Otto Classification Challenge라는 유명한 Kaggle 대회 이후 데이터 과학에서 인기를 얻게 되었죠.
R의 "xgboost"에 대한 최신 구현은 2015년 8월에 시작되었어요.
R에서 xgboost를 사용하는 매우 간단한 접근 방식에 대해서 설명할게요.
What is XGBoost?
Extreme Gradient Boosting(xgboost)은 그래디언트 부스팅 프레임워크와 유사하지만 더 효율적이에요.
선형 모델과 트리 학습 알고리즘이 모두 있어요.
속도를 높이는 것은 단일 시스템에서 병렬 계산을 수행할 수 있는 능력입니다.
이것은 xgboost를 기존 그래디언트 부스팅 구현보다 10배 이상 빠르게 만들어요.
회귀, 분류 및 순위 지정을 포함한 다양한 목적 함수도 지원합니다.
통상적으로 높은 예측력을 보이는 알고리즘은 구현 속도가 상대적으로 느리다는 단점이 있어요.
그렇기 때문에 "xgboost"는 많은 경쟁에 이상적이라고 할 수 있죠. 또한 교차 검증을 수행하고 중요한 변수를 찾기 위한 추가 기능도 있어요. 모델을 최적화하기 위해 제어해야 하는 많은 파라미터(parameter)가 있어요.
아래 글에서 차차 소개해 드리도록 할게요.
XGBoost 사용을 위한 데이터 준비
중요!!!! XGBoost는 숫자형 벡터에서만 작동합니다. 데이터 유형에 대해서 작업을 해야 합니다!
모든 형태의 데이터를 숫자형 벡터로 변환해야 합니다.
범주형 변수를 숫자형 벡터로 변환하는 간단한 방법은 One Hot Encoding입니다.
범주형 변수를 0과 1의 값을 가지는 dummy 변수로 변환하는 recoding이라고 이해하시면 돼요.
R에서 One Hot Encoding은 매우 쉬워요. One Hot Encoding 단계(아래 표시)는 기본적으로 해당 변수의 모든 가능한 값에 플래그를 사용하여 희소 행렬(sparse matrix)을 만듭니다. 희소 행렬은 대부분의 값이 0인 행렬을 의미하고요.
반대로, dense matrix는 대부분의 값이 0이 아닌 행렬을 의미합니다.
예를 들어, 'campaign'이라는 데이터 세트가 있고 Target 변수(종속변수, y변수 모두 동일한 의미입니다.)를 제외한 모든 범주형 변수를 이러한 플래그로 변환하려고 한다고 가정해 보죠.
R에서는 아래와 같은 방법으로 희소 행렬을 생성합니다.
# 희소 행렬 생성을 위한 R코드 ## 아직은 실제로 실행되지 않는 R코드입니다. ## 오직 설명을 위해서만 작성된 코드입니다. sparse_matrix <- sparse.model.matrix(response ~ .-1, data = campaign)
이제 이 코드를 다음과 같이 분해해 보겠습니다.
"sparse.model.matrix"는 희소행렬 형태로 만드는 함수이고, 괄호 안의 다른 모든 입력은 파라미터입니다.
"response"는 이 명령문이 "response" 변수는 변경하지 말아야 하는 변수라고 알려 주는 파라미터입니다.
"-1"은 이 명령이 첫 번째 열로 만드는 추가 열을 제거합니다. "-1"은 "sparse.model.matrix" 사용 시 첫 번째 열에 기본적으로 생성되는 아무 의미 없는 열입니다.
마지막은 데이터 세트 이름을 지정하는 파라미터입니다.
Target 변수도 변환하려면 아래 코드를 사용할 수 있어요.
## 아직은 실제로 실행되지 않는 R코드입니다. ## 오직 설명을 위해서만 작성된 코드입니다. output_vector = df[,response] == "Responder"
코드가 수행하는 작업은 다음과 같습니다.
output_vector를 0으로 설정
response 열의 값이 "Responder"인 행에 대해("==" 비교 결과가 TRUE이면) output_vector를 1로 설정
output_vector를 최종 반환
R에서 Xgboost를 사용한 모델 구축
<Step 1: 모델 구축에 필요한 라이브러리 설치 및 로드>
install.packages("xgboost") # xgboost 패키지가 설치되어 있으면 제외 library(xgboost) # xgboost 패키지 로딩
<Step 2 : Load the dataset>
여기에서는 또 다른 기계학습 알고리즘인 "LightGBM" 패키지 안에 있는
은행 데이터를 가지고 고객의 정기예금 가입여부를 Target 변수로 하여 모델을 구축하는 실습을 진행할게요.
