Python에는 시각적 개체를 만드는
여러 가지 방법이 있지만
그래프로 데이터를 탐색하는
가장 간단하고 효과적인 라이브러리는
Seaborn이라고 할 수 있습니다.
데이터 유형과 분석하려는 대상에 따라
생성할 수 있는 그래프의 "category"가 있습니다.
- 회귀 및 선형 - regplot, lineplot, lmplot
- 분포 - distplot , histplot
- 범주형 - 막대 그림, 상자 그림, 바이올린 그림, 산점도, 개수 그림
- 행렬 - 열 도표, 클러스터 도표
각 섹션에서 몇 개의 그래프를 선택하고
2개의 데이터 세트에서
흥미로운 인사이트를 발견할 수 있을지
살펴보겠습니다.
- titanic - 생존에 초점을 맞춘 타이타닉의 승객 정보
- tips - 팁 금액에 중점을 둔 레스토랑의 고객 정보
seaborn을 설치하고 시작하는 데
필요한 라이브러리로
Jupyter Notebook을 사용하겠습니다.
setup
1. Windows 명령줄 또는 Anaconda 셸을 통해 Seaborn 설치

2. Jupyter Notebook 로드 - pandas, seaborn 라이브러리 및 두 가지 예제 데이터 세트 가져오기
import seaborn as sns
import pandas as pd
titanic = sns.load_dataset("titanic")
tips = sns.load_dataset("tips")
데이터의 처음 5개 행 확인
titanic.head()
tips.head()
Seaborn plots 구문
대부분의 플롯에서 필요한 매개변수는
일반적으로 다음 형식입니다.
sns.plottype( data =Dataframe , x =columnname , y =columnname )
회귀 및 선 플롯
regplot
회귀 플롯(regplot)으로 시작하여
tips 데이터를 분석하여 tip 수와 청구 금액
사이의 상관관계를 확인합니다.
sns.regplot(data = tips, x = "total_bill", y = "tip" )
regplot을 통해서 두 변수 사이의 상관관계가
있음을 알 수 있습니다.
여기서 총 청구서가 많을수록
tip이 커지는 것을 알 수 있지만,
세 번째 변수를 포함하려는 경우
regplot은 더 이상의 분석을 제공할 수 없습니다.
이를 해결하기 위해서는
lmplot()을 이용하고,
한 축에 플롯 2 회귀 그래프를 생성하는 색조로
"smoker"를 추가할 수 있습니다.
sns.lmplot(data = tips, x = "total_bill", y = "tip" , hue = "smoker")
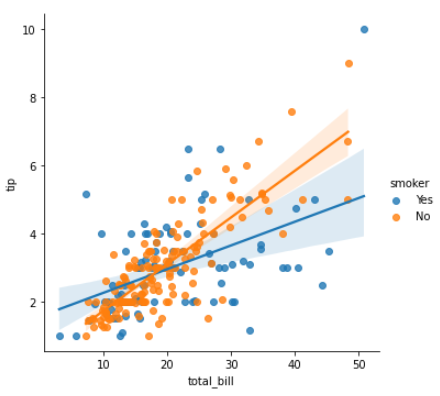
와우~~~~~~!
비흡연자(vs 흡연자)는 청구서가 인상될수록
팁을 더 많이 낸다는 것을 알 수 있습니다.
분포
분포 또는 히스토그램 플롯의 경우
설정된 범위로 버킷화(또는 비닝)되고
계산되는 x-값만 필요로 합니다.
displot
타이타닉의 "연령" 분포를 분석해 보겠습니다.
여기에 색상을 추가하여 "성별"을 추가해서,
남성과 여성 연령의 차이를 볼 수 있습니다.
sns.displot(data = titanic , x = "age" , hue = "sex", hue_order = ['female', 'male'])
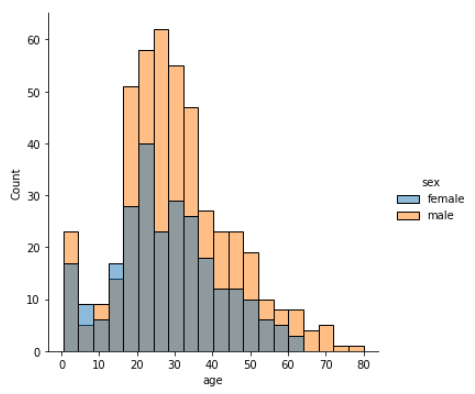
displot은 탑승한 사람들의 대부분이
18-35세 정도임을 보여주며,
색상을 통해 더 많은 남성(vs 여성)이
탑승하고 있음을 알 수 있습니다.
우리는 또한 여성 색상을 앞쪽으로 가져오고
남성 색상을 두 번째로 가져오기 위해
hue_order를 변경했습니다.
범주형
범주형 플롯의 경우에는 종류가 너무 많아,
가장 많이 사용하는 몇 가지 키를 보여 드리겠습니다.
boxplot
sns.boxplot(data = titanic, x = "sex", y= "age")
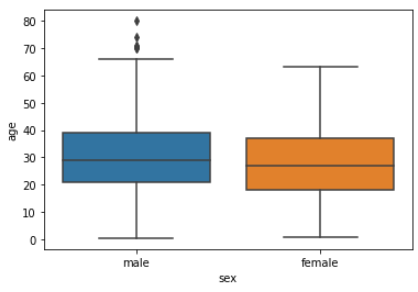
boxplot은 displot과 유사한 정보를 보여주지만
남성 연령(약 68세 이상)에 대한
일부 이상값도 확인할 수 있습니다.
violinplot
가장 좋아하는 플롯 중 하나인
바이올린 플롯으로 상자 플롯을
향상할 수 있는지 살펴보겠습니다.
sns.violinplot(data = titanic, x = "sex", y="age")

