본 포스팅은 R for Data Science 를 기반으로 작성되었습니다.
1. 소개
이 장에서는 좋은 그래픽을 만드는 데 필요한 도구에 중점을 둡니다. 이번 장을 학습할 때는 일반 시각화 책과 함께 사용하는 것이 좋습니다. 시각화를 만드는 방법이 아니라 효과적인 그래픽을 만들기 위해 생각해야 하는 것에 중점을 둡니다.
1.1. 전제 조건
ggplot2 패키지에 초점을 맞출 것입니다. 또한 데이터 조작을 위해 약간의 dplyr와 ggrepel 및 viridis를 포함한 몇 가지 ggplot2 확장 패키지를 사용할 것입니다. 여기에서는 로드하는 대신 :: 표기법을 사용하여 해당 기능을 참조합니다. 이렇게 하면 ggplot2에 내장된 기능과 다른 패키지에서 가져온 기능을 명확히 구별하는 데 도움이 됩니다. 패키지가 아직 없는 경우 install.packages()를 사용하여 해당 패키지를 설치해야 합니다.
library(tidyverse)
2. 라벨
탐색 그래픽을 설명 그래픽으로 변경할 때 가장 쉽게 시작할 수 있는 방법은 좋은 라벨을 사용하는 것입니다. labs() 함수를 사용하여 라벨을 추가합니다. 이 예에서는 플롯 제목을 추가합니다.
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = class)) +
geom_smooth(se = FALSE) +
labs(title = "Fuel efficiency generally decreases with engine size")
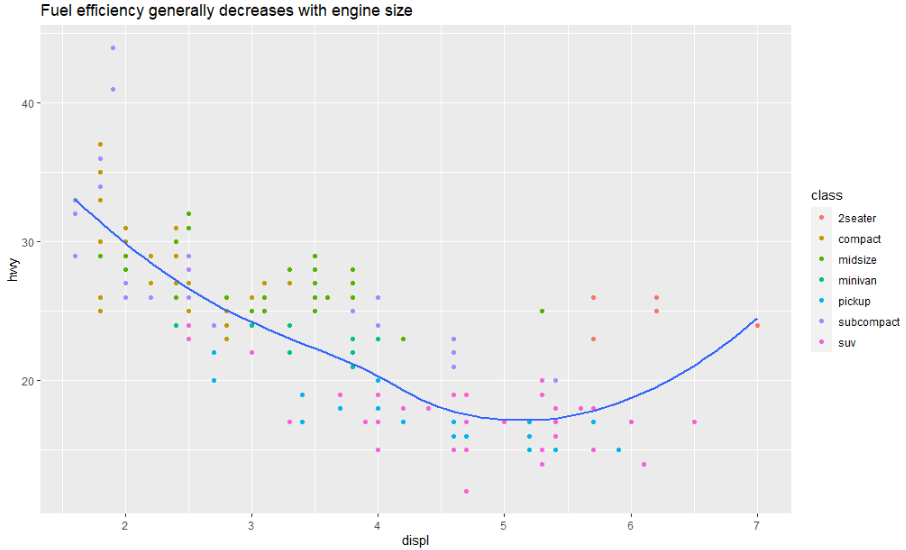
제목의 목적은 주요 결과를 요약하는 것입니다. 줄거리가 무엇인지 설명하는 제목("엔진 배기량 대 연비의 산점도")은 피하는게 좋습니다.
더 많은 텍스트를 추가해야 하는 경우 ggplot2 패키지 2.2.0 이상에서 사용할 수 있는 두 가지 다른 유용한 라벨이 있습니다.
- 자막(subtitle)은 제목 아래에 작은 글꼴로 세부 정보를 추가합니다.
- 캡션(caption)은 데이터 소스를 설명하는 데 자주 사용되고, 주로 플롯의 오른쪽 하단에 텍스트로 추가합니다.
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = class)) +
geom_smooth(se = FALSE) +
labs(
title = "Fuel efficiency generally decreases with engine size",
subtitle = "Two seaters (sports cars) are an exception because of their light weight",
caption = "Data from fueleconomy.gov"
)
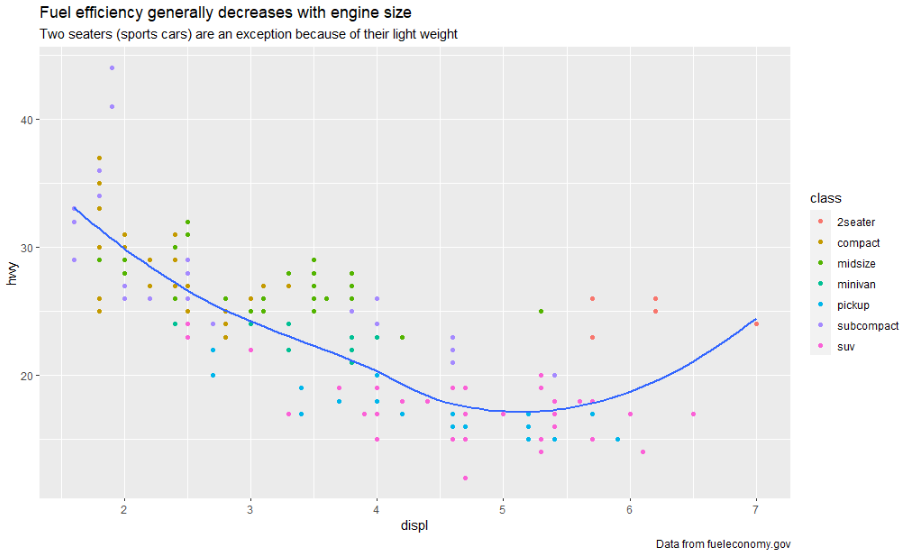
labs() 함수를 사용하여 축 및 범례 제목을 바꿀 수도 있습니다. 일반적으로 짧은 변수 이름을 더 자세한 설명으로 바꾸고 단위를 포함하는 것이 좋습니다.
