분류 기계 학습 모델의 성능을 평가하는 방법은 무엇입니까?
데이터 전처리 단계를 마무리하고,
기계 학습 모델에 적용하면,
확률로 그 결과(출력) 값을 얻습니다.
모델 결과의 성능을 어떻게 측정할 수 있을까요?
Confusion Matrix는 분류 모델을 확인하여
모델이 더 좋고 효과적인 방식으로
작동하는 방법을 찾는 가장 좋은 방법입니다.
이번 포스팅에서는 약간은 혼란스러워 보이지만
사소해 보이는 Confusion Matrix와
관련 용어에 대해 알아보도록 하겠습니다.
Confusion Matrix(혼동 행렬), Precision(정밀도),
Recall(재현율) 및 F1 Score는 정확도(Accuracy)에 비해
예측 결과에 대한 더 나은 직관을 제공합니다.
Confusion Matrix(혼동 행렬)
confusion matrix는 분류 문제를 해결할 때,
사용되는 매우 인기 있는 척도입니다.
이진 분류 뿐만 아니라 및 다중 클래스 분류 문제에도
적용할 수 있습니다.
Confusion Matrix는 기계 학습 분류를 위한 성능 측정입니다.
신용도를 평가하는 모델 역시
이진 분류(우량회원/불량회원) 모델이기 때문에,
이를 기준으로 설명해 보겠습니다.
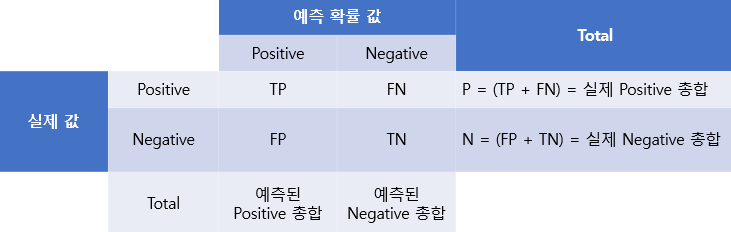
1. TP(True Positive): 실제 우량회원을 적절하게 우량회원으로 분류한 전체 수
2. TN(True Negative): 실제 불량회원을 적절하게 불량회원으로 분류한 전체 수
3. FP(False Positive): 우량회원으로 잘못 분류되었지만, 실제로는 불량회원인 전체 수(제1종 오류)
4. FN(False Negative): 불량회원으로 잘못 분류되었지만 실제로는 우량회원인 전체 수(제2종 오류)
Example:
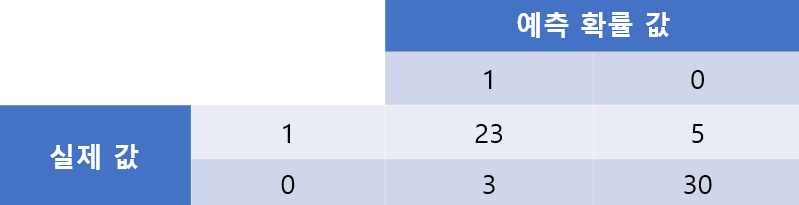
위의 혼동 행렬은
모델이 분류되는 방식을 설명합니다.
1은 우량회원을 나타내고,
0은 불량회원을 나타냅니다.
그러면, 23과 30은 완벽하게 분류된 케이스이고,
3과 2는 잘못 분류된 케이스가 됩니다.
모델의 정확도(Accuracy)는
총 환자 수(TP+TN+FP+FN)에 대해
올바르게 분류된 환자(TP+TN)의 비율로 표시됩니다.
# 모델의 정확도
Accuracy = (TP + TN) / (TP + FP + FN + TN)
알고리즘의 정밀도(Precision)는
우량회원으로 예측된 전체 환자(TP+FP) 중에서
우량회원(TP)으로 올바르게 분류된 환자의 비율로 표시됩니다.
# 모델의 정밀도
Precision = TP / (TP+FP)
재현율(Recall) 지표는
올바르게 분류된 우량회원(TP)을
실제로 전체 우량회원 수로 나눈 비율로 정의됩니다.
# 모델의 재현율
Recall = TP / (TP+FN)
Recall은 우량회원 중 얼마나 많은 회원이
우량회원으로 분류되었는지를 나타냅니다.
Recall은 sensitivity(민감도)라고도 합니다.
F1 score는 F 측정이라고도 합니다.
F1 점수는 정밀도와 재현율 간의 균형을 나타냅니다.
F1 Score = 2*precision*recall /( precision+recall)
Conclusion
이번 포스팅에서는
이진 분류 기계학습 모델의 성능을 측정하는 지표인
Confusion Matrix, Precision-Recall 및 F1 Score라는
용어에 대해서 알아보았습니다.
이러한 지표를 이해하고, 잘 사용하면
모델의 성능을 더 잘 이해하는 데
확실히 도움이 될 것입니다.
'Machine Learning' 카테고리의 다른 글
| 앙상블 학습에 대한 설명과 기법에 대한 소개 (2) | 2022.07.23 |
|---|---|
| Python 예제를 사용한 기계 학습의 정규화 및 표준화 (0) | 2022.06.13 |
| DecisionTreeClassifier (0) | 2022.06.12 |
| Cross Validation(교차 검증) (0) | 2022.06.05 |
| 하이퍼파라미터 Serching (with 파이썬) - GridSearchCV() 함수 (0) | 2022.02.14 |


댓글