이번 포스팅에서는 Netflix에서 제공되는
TV 프로그램 및 영화에서 흥미로운 통찰력을 얻기 위한
분석을 진행해 보고자 합니다.
NumPy, Pandas, Matplot 및
Seaborn 라이브러리를 사용하여
데이터를 분석하고 시각화하도록 하겠습니다.
시작하기
이 데이터세트는 2020년 현재 Netflix에서 제공되는
TV 프로그램 및 영화로 구성되어 있습니다.
해당 데이터는 캐글에서 다운로드하시면 됩니다.
(https://www.kaggle.com/shivamb/netflix-shows)
import numpy as np
import pandas as pd
netflixData = pd.read_csv("C:/netflix_titles/netflix_titles.csv")
netflixData.head()

첫 번째 단계는 데이터 파일(.csv)을 간단히 살펴보고
열, 데이터 유형 및 누락된 값을 분석하는 것이었습니다.
netflixData.info()
데이터 준비 및 정리
우선, 다음과 같이 데이터를 준비합니다.
열 'show_id'를 삭제하고 'country' 열의 빈 셀을 교체하고,
아래와 같이 'date_added' 열의 형식을
DateTime 형식으로 변환합니다.
# show_id 열 제거
netflixData.drop(['show_id'],axis=1,inplace=True)
netflixData['country'].value_counts()
# datetime 형식으로 변환
netflixData['date_added'] = pd.to_datetime(netflixData['date_added'], errors='coerce')
데이터 세트 분석
데이터 세트를 시각화하고 분석하기 위해
matplot 및 seaborn 라이브러리를 사용합니다.
1. TV 프로그램과 영화 간의 콘텐츠 분할
import matplotlib.pyplot as plt
contentType = netflixData['type'].value_counts()
plt.pie(contentType.values, labels = contentType.index, autopct='%1.1f%%', radius=1.5)
plt.legend(contentType.index, loc="upper center", bbox_to_anchor=(1.35, 1), ncol=1)
plt.title('TV Shows vs Movies', y = 1.15, fontsize = 20, weight = 'bold')
plt.show()
2. 영화 및 TV 프로그램의 연도별 콘텐츠 성장 추이(2008년~2019년)
먼저 데이터를 분석하기 위해
pd.DatetimeIndex()를 사용하여
데이터 프레임에 "year_added" 열을 삽입했습니다.
netflixData['year_added'] = pd.DatetimeIndex(netflixData['date_added']).year
# 일정 기간 동안 영화 또는 TV 프로그램 수를 계산하는 함수 정의
def count_per_year(df,type_content,start_year,end_year):
count=[]
for i in range(start_year,end_year+1):
m = len(df.loc[(df.type == type_content) & (df.year_added==i)])
count.append(m)
return count
years = range(2008,2020)
movies = count_per_year(netflixData,'Movie',2008,2019)
tv_shows =count_per_year(netflixData,'TV Show',2008,2019)
plt.plot(years,movies,'b-x')
plt.plot(years,tv_shows,'r-o')
plt.legend(['Movies', 'TV Shows'])
plt.ylabel('Count')
plt.xlabel('Year')
plt.title('Netflix content added from 2008 to 2019')
plt.show()
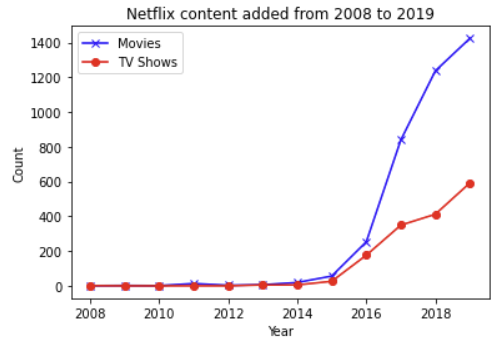
- 여기서 우리는 2015년 이후 영화 및
TV 프로그램의 콘텐츠가 모두 증가했음을 알 수 있습니다. - 2016년 즈음까지는 유사해 보이지만,
2016년에서 2017년 사이에 영화 콘텐츠의 수가
급격히 증가하고 있음을 알 수 있습니다.