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
geom_smooth(se = FALSE) +
labs(
x = "Engine displacement (L)",
y = "Highway fuel economy (mpg)",
colour = "Car type"
)
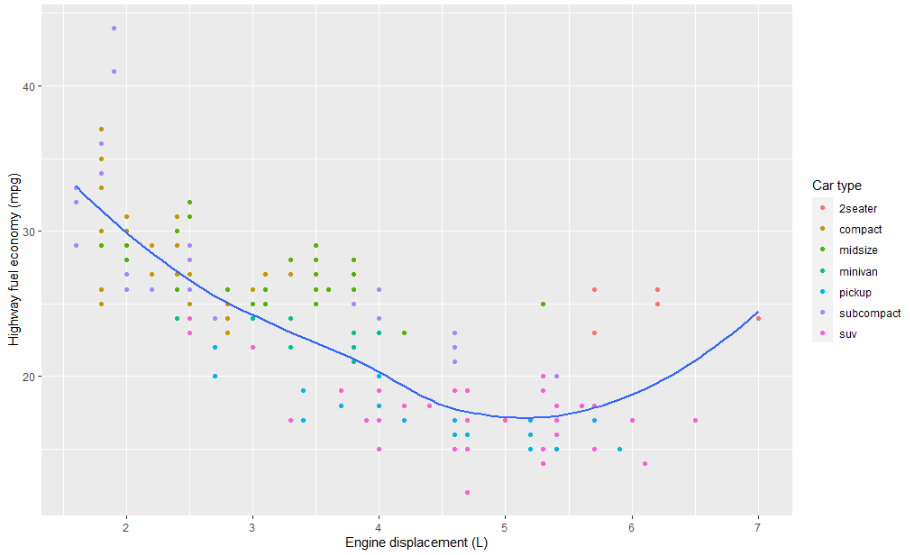
텍스트 문자열 대신 수학 방정식을 사용할 수도 있습니다. ""를 quote()으로 전환합니다. ?plotmath를 입력하여 사용 가능한 옵션을 확인할 수 있습니다.
df <- tibble(
x = runif(10),
y = runif(10)
)
ggplot(df, aes(x, y)) +
geom_point() +
labs(
x = quote(sum(x[i] ^ 2, i == 1, n)),
y = quote(alpha + beta + frac(delta, theta))
)
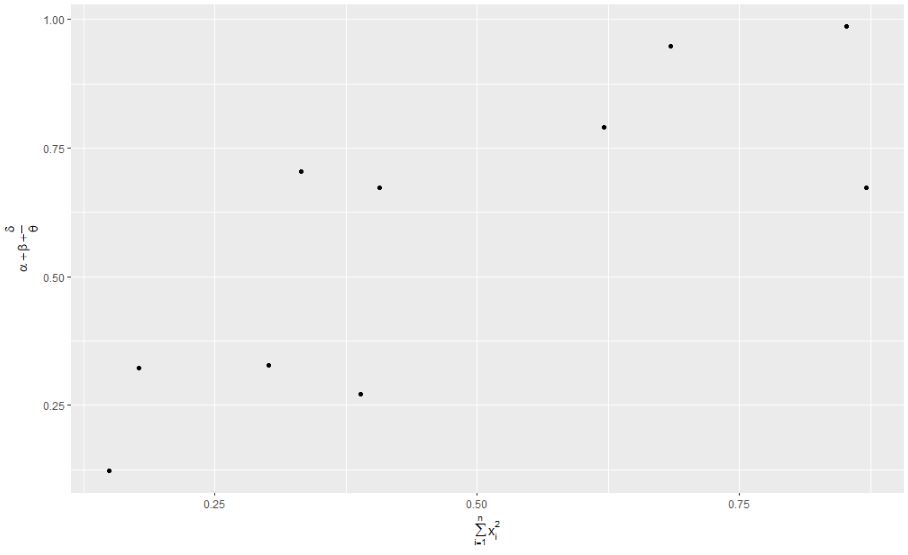
3. 주석
플롯의 주요 구성 요소에 라벨을 지정하는 것 외에도 개별 관찰 또는 관찰 그룹에 라벨을 지정하는 것이 종종 유용할 때가 있습니다. 사용할 수 있는 첫 번째 도구는 geom_text()입니다. geom_text()는 geom_point()와 유사하지만 추가적인 미학적 요소인 라벨이 있습니다. 이를 통해 플롯에 텍스트 라벨을 추가할 수 있습니다.
두 가지 가능한 라벨 소스가 있습니다. 먼저 라벨을 제공하는 tibble이 있을 수 있습니다. 아래 그림은 그다지 유용하지 않지만 유용한 접근 방식을 보여줍니다. dplyr로 각 클래스에서 가장 효율적인 자동차를 뽑은 다음 플롯에 라벨을 지정해 보겠습니다.
best_in_class <- mpg %>%
group_by(class) %>%
filter(row_number(desc(hwy)) == 1)
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
geom_text(aes(label = model), data = best_in_class)
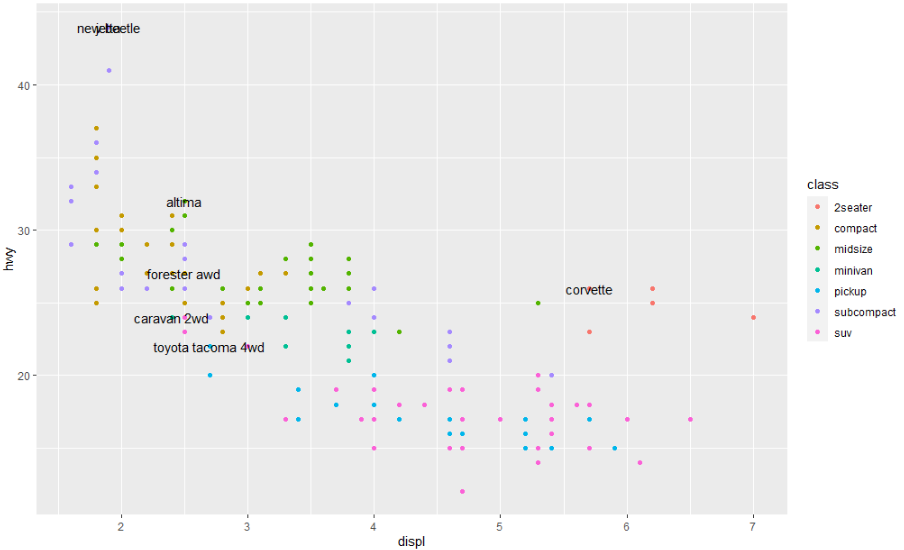
위의 그래프는 라벨들 끼리 서로 겹치고 점과도 겹치기 때문에 읽기가 매우 어렵습니다. 텍스트 뒤에 직사각형을 그리는 geom_label()로 변경하면 상황을 조금 더 개선할 수 있습니다. 또한 nudge_y parameter를 사용하여 라벨을 해당 지점보다 약간 위로 이동할 수 있습니다.