오오~~~~!
나이의 밀도(분포)를 볼 수 있지만
색상으로 "생존(survival)"하는
다른 열을 추가하면 어떻게 될까요?
sns.violinplot(data = titanic, x = "sex", y="age", hue = "survived", split=True)
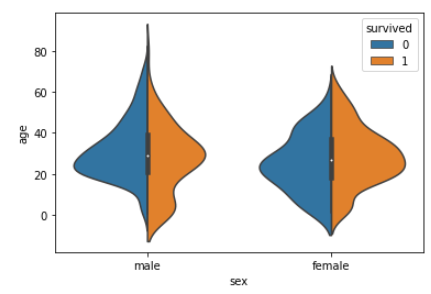
하나의 그래프에 여러 분석 군을 분류하여
분석이 가능합니다.
색상에 "survival"을 추가하고,
이것을 더 잘 비교하기 위해
중간 아래로 플롯을 분할합니다(split = True).
분석할 것이 많지만 간단히 살펴보면,
젊은 남성이 생존의 더 높은 변화를 보이는 것처럼 보입니다.
행렬
heatmap
행렬 리스트에서 가장 유용한 플롯은
단연 히트맵(heatmap)입니다.
Note: corr()을 사용하여 상관 행렬을 빠르게 만들 수 있습니다.
titanic.corr(). head()

이제 이러한 상관관계의 히트맵을 만들 수 있습니다.
sns.heatmap(data = titanic.corr())
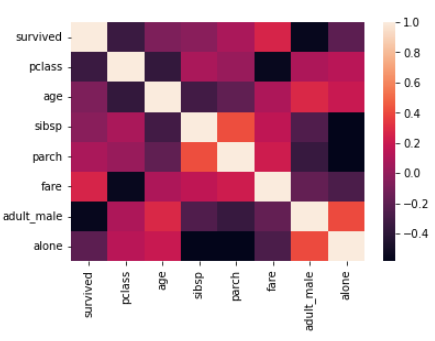
꽤 좋아 보이지만 더 좋게 만들어 보겠습니다.
- 최솟값과 최댓값(vmin/vmax)을 더 잘 볼 수 있도록 값을 0 -> 1 사이로 설정
- 블록 내부에 있을 값에 주석 달기(주석)
- 색상 팔레트를 변경하여 색상 변화를 더 잘 볼 수 있습니다(cmap).
sns.heatmap(data = titanic.corr(), vmin = -1, vmax = 1, annot=True , cmap = "Spectral")
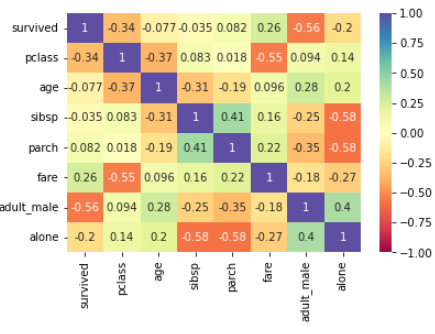
이 히트맵에서 몇 가지 작은 양의 상관관계와
음의 상관관계를 볼 수 있지만
핵심은 혼자와 성인 남성 사이의 양의 상관관계와
성인 남성과 생존자 사이의 음의 상관관계입니다.
결론
Seaborn에서 사용할 수 있는
몇 가지 플롯만 강조했지만
이번 포스팅을 통해서 시각화를 이해하는 데
기초적인 도움이 많이 되었으면 합니다.
'Python > 데이터 시각화' 카테고리의 다른 글
| 단순한 3단계 프로세스로 Matplotlib 차트 개선 (0) | 2022.07.27 |
|---|---|
| Seaborn 라이브러리를 활용한 시각화 Best 8 (0) | 2022.05.28 |
| 막대그래프에 도형(화살표) 삽입하기 (0) | 2022.04.17 |
| 막대그래프에 도형(타원) 삽입하기 (0) | 2022.04.16 |
| 워드 클라우드(Word Cloud) 생성하기(with 파이썬 DataFrame) (0) | 2022.02.28 |




댓글