3. 업로드되는 프로그램의 월 및 날짜 분석
monthlyContent = pd.DatetimeIndex(netflixData.date_added).month.value_counts().sort_index()
order = ['Jan','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec']
import seaborn as sns
plt.title("Monthly added content on netflix",y=1.1)
sns.barplot(y = monthlyContent.values, x = order);
plt.xlabel("Months")
plt.ylabel("Frequency");

- 10월부터 1월까지 더 많은 콘텐츠가
업로드되는 것이 여기에서 관찰됩니다.
12월이 가장 높네요.
netflixData['weekday'] = pd.DatetimeIndex(netflixData.date_added).weekday
b = netflixData.weekday.value_counts().sort_index()
#0 is for Monday
order=['Mon','Tue','Wed','Thu','Fri','Sat','Sun']
sns.barplot(x = order,y = b.values);
plt.xlabel("Weekday")
plt.ylabel("Frequency")
plt.title("Distribution of netflix content on the days of week",y=1.1)
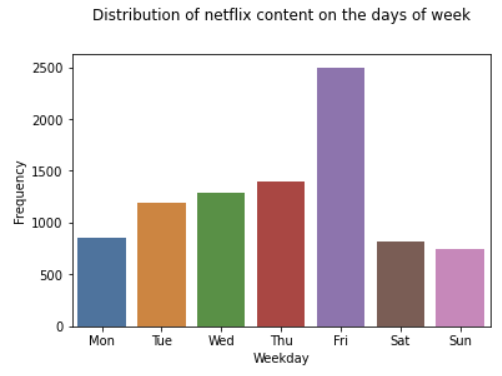
- 넷플릭스는 시청자들이 가장 보기 편한 시간인
금요일에 대부분의 콘텐츠를 업로드하네요.
4. NetFlix 콘텐츠 측면에서 상위 10개국 비교
콘텐츠가 포함된 국가를 보기 위해
value_counts( ) 속성을 사용했습니다.
대부분의 셀(cell)에는 여러 국가 이름이 있었습니다.
따라서 정확한 개수를 얻으려면
국가 이름을 쉼표로 구분한 다음 개수를 세어야 합니다.
countries = netflixData.country.value_counts().head(10).index
contentCount = netflixData.country.value_counts().head(10).values
sns.barplot(y=countries,x=contentCount);