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
geom_label(aes(label = model), data = best_in_class, nudge_y = 2, alpha = 0.5)
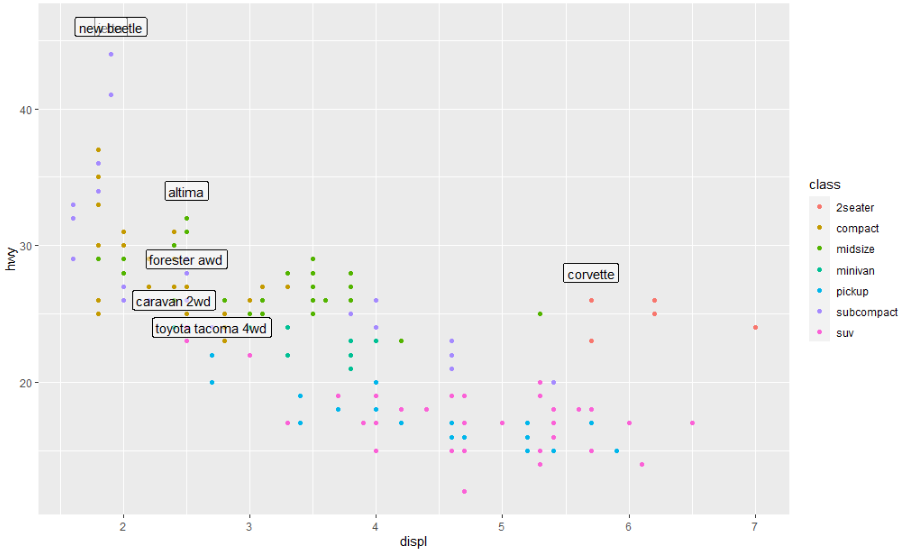
조금 도움이 되지만 왼쪽 상단 모서리를 자세히 보면 서로 위에 두 개의 라벨이 겹쳐 있는 것을 알 수 있습니다. 이것은 콤팩트 및 서브컴팩트 범주에서 최고의 자동차에 대한 고속도로 주행 거리와 배기량이 정확히 동일하기 때문에 발생합니다. 그래프에 표시된 모든 라벨에 동일한 변환을 적용하여 이러한 문제를 해결할 수 있는 방법은 없습니다. 이런 현상을 해결하기 위해 ggrepel 패키지를 사용할 수 있지만, 이번 포스팅에서는 생략하도록 하겠습니다.
플롯에 단일 라벨을 추가하기를 원할 수 있지만 그럴려면 데이터 프레임을 생성해야 합니다. 가끔 플롯의 모서리에 라벨이 필요하므로 summarise() 함수를 사용하여 x와 y의 최대값을 계산하여 이를 저장하는 새 데이터 프레임을 만드는 것이 편리합니다.
label <- mpg %>%
summarise(
displ = max(displ),
hwy = max(hwy),
label = "Increasing engine size is \nrelated to decreasing fuel economy."
)
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
geom_text(aes(label = label), data = label, vjust = "top", hjust = "right")
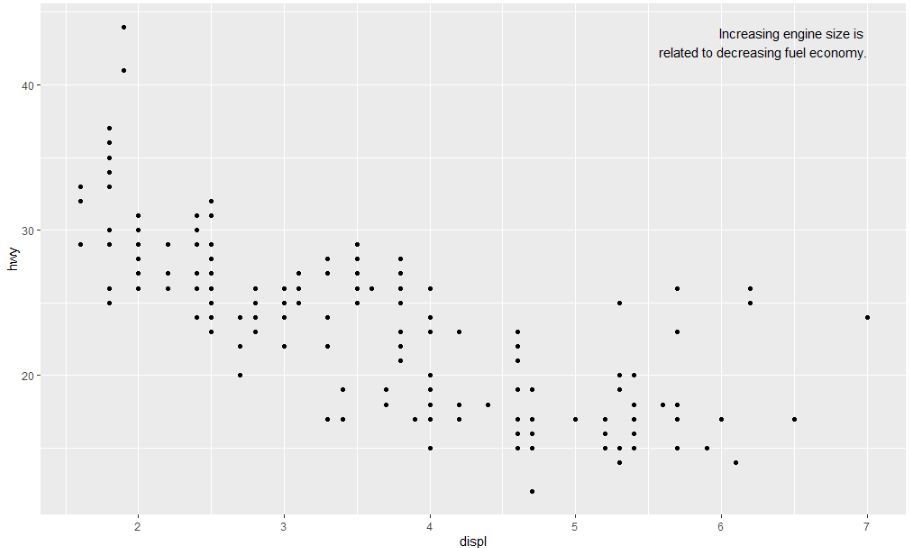
텍스트를 플롯의 경계에 정확히 배치하려면 +Inf 및 -Inf를 사용하시면 됩니다. 더 이상 mpg에서 위치를 계산할 필요가 없어 tibble()을 사용하여 데이터 프레임을 만들 수 있습니다.
label <- tibble(
displ = Inf,
hwy = Inf,
label = "Increasing engine size is \nrelated to decreasing fuel economy."
)
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
geom_text(aes(label = label), data = label, vjust = "top", hjust = "right")
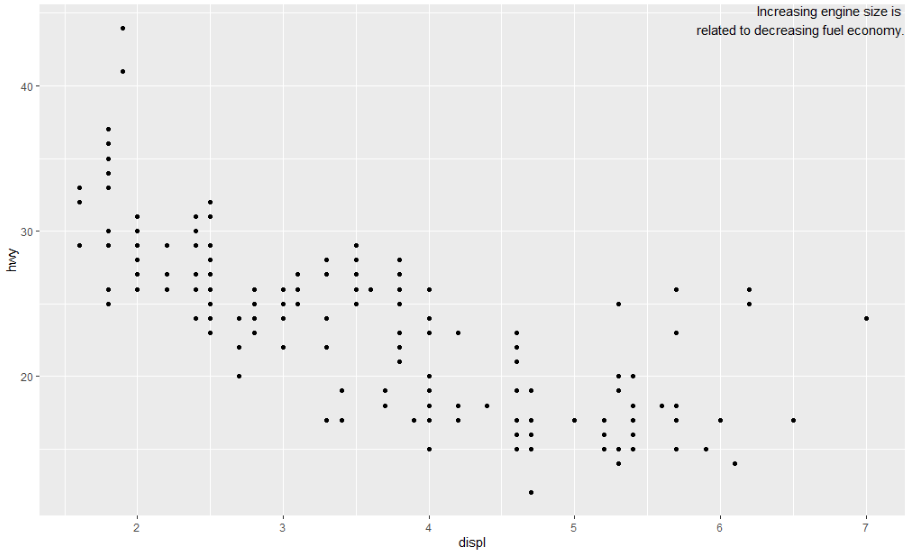
라벨의 위치를 보면 아래 그림의 경우, 우측 상단으로 더 취우침을 확인할 수 있습니다. 위의 예제에서는 정규표현식의 하나인 "\n"을 사용하여 라벨을 수동으로 줄로 나누었습니다. 또 다른 접근 방식은 stringr::str_wrap()을 사용하여 줄당 원하는 문자 수가 주어지면 줄 바꿈을 자동으로 추가하는 방법으로 줄을 나눌 수도 있습니다.