# LightGBM 패키지에 있는 bank 데이터 가져오기 data(bank, package = "lightgbm") dim(bank) 4521개의 데이터와 17개의 변수 보유 head(bank) # 데이터 구조 확인
<Step 3 : 데이터 전처리 및 희소행렬 변환>
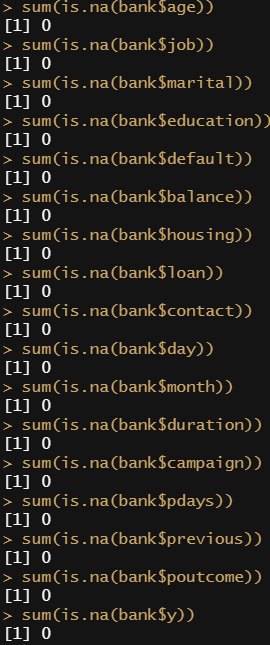
# 결측 데이터(NA) 유무 확인 모든 항목의 NA는 없음을 확인 # 범주형 변수와 숫자형 변수 확인 str(bank) 17개의 변수 중 숫자형 변수 7개, 범주형 변수 9개, Target변수 1개로 구성되어 있음 # Target변수를 0과 1로 변환하기 install.packages("car") # 유용한 car 패키지 설치 library(car) # car 패키지 로드
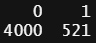
dt_xgboost <- bank # 원본 데이터를 변경하지 않기 위해 복사 dt_xgboost$y <- recode(dt_xgboost$y, "'no'=0; 'yes'=1") # Target변수를 0과 1로 변환 str(dt_xgboost$y)
table(dt_xgboost$y)
# 변환 확인 !
install.packages("Matrix") # sparse matrix 생성에 필요한 패키지 설치, 이미 설치되어 있으면 생략 library(Matrix) # Matrix 패키지 로드
# sparse matrix 생성 dt_xgb_sparse_matrix <- sparse.model.matrix(y~. -1, data = dt_xgboost)
# train data set sampling index 정의 train_index <- sample(1:nrow(dt_xgb_sparse_matrix), 2500)
# train 및 test data set 및 label data 생성 train_x <- dt_xgb_sparse_matrix[train_index,] test_x <- dt_xgb_sparse_matrix[-train_index,] train_y <- dt_xgboost[train_index,'y'] test_y <- dt_xgboost[-train_index,'y']
## xgboost 알고리즘 사용을 위한 데이터 형태 변환 dtrain <- xgb.DMatrix(data = train_x, label= as.matrix(train_y)) dtest <- xgb.DMatrix(data = test_x, label= as.matrix(test_y))
위에서 적용한 예제 코드를 보면, 아마 xgboost 모델에서 사용되는 다양한 파라미터에 대해 매우 궁금해하실 것 같아요.
기본적으로 매개변수에는 일반 매개변수, 부스터 매개변수 및 작업 매개변수의 세 가지 유형으로 구분할 수 있어요.
일반 파라미터는 부스팅을 수행하는 데 사용하는 부스터를 나타냅니다. 가장 흔히 사용되는 것으로는 트리 또는 선형 모델이 있어요.
부스터 매개변수는 선택한 부스터에 따라 다르고요.
학습 시나리오를 결정하는 학습 작업 파라미터, 예를 들어 regression 작업은 순위 지정 작업과는 다른 파라미터를 사용할 수 있어요.
이러한 파라미터는 매우 중요하기 때문에 자세히 이해하셔야 해요!
이것은 xgboost 알고리즘 구현에 있어서 가장 중요합니다!!!
<General Parameters>
silent : default값은 0. 실행 중인 메시지를 인쇄하려면 0을 지정해야 하고, 어떤 출력도 없게 하려면 1을 지정
booster : default값은 gbtree. 사용할 부스터를 지정해야 합니다: gbtree(트리 기반) 또는 gblinear(선형 함수).
num_pbuffer : xgboost에 의해 자동으로 설정되며 사용자가 설정할 필요가 없습니다.
num_feature : xgboost에 의해 자동으로 설정되며 사용자가 설정할 필요가 없습니다.
<Booster Parameters>
tree에 특화된 매개변수 -
eta: default값은 0.3으로 설정. 과적합을 방지하기 위해 업데이트에 사용되는 단계 크기 축소를 지정해야 합니다. 각 부스팅 단계 후에 새로운 feature의 가중치를 직접 얻을 수 있어요. 그리고 eta는 실제로 feature 가중치를 축소하여 부스팅 프로세스를 보다 보수적으로 만들 수 있어요. 범위는 0에서 1까지입니다. 낮은 eta 값은 모델이 과적합에 대해 더 강건(robust)할 수 있다는 것을 의미합니다.
gamma: default값은 0으로 설정. 트리의 리프 노드에서 추가 파티션을 만드는 데 필요한 최소 손실 감소를 지정해야 합니다. 범위는 0 ~ ∞이고, gamma가 클수록 알고리즘이 더 보수적입니다.
max_depth: default값은 6으로 설정. 나무의 최대 깊이를 지정해야 합니다. 범위는 1에서 ∞입니다.