plt.title("Top 10 Countries with highest Netflix content",y=1.05)
plt.xlabel('Total Count (Movie + TV Show)',labelpad=20);
plt.xticks(range(0,3250,250));
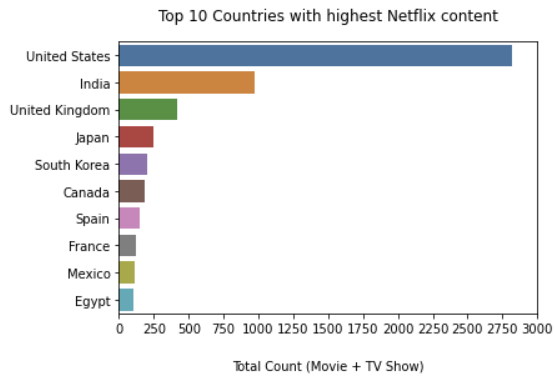
5. TV 쇼 및 영화의 주요 장르
movieDf = netflixData[netflixData.type == 'Movie']
movieGenre = movieDf.listed_in.value_counts().head(20)
genresM = movieGenre.index
countM = movieGenre.values / movieGenre.values.sum() *100
tvDf = netflixData[netflixData.type == 'TV Show']
tvGenre = tvDf.listed_in.value_counts().head(20)
genresTv = tvGenre.index
countTv = tvGenre.values / movieGenre.values.sum() *100
fig, (ax1,ax2) = plt.subplots(1,2,figsize=(20,10))
ax1.set_title("Genres of Movies and their percentage on Netflix")
sns.barplot(y=genresM,x=countM,ax=ax1)
ax1.set_xlabel('Total Percentage (%)',labelpad=20, fontsize=20);
ax1.plot()
ax2.set_title("Genres of TV and their percentage on Netflix")
sns.barplot(y=genresTv,x=countTv,ax=ax2)
ax2.set_xlabel('Total Percentage (%)',labelpad=20, fontsize=20);
fig.tight_layout(pad=3.0)
fig.suptitle('Distribution of Movie and TV show with genres',y=1.0,fontsize=25,weight='bold');
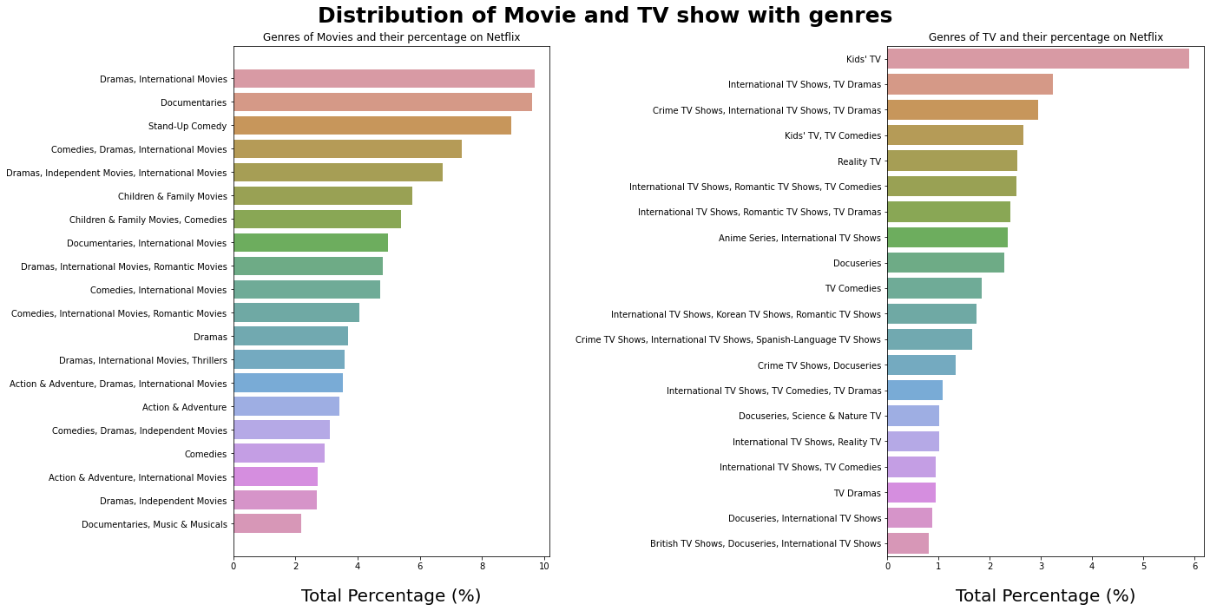
6. 대부분의 NetFlix 쇼는 아래와 같음
설명에 언급된 문자열/단어의 반복을 계산하기 위해
wordcloud 모듈을 사용합니다.