"Increasing engine size is related to decreasing fuel economy." %>%
stringr::str_wrap(width = 40) %>%
writeLines()
#> Increasing engine size is related to
#> decreasing fuel economy.
라벨의 위치를 제어하기 위해 hjust 및 vjust 사용에 유의하십시오. 아래 그림은 9가지 가능한 조합을 모두 보여줍니다.

geom_text() 함수 외에도 ggplot2에는 플롯에 주석을 추가하는 데 사용할 수 있는 다른 많은 기하 도형이 있습니다.
- geom_hline() 함수 및 geom_vline() 함수를 사용하여 참조선을 추가합니다. 참조선을 두껍게(size = 2) 및 흰색(colour = white)으로 만들고 기본 데이터 레이어 아래에 그립니다. 이 경우 데이터에서 주의를 끌지 않고도 쉽게 라벨을 볼 수 있습니다.
- 주요 포인트 주위에 직사각형을 그릴려면 geom_rect() 함수를 이용하면 됩니다. 직사각형의 경계는 xmin, xmax, ymin, ymax로 정의할 수 있습니다.
- 화살표 인수와 함께 geom_segment() 함수를 사용하여 화살표가 있는 점에 주의를 집중시킬 수도 있습니다. x 및 y를 사용하여 시작 위치를 정의하고 xend 및 yend를 사용하여 끝 위치를 정의합니다.
4. Scales
효율적인 데이터 시각화를 위해 플롯을 더 잘 표현할 수 있는 세 번째 방법은 scale을 조정하는 것입니다. scale은 데이터 값에서 감지할 수 있는 것으로의 매핑을 제어합니다. 일반적으로 ggplot2는 자동으로 스케일을 추가합니다. 예를 들어 다음을 입력할 때
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class))
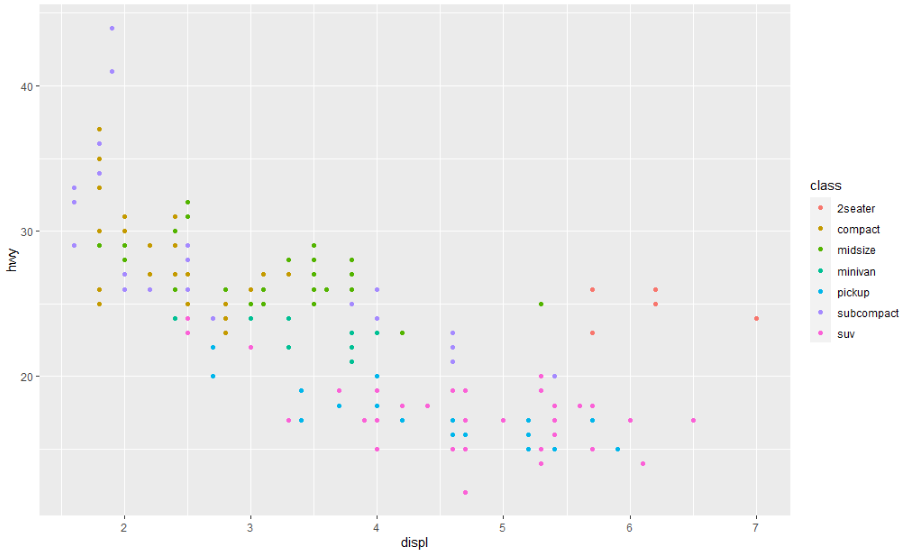
ggplot2는 자동으로 기본 스케일을 추가합니다.
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
scale_x_continuous() +
scale_y_continuous() +
scale_colour_discrete()
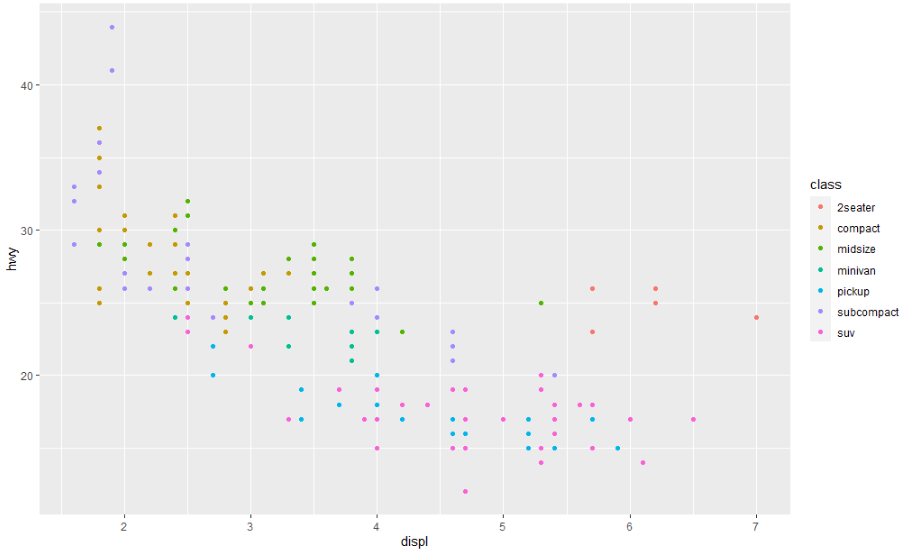
Scale의 naming 체계를 참고하세요. scale_ 다음에 미학의 이름이 오고 _ , 그 다음에 scale 이름이 나옵니다. 디폴트 scale은 정렬되는 변수의 유형(연속형, 이산형, 날짜/시간형, 날짜형)에 따라 이름이 지정됩니다. 아래에서 배우게 될 기본이 아닌 스케일이 많이 있습니다.
디폴트 scale은 다양한 입력에 대해 잘 작동하도록 되어 있습니다. 하지만, 아래 두 가지 이유로 기본값을 무시할 수 있습니다.
- 디폴트 scale의 인수를 조정할 수 있습니다. 이를 통해 축을 나눌 수 있고, 범례에 있어 주요 라벨 변경과 같은 작업을 수행할 수 있습니다.
- scale을 완전히 교체하고 완전히 다른 알고리즘을 사용하고 싶을 수도 있습니다. 데이터에 대해 더 많이 알고 있기 때문에, 잘 표현하기 위해 종종 디폴트 값보다 더 잘 할 수 있습니다.
