(※ 참고로 tidyr 패키지는 reshape2 패키지보다 더 새로운 인터페이스 패키지입니다.)
※ 위의 2가지 이외에 다른 많은 방법들이 있는데,
여기에서 다루지 않고,
소개만 하고 넘어갈게요.
첫 번째는 reshape() 함수예요.
혼란스러울 수 있는데,
이것은 reshape2 패키지의 일부가 아닌
R에 기본적으로 설치되어 있는 함수예요.
두 번째는 stack()와unstack() 함수입니다.
연습 데이터 생성
아래 2개의 데이터 프레임은 동일한 데이터를 보유하고 있지만,
와이드 및 롱 형식으로 데이터 표현방식이 다를 뿐이에요.
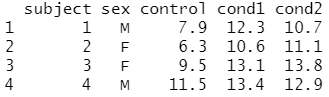
우선 와이드 형식의 데이터 프레임을 생성해 볼게요.
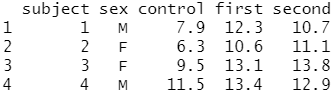
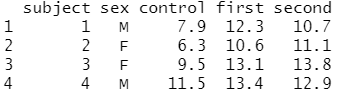
# 와이드(wide) 형식의 데이터 프레임 생성 olddata_wide <- read.table(header=TRUE, text=' subject sex control cond1 cond2 1 M 7.9 12.3 10.7 2 F 6.3 10.6 11.1 3 F 9.5 13.1 13.8 4 M 11.5 13.4 12.9 ')
# olddata_wide 데이터에 대한 구조 파악 str(olddata_wide)
olddata_wide는 데이터 프레임이며,
4개의 관측치와 5개의 변수로 구성되어 있다는 것을 알 수 있어요.
subject 변수가 수치형 변수로 되어 있는데,
이후 분석을 위해서 factor형으로 변환할게요.
# subject 변수를 factor형으로 변환 olddata_wide$subject <- factor(olddata_wide$subject)
# 변환 후 olddata_wide 데이터에 대한 구조 파악 str(olddata_wide)
subject에 대한 변수형이 4개의 수준을 가지는 factor형으로 변환되었음을 확인할 수 있어요.
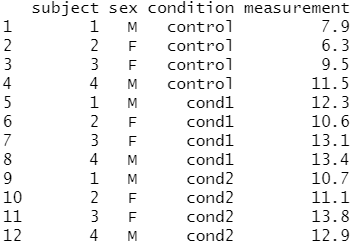
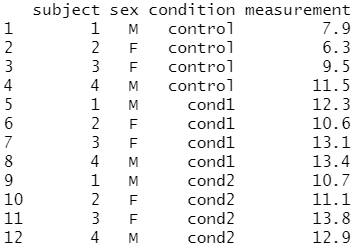
다음은 롱 형식의 데이터 프레임을 생성해 볼게요.
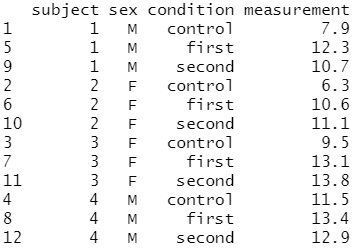
# 롱(long) 형식의 데이터 프레임 생성 olddata_long <- read.table(header=TRUE, text=' subject sex condition measurement 1 M control 7.9 1 M cond1 12.3 1 M cond2 10.7 2 F control 6.3 2 F cond1 10.6 2 F cond2 11.1 3 F control 9.5 3 F cond1 13.1 3 F cond2 13.8 4 M control 11.5 4 M cond1 13.4 4 M cond2 12.9 ')
# olddata_long 데이터에 대한 구조 파악 str(olddata_long)
olddata_long 은 데이터 프레임이며,
12개의 관측치와 4개의 변수로 구성되어 있다는 것을 알 수 있어요.
subject 변수가 수치형 변수로 되어 있는데,
이후 분석을 위해서 factor형으로 변환할게요.
# subject 변수를 factor형으로 변환 olddata_long$subject <- factor(olddata_long$subject)
# 변환 후 olddata_long데이터에 대한 구조 파악 str(olddata_long)
subject에 대한 변수형이 4개의 수준을 가지는 factor형으로 변환되었음을 확인할 수 있어요.
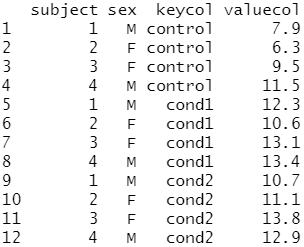
# gather() 함수의 주요 인수: # - data: Data object # - key: 데이터 열의 이름으로 만들어진 새로운 키(key) 열의 이름 # - value: 새로운 값 열의 이름 # - ...: 값을 포함하는 소스 열의 이름 # - factor_key: 새 키 열을 factor로의 처리 여부













댓글