text = " ".join(review for review in netflixData.description)
wordcloud = WordCloud().generate(text)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()

더 흥미로운 통찰력
1. 2008년부터 2019년까지 미국에서 추가된 Netflix 콘텐츠
def content_country_year(df,country,yearStart,yearEnd):
countMv=[]
countTv=[]
for year in range(yearStart,yearEnd + 1):
nMv=(df.loc[(df.country.str.contains(country))& (df.release_year==year) & (df.type=='Movie')]).shape[0]
nTv=(df.loc[(df.country.str.contains(country))& (df.release_year==year) & (df.type=='TV Show')]).shape[0]
countMv.append(nMv)
CountTv.append(nTv)
return countMv, countTv
usMv = content_country_year(netflixData,'United States',2008,2019)[0]
usTv = content_country_year(netflixData,'United States',2008,2019)[1]
Total = [x + y for x, y in zip(usMv, usTv)]
plt.plot(range(2008,2020),usMv,'b--o')
plt.plot(range(2008,2020),usTv,'r--x');
plt.legend(['Movies', 'TV Shows'])
plt.ylabel('Count')
plt.xlabel('Year')
plt.title('Netflix content in United States added from 2008 to 2019', y = 1.05);
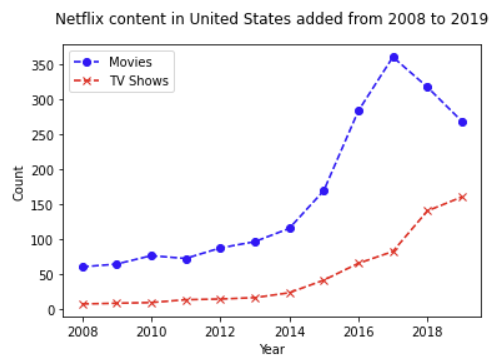
- 2014년 이후 Netflix는 더 많은 TV 콘텐츠를
제작하기 시작했습니다.
2017년 이후 미국에서 Netflix의 영화 콘텐츠는
쇠퇴하는 동시에 TV 콘텐츠는 급격히 증가하고 있습니다. - 2019년 즈음 Netflix가 미국의 TV 프로그램에
더 집중하고 있는 것으로 관찰되었습니다.
트렌드를 보면 영화보다 드라마가 더 많이 나올 것 같습니다.
2. Netflix에 등록된 영화의 평균 영화 재생 시간(미국 및 인도)
미국에서는 약 1.5시간, 인도에서는 약 2시간입니다.
그 이유는 인도 관객이 미국 관객에 비해
(볼리우드 영화가 더 길기 때문에)
장기 영화를 보는 것을 선호하기 때문일 수 있습니다.
# 미국 영화 재생 시간
usMovieLengthMin = netflixData.loc[(netflixData.type == 'Movie') & (netflixData.country == 'United States')].duration.str.replace(' min','')
usAverageMovieLength = (usMovieLengthMin.astype(float).mean())
print('미국 평균 영화 재생 시간 : {:0.2f} min'.format(usAverageMovieLength))
# 인도 영화 재생 시간
indMovieLengthMin = netflixData.loc[(netflixData.type == 'Movie') & (netflixData.country == 'India')].duration.str.replace(' min','')
indAverageMovieLength = (indMovieLengthMin.astype(float).mean())
print('인도 평균 영화 재생 시간: {:0.2f} min'.format(indAverageMovieLength))

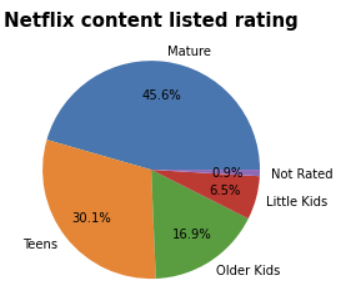
3. 다양한 등급의 Netflix 프로그램 배포
5개의 카테고리로 나열된 14개의 등급을
모두 분류해 보겠습니다
(어린 아이(7세 미만), 조금 나이 많은 어린이(7-13세),
십대(13-17세), 성인(17세 이상) 및 등급 없음(UR/NR))
# 모두 5가지 범주로 분류
littleKids = netflixData.rating.value_counts()['G'] +
netflixData.rating.value_counts()['TV-Y'] + netflixData.rating.value_counts()['TV-G']
olderKids = netflixData.rating.value_counts()['PG'] +