4.1. 축 눈금 및 범례 키
축의 눈금과 범례의 키 모양에 영향을 주는 두 가지 기본 인수(breaks 와 labels)가 있습니다. breaks는 눈금 위치 또는 키와 연결된 값을 제어합니다. 라벨은 각 눈금/키와 관련된 텍스트 라벨을 제어합니다. break의 가장 일반적인 용도는 디폴트 선택을 재정의하는 것입니다.
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
scale_y_continuous(breaks = seq(15, 40, by = 5))
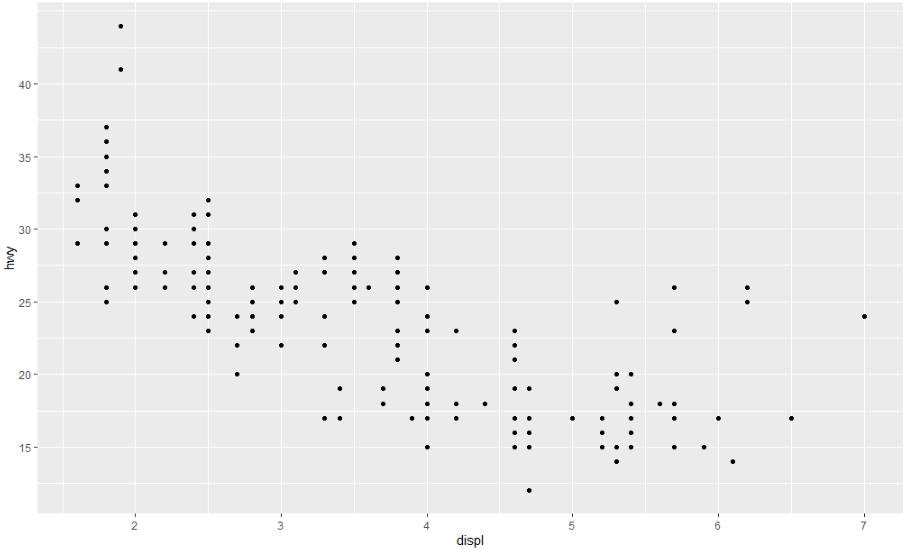
같은 방식으로 라벨을 사용할 수 있지만(문자형 벡터는 breaks와 같은 길이임) 라벨을 완전히 표시하지 않으려면 NULL로 설정할 수도 있습니다. 이것은 지도나 수치를 공개할 수 없는 플롯을 표현할 때 아주 유용합니다.
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
scale_x_continuous(labels = NULL) +
scale_y_continuous(labels = NULL)
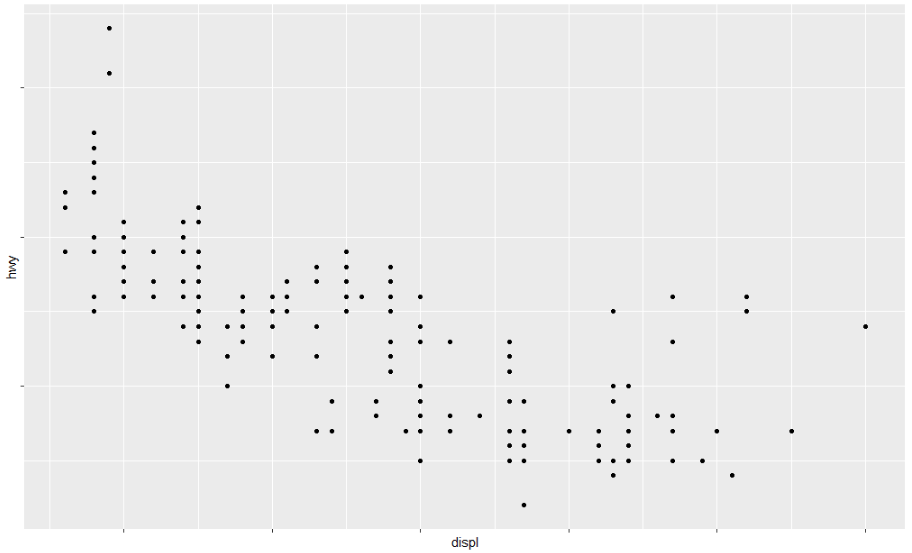
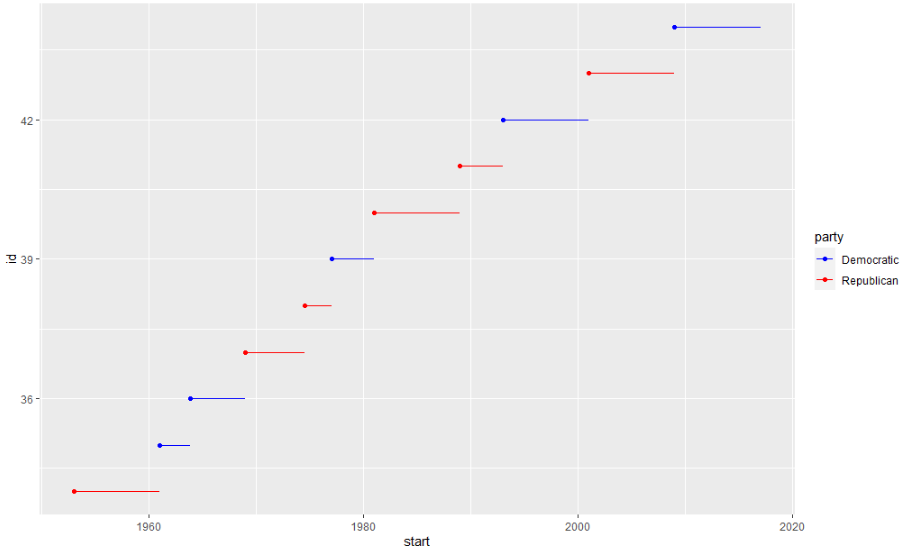
breaks와 labels를 사용하여 범례의 모양을 제어할 수도 있습니다. 축과 범례를 통틀어 안내선이라고 합니다. 축은 x 및 y 미학에 사용됩니다. 범례는 기타 다른 모든 것에 사용됩니다. breaks의 또 다른 용도는 상대적으로 적은 수의 데이터 포인트가 있고 관찰이 발생한 위치를 정확히 강조하려는 경우입니다. 예를 들어, 각 미국 대통령이 임기를 시작하고 종료한 시기를 보여주는 그림을 살펴보겠습니다.
