Machine Learning (LightGBM) 코드 예제(with R)를 먼저 수행해야 함!!
lgb.get.eval.result(): 부스터로부터 평가 결과 얻기
lgb.Booster가 주어지면 특정 데이터세트의 특정 메트릭에 대한 평가 결과를 반환합니다.
# 코드 형식
lgb.get.eval.result(
booster,
data_name,
eval_name,
iters = NULL,
is_err = FALSE
)
- Arguments
- booster: lgb.Booster 클래스의 객체
- data_name: 평가 결과를 반환할 데이터 세트 이름
- eval_name: 결과를 반환할 평가 측정항목의 이름
- iters: 평가 결과를 얻으려는 반복의 정수 벡터입니다. NULL(기본값)이면 모든 반복에 대한 평가 결과 반환
- value: 평가 결과의 숫자형 벡터
# 유효한 data_name 값 검사
print(setdiff(names(model$record_evals), "start_iter"))# 데이터세트 "test"에 대한 유효한 eval_name 값 검사
print(names(model$record_evals[["test"]]))# "test" 데이터 세트에 대한 auc 값 가져오기
lgb.get.eval.result(model, "test", "auc")

lgb.importance(): Compute feature importance in a model
모델의 feature importance에 대한 data.table을 생성합니다.
# 코드 형식
lgb.importance(model, percentage = TRUE)
- Arguments
- model: lgb.Booster 클래스의 객체
- percentage: 상대적 백분율로 중요도를 표시할지 여부
- value: 트리 모델의 경우 다음 열이 있는 data.table
- Feature: 모델의 feature name
- Gain: 이 feature split의 총 이득
- Cover: 이 기능과 관련된 관찰 수
- Frequency: 트리에서 feature가 분할된 횟수
# 활용 예시
tree_imp1 <- lgb.importance(model, percentage = TRUE)
tree_imp1
tree_imp2 <- lgb.importance(model, percentage = FALSE)
tree_imp2
lgb.interprete(): Compute feature contribution of prediction
원시 점수 예측(rawscore prediction)의 기능 기여 구성 요소(feature contribution components)를 계산합니다.
# 코드 형식
lgb.interprete(model, data, idxset, num_iteration = NULL)
- Arguments
- model: lgb.Booster 클래스의 객체
- data: 행렬 객체 또는 dgCMatrix 객체
- idxset: 필요한 행 인덱스의 정수 벡터
- num_iteration: 예측하려는 반복 횟수, NULL 또는 <= 0은 최상의 반복 사용을 의미
- value: 회귀, 이진 분류 및 람다랭크 모델의 경우 다음 열이 있는 data.table list
- Feature: 모델의 feature name
- Contribution: 이 feature 분할의 총 기여도
- 다중 클래스 분류의 경우 각 클래스에 대한 feature 열 및 기여 열이 있는 data.table 목록
# 활용 예시
tree_interpretation <- lgb.interprete(model, x_test, 1:4)
tree_interpretation
lgb.plot.importance(): feature importance를 막대 그래프로 표시
위에서 계산된 feature importance(Gain, Cover 및 Frequency)를 막대그래프로 표시합니다.
# 코드 형식
lgb.plot.importance(
tree_imp,
top_n = 10L,
measure = "Gain",
left_margin = 10L,
cex = NULL
)
- Arguments
- tree_imp: lgb.importance에 의해 반환된 data.table
- top_n: 플롯에 포함할 상위 feature의 최대 수
- measure: 플롯할 중요도 측정값의 이름("Gain", "Cover" 또는 "Frequency")
- left_margin: (기본 R 막대그래프) feature 이름에 맞게 왼쪽 여백 크기 조정
- cex: (기본 R barplot) cex.names 매개변수로 barplot에 전달됨. 막대 레이블을 R의 기본값보다 작게 만들려면 1.0보다 작은 숫자를 설정하고 더 크게 만들려면 1.0보다 큰 값을 설정
- value: lgb.plot.importance 함수는 막대그래프를 생성하고 정의된 중요도에 따라 정렬된 top_n feature를 data.table로 자동 반환
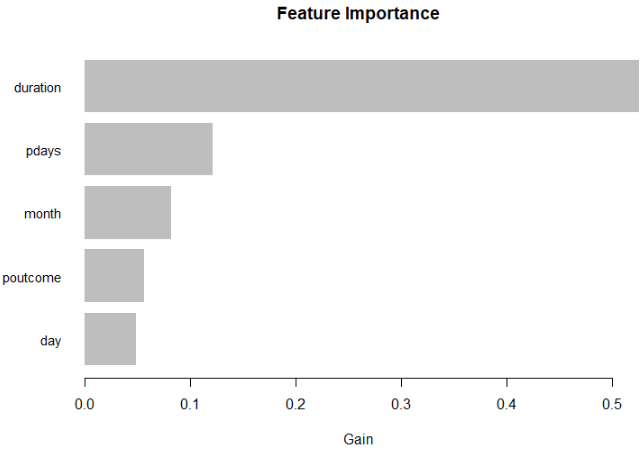
- Details: 그래프는 각 feature를 feature의 정의된 중요도에 비례하는 길이의 가로 막대로 표현. feature는 중요도가 낮은 순서로 순위가 매겨집니다.
# 활용 예시
tree_imp <- lgb.importance(model, percentage = TRUE)
lgb.plot.importance(tree_imp, top_n = 5, measure = "Gain")
lgb.plot.interpretation(): Plot feature contribution as a bar graph
이전에 계산된 feature contribution을 막대 그래프로 플로팅 합니다.
# 코드 형식
lgb.plot.interpretation(
tree_interpretation_dt,
top_n = 10L,
cols = 1L,
left_margin = 10L,
cex = NULL
)
- Arguments
- tree_interpretation_dt: lgb.interprete가 반환한 data.table
- top_n: 플롯에 포함할 상위 feature의 최대 수
- cols: 레이아웃의 열 번호. 다중 클래스 분류 feature contribution에만 사용
- left_margin: (기본 R 막대그래프) feature 이름에 맞게 왼쪽 여백 크기 조정
- cex: (기본 R barplot) cex.names 매개변수로 barplot에 전달됨. 막대 레이블을 R의 기본값보다 작게 만들려면 1.0보다 작은 숫자를 설정하고 더 크게 만들려면 1.0보다 큰 값을 설정
- value: lgb.plot.interpretation 함수는 막대그래프를 생성
- Details: 그래프는 feature의 정의된 기여도에 비례하는 길이의 수평 막대로 각 feature를 표현. feature는 기여도가 감소하는 순서로 순위가 매겨집니다.
# 활용 예시
tree_interpretation <- lgb.interprete( model = model , data = x_test , idxset = 1:4 )
tree_interpretation
lgb.plot.interpretation( tree_interpretation_dt = tree_interpretation[[1]] , top_n = 3 )


반응형
'Machine Learning > LightGBM' 카테고리의 다른 글
| lightgbm 알고리즘을 사용한 이진분류예측모델 적합(with 파이썬) (0) | 2022.02.12 |
|---|---|
| lightgbm 주요 하이퍼파라미터 (with 파이썬) (0) | 2022.02.08 |
| LightGBM 모델 결과 저장 및 불러오기(with R) (0) | 2022.01.14 |
| Machine Learning (LightGBM)코드 예제(with R) (0) | 2022.01.13 |
| Data I/O for LightGBM (with R) (0) | 2022.01.12 |



댓글