month"],
_________________aggfunc=np.mean, )

마찬가지로 R에서 df라는 data.frame을 사용하여 Animal 및 FeedType을 기반으로 정보를 집계하는 dcast의 경우는 아래와 같습니다.
df <- data.frame( Animal = c('Animal1', 'Animal2', 'Animal3', 'Animal2', 'Animal1', 'Animal2', 'Animal3'), ___________________FeedType = c('A', 'B', 'A', 'A', 'B', 'B', 'A'),
___________________Amount = c(10, 7, 4, 2, 5, 6, 2) )
df

dcast(df, Animal ~ FeedType, sum, fill=NaN)

비슷하게 아래와 같은 표현식으로도 가능합니다.
# Alternative method using base R
with(df, tapply(Amount, list(Animal, FeedType), sum))

Python 두 가지 다른 방식으로 접근할 수 있습니다.
첫째, 위의 pivot_table() 사용과 유사합니다.
df = pd.DataFrame( {
______________________"Animal": [ "Animal1", "Animal2", "Animal3", "Animal2", "Animal1", "Animal2", "Animal3", ], ______________________"FeedType": ["A", "B", "A", "A", "B", "B", "A"],
______________________"Amount": [10, 7, 4, 2, 5, 6, 2], } )
df

df.pivot_table(values="Amount", index="Animal", columns="FeedType", aggfunc="sum")

두 번째 접근 방식은 groupby() 메서드를 사용하는 것입니다.
df.groupby(["Animal", "FeedType"])["Amount"].sum()

4.5. factor
pandas에는 범주형 데이터에 대한 데이터 유형이 있습니다.
cut(c(1, 2, 3, 4, 5, 6), 3)

factor(c(1,2,3,2,2,3))

pandas에서 이것은 pd.cut 및 astype("category")으로 수행됩니다.
pd.cut(pd.Series([1, 2, 3, 4, 5, 6]), 3)

pd.Series([1, 2, 3, 2, 2, 3]).astype("category")

'Python > Python vs Else Tools' 카테고리의 다른 글
| Python VS SQL (0) | 2021.09.02 |
|---|

댓글