presidential %>%
mutate(id = 33 + row_number()) %>%
ggplot(aes(start, id)) +
geom_point() +
geom_segment(aes(xend = end, yend = id)) +
scale_x_date(NULL, breaks = presidential$start, date_labels = "'%y")
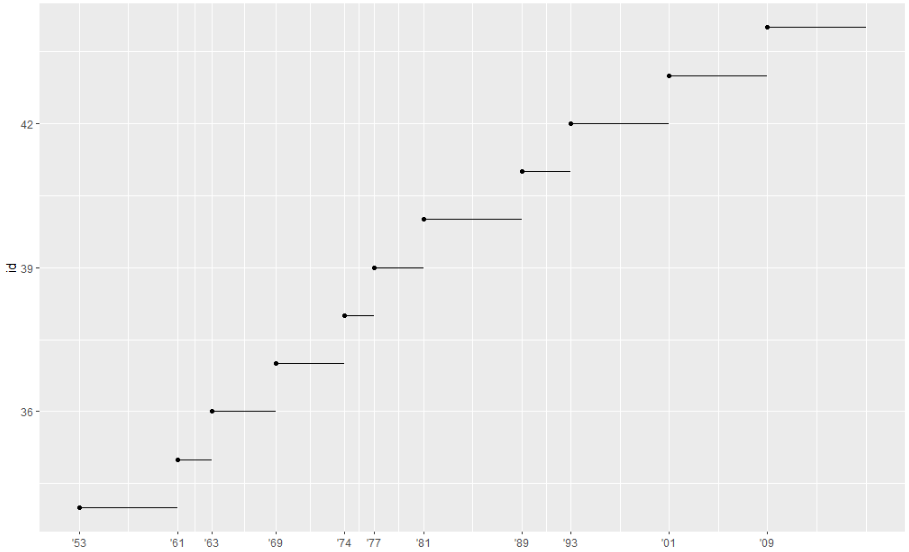
날짜 및 날짜/시간 척도에 대한 breaks 및 labels 사양은 약간 다릅니다.
- date_labels는 parse_datetime()과 같은 형식으로 형식 지정을 사용합니다.
- date_breaks(여기에는 표시되지 않음), "2일" 또는 "1개월"과 같은 문자열을 사용합니다.
4.2. 범례 레이아웃
종종 축을 조정하기 위해 breaks와 labels을 사용합니다. 하여 축을 조정합니다. 둘 다 범례에서도 작동하지만 몇 가지 다른 기술이 있습니다.
범례의 전체 위치를 제어하려면 theme() 설정을 사용해야 합니다. theme()은 플롯의 데이터가 아닌 부분을 제어합니다. theme() 에 사용되는 legend.position은 범례가 그려지는 위치를 제어합니다.
base <- ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class))
base + theme(legend.position = "left")
base + theme(legend.position = "top")
base + theme(legend.position = "bottom")
base + theme(legend.position = "right") # the default
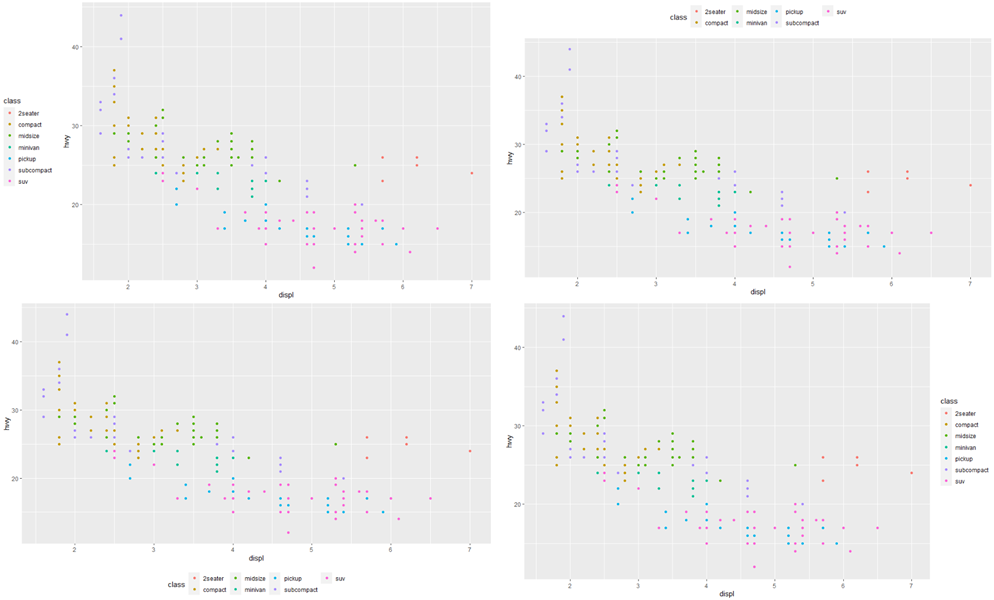
legend.position = "none"을 사용하여 범례 표시를 없앨 수도 있습니다. 개별 범례의 표시를 제어하려면 guide_legend() 또는 guide_colourbar()와 함께 guides()를 사용하셔야 합니다. 다음 예는 두 가지 중요한 설정을 보여줍니다. 범례가 nrow로 사용하는 행 수를 제어하고 미학 중 하나를 재정의하여 포인트를 더 크게 만듭니다. 이것은 플롯에 많은 점을 표시하기 위해 낮은 알파를 사용한 경우에 특히 유용합니다.
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
geom_smooth(se = FALSE) +
theme(legend.position = "bottom") +
guides(colour = guide_legend(nrow = 1, override.aes = list(size = 4)))
#> `geom_smooth()` using method = 'loess' and formula 'y ~ x'
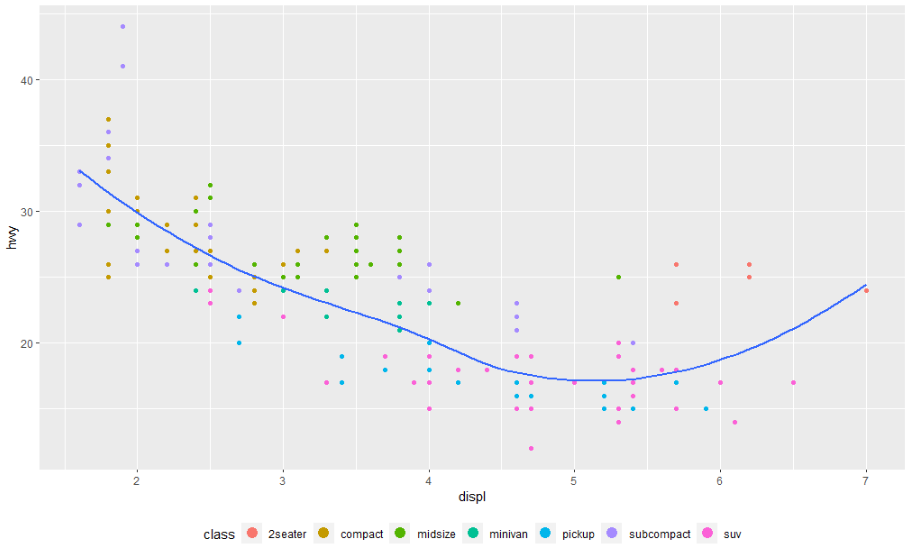
4.3. 스케일 교체
세부 사항을 약간씩 조정하는 대신 스케일을 완전히 다른 것으로 교체할 수 있습니다. 대부분 전환하고 싶은 두 가지 유형의 scale(연속적인 위치 scale및 색상 scale)이 있습니다. 다행히도 동일한 원칙이 다른 모든 미학에 적용되므로 위치와 색상을 마스터하면 다른 스케일 대체품을 빠르게 선택할 수 있습니다.