min_child_weight : default값은 1로 설정되어 있습니다. 자식에게 필요한 인스턴스 가중치(hessian)의 최소 합을 지정해야 합니다. 트리 분할 단계에서 인스턴스 가중치 합계가 min_child_weight보다 작은 리프 노드가 생성되면 빌드 프로세스에서 추가 분할을 포기합니다. 선형 회귀 모드에서 이것은 단순히 각 노드에 있어야 하는 최소 인스턴스 수에 해당합니다. 클수록 알고리즘이 더 보수적이고, 범위는 0 ~ ∞입니다.
max_delta_step: default값은 0으로 설정. 각 트리의 가중치 추정이 허용되는 최대 델타 단계입니다. 값이 0으로 설정되면 제약 조건이 없음을 의미합니다. 양수 값으로 설정하면 업데이트 단계를 보다 보수적으로 만드는 데 도움이 될 수 있습니다. 일반적으로 이 매개변수는 필요하지 않지만 클래스가 극도로 불균형한 경우 로지스틱 회귀에 도움이 될 수 있습니다. 값을 1-10으로 설정하면 업데이트를 제어하는 데 도움이 될 수 있습니다. 범위는 0에서 ∞입니다.
subsample : default값은 1로 설정. 훈련 인스턴스의 서브 샘플 비율을 지정해야 합니다. 0.5로 설정하면 XGBoost가 데이터 인스턴스의 절반을 무작위로 수집하여 트리를 성장시키고 과적합을 방지합니다. 범위는 0~1입니다.
colsample_bytree : default값은 1로 설정되어 있습니다. 각 트리를 구성할 때 열의 서브 샘플 비율을 지정해야 합니다. 범위는 0~1입니다.
<Learning Task Parameters>
base_score: default값은 0.5로 설정. 모든 인스턴스의 초기 예측 점수
objective : default값은 reg:linear로 설정. 선형 회귀, 로지스틱 회귀, 포아송 회귀 등 원하는 학습자 유형을 지정
eval_metric: 검증 데이터에 대한 평가 지표 지정. 기본 지표는 목표(회귀의 경우 rmse, 분류의 경우 오류, 순위의 경우 평균 정밀도)에 따라 할당
seed: 동일한 출력 세트를 재생하기 위해 시드 지정
xgboost의 고급 기능
다른 기계 학습과 비교할 때 xgboost 구현이 정말 간단하다는 것을 알았을 거예요.
지금까지 한 모든 작업을 수행했다면 이미 예측 분류 모델을 구축한 거예요.
한 단계 더 나아가 모델에서 변수 중요도를 찾고 변수 목록의 하위 집합을 찾아보죠.
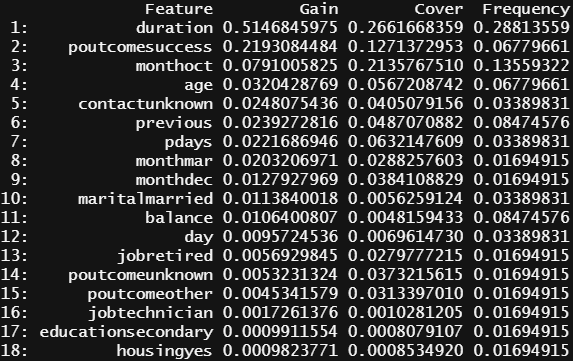
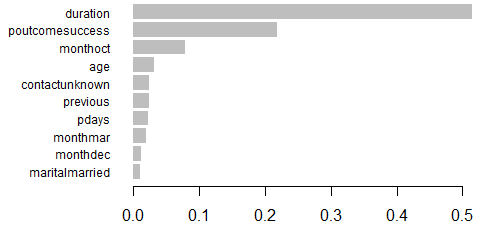
# 실제 나무가 어떻게 생겼는지.... model <- xgb.dump(xgb, with_stats = T) model[1:10] # 모델의 상위 10개 노드를 인쇄합니다. # 모형에 활용된 feature명 확인 names <- dimnames(dtrain)[[2]] names # feature importance matrix 계산 importance_matrix <- xgb.importance(names, model = xgb) importance_matrix # feature importance matrix 그래프 그리기 xgb.plot.importance(importance_matrix[1:10,])
feature importance 결과를 보시면 아시겠지만, 많은 변수가 우리 모델에서 사용할 가치가 없어요.
이러한 변수를 편리하게 제거하고 모델을 다시 실행할 수 있어요.
마치며...
이번 포스팅을 잘 따라가시면, 매우 간단한 xgboost 모델을 확실히 구축할 수 있어요.
혹시라도 비교 가능한 모델과 비교해 보실 수 있다면, 이 알고리즘의 속도를 보면 놀랄 거예요.
이번 포스팅에서 R에서 xgboost 알고리즘을 사용하는 다양한 측면에 대해 설명드렸어요.
가장 중요한 것은 데이터 유형을 숫자로 변환해야 한다는 것입니다. 그렇지 않으면 이 알고리즘이 작동하지 않습니다.
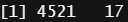




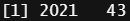




댓글