netflixData.rating.value_counts()['TV-Y7'] +
netflixData.rating.value_counts()['TV-Y7-FV'] +
netflixData.rating.value_counts()['TV-PG']
teens = netflixData.rating.value_counts()['TV-14'] +
netflixData.rating.value_counts()['PG-13']
mature = netflixData.rating.value_counts()['TV-MA'] +
netflixData.rating.value_counts()['NC-17'] +
netflixData.rating.value_counts()['R']
notRated = netflixData.rating.value_counts()['UR'] + netflixData.rating.value_counts()['NR']
plt.pie(x = [mature, teens, olderKids, littleKids, notRated],
labels=['Mature','Teens','Older Kids','Little Kids','Not Rated'],
autopct='%1.1f%%',radius=1,pctdistance=0.7)
plt.title('Netflix content listed rating',fontsize=15,weight='bold')
plt.show()
4. 가장 긴 영화와 가장 짧은 길이의 영화
longestMovie = netflixData.loc[netflixData.type=='Movie'].duration.str.replace('min','').astype(float).max()
shortestMovie= netflixData.loc[netflixData.type=='Movie'].duration.str.replace('min','').astype(float).min()
print('가장 긴 영화 시간 :', longestMovie)
print('가장 짧은 영화 시간 :', shortestMovie)

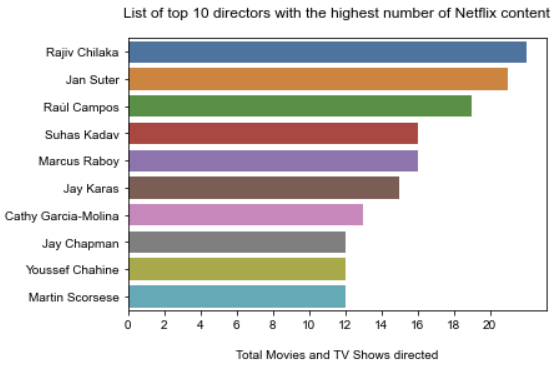
5. 가장 많은 Netflix 프로그램에 출연한 감독 및 배우
dirCountlist = pd.Series(netflixData.director.dropna().str.split(', ').sum()).value_counts()
dirCountlist
sns.barplot(y = dirCountlist.head(10).index, x = dirCountlist.head(10).values)
plt.xticks(range(0,22,2));
plt.xlabel('Total Movies and TV Shows directed',labelpad = 15)
sns.set_style('whitegrid')
plt.title('List of top 10 directors with the highest number of Netflix content', y=1.05);
# 상위 15명의 남/여배우 캐스팅
pd.Series(netflixData.cast.dropna().str.split(', ').sum()).value_counts().head(15)

추론 및 결론
넷플릭스 데이터를 이용해서
많은 흥미로운 추론을 이끌어냈으며,
그중 몇 가지를 요약하면 다음과 같습니다.
- Netflix의 주요 수익은 영화이며
주요 시장은 미국과 인도입니다.
그러나 미국에서는 최근 Netflix가
TV 프로그램에 더 집중하고 있습니다. - Netflix는 국가별로 콘텐츠 전략이 다릅니다.
예를 들어, 인도의 경우 영화 길이가 더 긴 콘텐츠,
일본의 애니메이션 시리즈,
한국의 로맨틱 쇼가 있습니다. - 70% 이상의 콘텐츠는 청소년 및 성인용입니다.
- 대부분의 콘텐츠는 금요일과 10월에서 1월 사이에
업로드됩니다.
이외에도 발견할 수 있는 정보는 매우 다양합니다.
다양한 아이디어를 가지고 좀 더 많은 인사이트를
발굴해 보세요.
여러분의 상상력을 믿어 보세요!!!!
'Python > 데이터 다루기' 카테고리의 다른 글
| 데이터 과학자가 알아야 할 가장 중요한 5가지 Python 기술 (0) | 2023.01.14 |
|---|---|
| Python의 Loop? NO! , Python의 Vectorization? OK!!! (1) | 2023.01.14 |
| Box Plot (분포에서 이상값 감지 및 제거) (0) | 2022.09.11 |
| 데이터 처리 시 알아야 할 7가지 메모리 최적화 기술 (1) | 2022.08.27 |
| Python에서 생산성을 높이는 최고의 팁 (0) | 2022.07.27 |
댓글