변수의 변환을 플롯하는 것은 매우 유용합니다. 예를 들어 다이아몬드 가격에서 보았듯이 캐럿과 가격 사이의 정확한 관계를 로그 변환하면 더 쉽게 볼 수 있습니다.
ggplot(diamonds, aes(carat, price)) +
geom_bin2d()
ggplot(diamonds, aes(log10(carat), log10(price))) +
geom_bin2d()
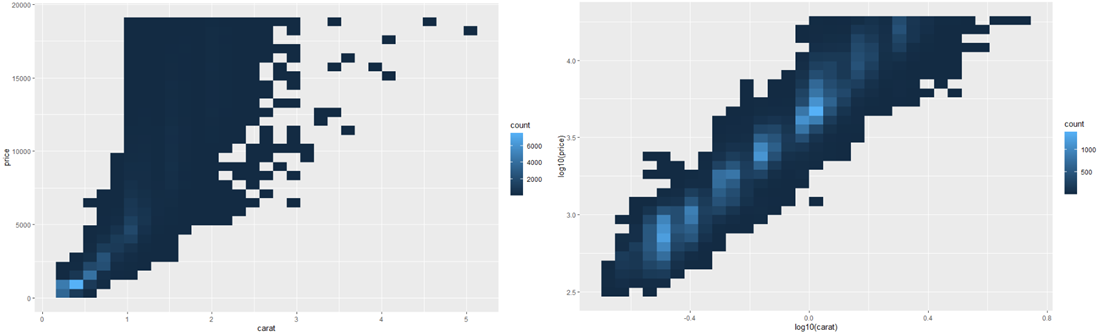
이 변환의 단점은 축에 변환된 값으로 라벨이 지정되어 플롯을 해석하기 어렵다는 것입니다. 미적 매핑에서 변환을 수행하는 대신 스케일로 변환을 수행할 수 있습니다. 이것은 축이 원래 데이터 척도에 라벨이 지정된다는 점을 제외하고는 시각적으로 동일합니다.
ggplot(diamonds, aes(carat, price)) +
geom_bin2d() +
scale_x_log10() +
scale_y_log10()
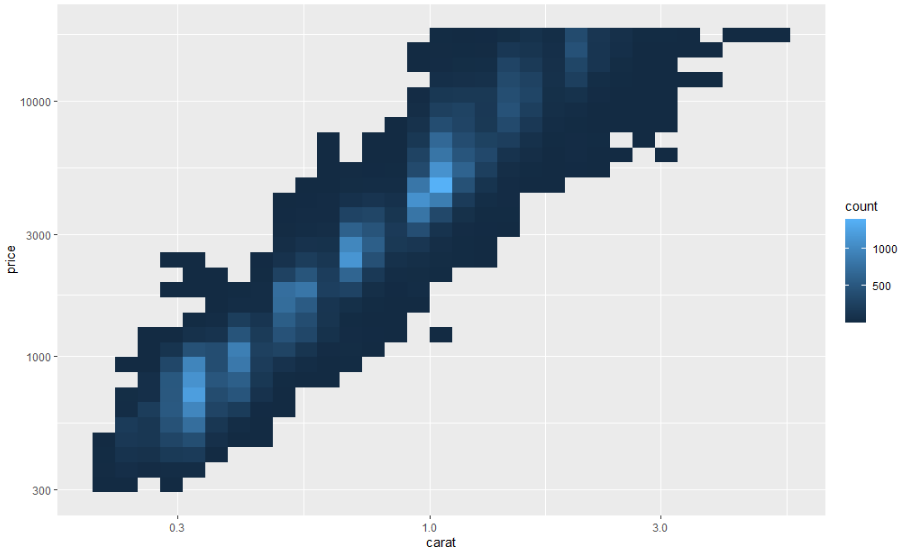
사용자가 정의하는 또 다른 scale은 색상입니다. 기본 범주형 scale은 색상환 주위에 균일한 간격을 둔 색상을 선택합니다. 유용한 대안은 일반적인 유형의 색맹이 있는 사람들에게 더 잘 작동하도록 손으로 조정된 ColorBrewer 스케일입니다. 아래의 두 플롯은 비슷해 보이지만 오른쪽의 점들이 적록 색맹인 사람들도 구분할 수 있을 정도로 빨강과 녹색의 음영 차이가 충분합니다.
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = drv))
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = drv)) +
scale_colour_brewer(palette = "Set1")
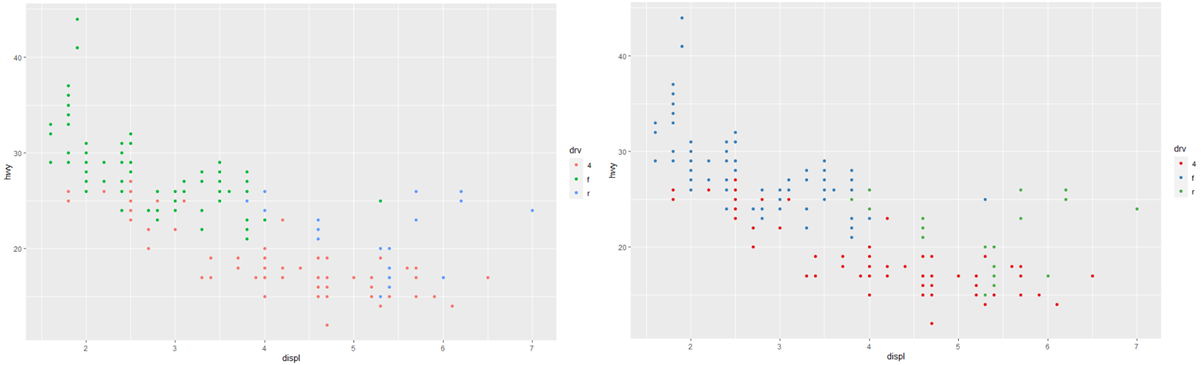
더 간단한 기술도 있습니다. 몇 가지 색상만 있는 경우 중복된 모양 매핑을 추가할 수 있습니다. 이것은 또한 플롯을 흑백으로 해석할 수 있는지 확인하는 데 도움이 됩니다.
