1. 객체의 메모리 사용량 확인하기
알아두면 데이터 분석 시
시간을 절약할 수 있는
16가지 Python 및 Pandas Hacks 중
첫 번째는 객체의 메모리 사용량을
확인하는 것입니다.
import sys
import pandas as pd
titanic = pd.read_csv("d:/titanic.csv")
sys.getsizeof(titanic)

2. 문자열을 바이트로 변환하기
알아두면 데이터 분석 시
시간을 절약할 수 있는
16가지 Python 및 Pandas Hacks 중
두 번째는 문자열을 바이트로
변환하는 것입니다.
s = “I want to convert this string to byte”
s.encode( )

3. 두 개의 리스트 개체 병합하기
알아두면 데이터 분석 시
시간을 절약할 수 있는
16가지 Python 및 Pandas Hacks 중
세 번째는 두 개의 리스트 개체 병합하기
입니다.
a = [1,2,3]
b = [10,20,30]
a.extend(b)
a

4. 리스트에서 가장 긴 문자열과 가장 짧은 문자열 검색하기
알아두면 데이터 분석 시
시간을 절약할 수 있는
16가지 Python 및 Pandas Hacks 중
네 번째는 리스트에서 가장 긴 문자열과
가장 짧은 문자열 검색하기입니다.
word_list = ["I", "am", "handsome"]
max(word_list, key=len)

word_list = ["I", "am", "handsome"]
min(word_list, key=len)

5. 문자열에서 문자의 발생 횟수 계산하기
알아두면 데이터 분석 시
시간을 절약할 수 있는
16가지 Python 및 Pandas Hacks 중
다섯 번째는 문자열에서
문자의 발생 횟수 계산하기입니다.
"please find the occurrence of a in this sentence".count('a')

6. 같지 않은 수의 값을 변수에 압축 해제하기
알아두면 데이터 분석 시
시간을 절약할 수 있는
16가지 Python 및 Pandas Hacks 중
여섯 번째는 같지 않은 수의 값을
변수에 압축 해제하기입니다.
x, y, *z = ['a', 'b', 'c', 'd', 'e', 'f', 'g']
x
# 'a'
y
# 'b'
z
# [ 'c', 'd', 'e', 'f', 'g' ]
7. 리스트 병합하기
알아두면 데이터 분석 시
시간을 절약할 수 있는
16가지 Python 및 Pandas Hacks 중
일곱 번 째는 리스트 병합하기입니다.
lst = [[1,2], [3,4], [5,6]]
flattened_lst = [ i for j in lst for i in j ]
flattened_lst

8. 리스트의 모든 조합 출력하기
알아두면 데이터 분석 시
시간을 절약할 수 있는
16가지 Python 및 Pandas Hacks 중
여덟 번 째는
리스트의 모든 조합 출력하기입니다.
from itertools import combinations, combinations_with_replacement
lst= [1,2,3]
list(combinations(lst,2))

list(combinations_with_replacement(lst,2))

list(combinations(lst,3))
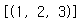
9. 천 단위 구분 기호
알아두면 데이터 분석 시
시간을 절약할 수 있는
16가지 Python 및 Pandas Hacks 중
아홉 번 째는 천 단위 구분 기호입니다.
N = 5384200
commaSeparatedN = f'{N:,}'
commaSeparatedN
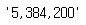
10. 리스트의 모든 요소 합계 또는 곱하기
알아두면 데이터 분석 시
시간을 절약할 수 있는
16가지 Python 및 Pandas Hacks 중
열 번 째는 리스트의 모든 요소
합계 또는 곱하기입니다.
from numpy import prod
from functools import reduce
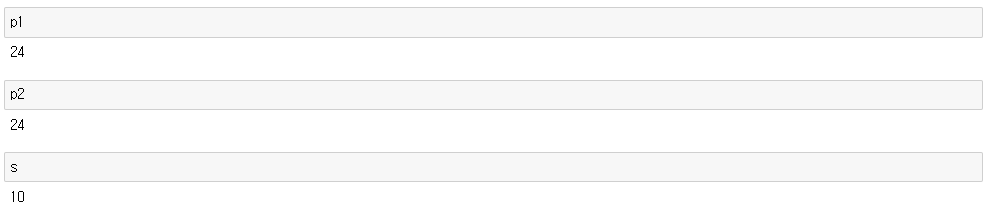
lst = [1,2,3,4]
p1 = prod(lst)
p2 = reduce((lambda x, y: x * y), lst)
s = sum(lst)
11. 몫과 나머지 구하기
알아두면 데이터 분석 시
시간을 절약할 수 있는
16가지 Python 및 Pandas Hacks 중
열한 번째는 몫과 나머지 구하기입니다.
q, r= divmod(25,6)

12. 리스트에서 가장 자주 사용되는 요소 구하기
알아두면 데이터 분석 시
시간을 절약할 수 있는
16가지 Python 및 Pandas Hacks 중
열두 번째는 리스트에서
가장 자주 사용되는 요소 구하기입니다.
from collections import Counter
lst = [1,2,3,1,1,1,10,20,3,4,5,6]
mostFreqE = Counter(lst).most_common()[0][0]
mostFreqE
13. 여러 조건에 따라 딕셔너리 정렬하기
알아두면 데이터 분석 시
시간을 절약할 수 있는
16가지 Python 및 Pandas Hacks 중
열세 번째는 여러 조건에 따라
딕셔너리 정렬하기입니다.
d = {"HA":5, "AN":5, "AK":10, "STATO":0 , "HEW":10}
lst = sorted(d.items( ), key = lambda x: (x[1], len(x[0]), x[0]))
## key = lambda x: (x[1], len(x[0]), x[0])는
## d.items( )의 정렬 순서가
## 첫 번째는 d.items( )에 있는 value에 의한 정렬
## 두 번째는 d.items( )에 있는 key의 길이에 의한 정렬
## 세 번째는 d.items( )에 있는 key의 알파벳 순서에 의한 정렬
## 임을 의미
lst
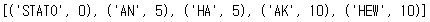
# 리스트를 딕셔너리 형태로 변환
new_d = {k:v for k,v in lst}
new_d
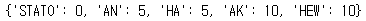
14. 행렬 전치(Transpose)
mtrx = [[1,2,3], [3,4,5], [5,6,7]]
lst = list(list(x) for x in zip(*mtrx))
lst
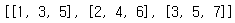
15. Python 3.10용 Switch 문 사용
def get_mood(day):
match day:
case ‘Monday’:
return ‘Oh…’
case ‘Thursday’:
return ‘Getting close!’
case ‘Friday’:
return ‘Almost there!’
case ‘Saturday’ | ‘Sunday’:
return ‘Weekend!!!’
case _:
return ‘Meh…’
16. 리스트의 각 요소에 여러 pandas 데이터 프레임 로드하기
import glob
import pandas as pd
# D드라이브에 확장자가 .csv인 파일을 모두 가져와 리스트에 저장
files = glob.glob('d:\*.csv')
dfList= [pd.read_csv(file) for file in files]
'Python > 데이터 다루기' 카테고리의 다른 글
| Python에서 Lambda 함수를 사용하는 5가지 팁 (0) | 2022.06.04 |
|---|---|
| 항목에 쉼표(,)를 포함하고 있는 CSV 파일 읽기 (0) | 2022.05.24 |
| 데이터 분석의 70%를 처리할 수 있는 10가지 Python 작업 (0) | 2022.05.21 |
| Python에서 JSON을 사용하는 방법(for 초급자) (0) | 2022.05.13 |
| JSON에 대한 소개 (0) | 2022.05.08 |
댓글