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = drv, shape = drv)) +
scale_colour_brewer(palette = "Set1")
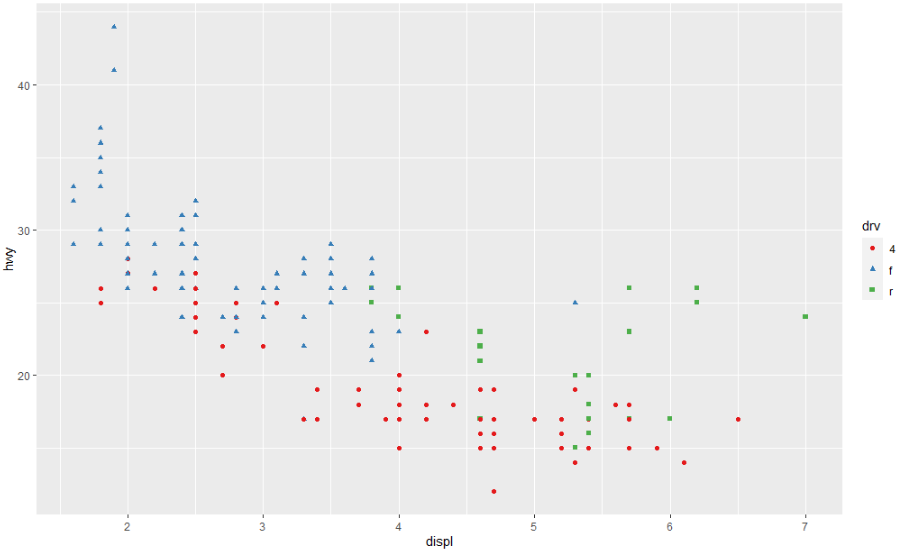
ColorBrewer 스케일은 http://colorbrewer2.org/에 온라인으로 문서화되어 있으며 Erich Neuwirth가 RColorBrewer 패키지를 통해 R에서 사용할 수 있습니다. 아래 그림은 모든 팔레트의 전체 목록을 보여줍니다. 순차(상단) 및 발산(하단) 팔레트는 범주형 값이 정렬되거나 "중간"이 있는 경우 특히 유용합니다. 이는 연속 변수를 범주형 변수로 만들기 위해 cut()을 사용한 경우에 자주 발생합니다.

값과 색상 간에 사전 정의된 매핑이 있는 경우 scale_colour_manual()을 사용합니다. 예를 들어, 대통령 정당을 색상에 매핑하는 경우 공화당에는 빨간색, 민주당원에는 파란색의 표준 매핑을 사용하려고 합니다.
presidential %>%
mutate(id = 33 + row_number()) %>%
ggplot(aes(start, id, colour = party)) +
geom_point() +
geom_segment(aes(xend = end, yend = id)) +
scale_colour_manual(values = c(Republican = "red", Democratic = "blue"))
연속 색상의 경우 scale_colour_gradient() 함수 또는 scale_fill_gradient() 함수를 사용할 수 있습니다. 발산 스케일이 있는 경우 scale_colour_gradient2()를 사용할 수 있습니다. 예를 들어 양수 값과 음수 값에 서로 다른 색상을 지정할 수 있습니다. 이는 평균 위 또는 아래에 있는 점을 구별하려는 경우에도 유용합니다.
또 다른 옵션은 viridis 패키지에서 제공하는 scale_colour_viridis() 함수입니다. 범주형 ColorBrewer scale의 연속 아날로그입니다. 디자이너인 Nathaniel Smith와 Stéfan van der Walt는 지각 특성이 좋은 연속적인 색 구성표를 신중하게 조정했습니다. 아래 그림은 viridis vignette의 예입니다.
df <- tibble(
x = rnorm(10000),
y = rnorm(10000)
)
ggplot(df, aes(x, y)) +
geom_hex() +
coord_fixed()
ggplot(df, aes(x, y)) +
geom_hex() +
viridis::scale_fill_viridis() +
coord_fixed()
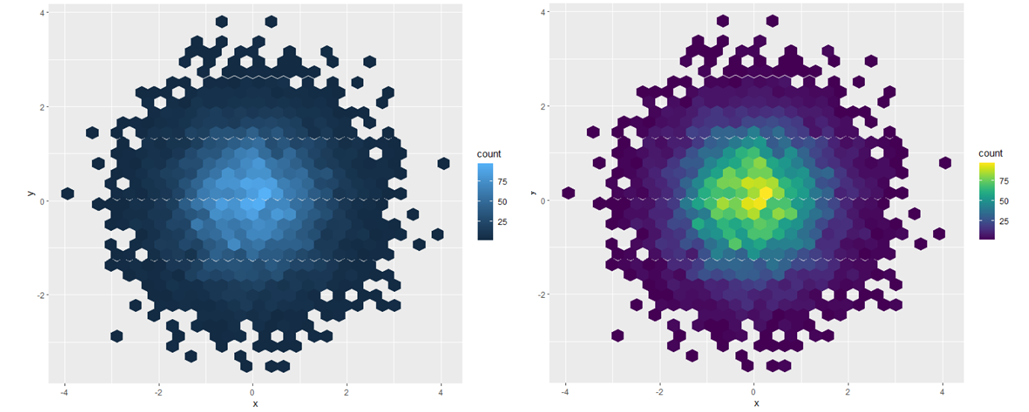
모든 색상 scale은 색상 및 채우기 미학에 대해 각각 scale_colour_x() 및 scale_fill_x()의 두 가지 종류로 제공됩니다(색상 스케일은 영국 및 미국 철자 모두에서 사용 가능).
5. 확대/축소
플롯 한계를 제어하는 세 가지 방법이 있습니다.
- 표시되는 데이터 조정
- 각 scale의 한계 설정
- coord_cartesian()에서 xlim 및 ylim 설정
플롯의 영역을 확대하려면 일반적으로 coord_cartesian()을 사용하는 것이 가장 좋습니다. 다음 두 플롯을 비교해 봅시다.
ggplot(mpg, mapping = aes(displ, hwy)) +
geom_point(aes(color = class)) +
geom_smooth() +
coord_cartesian(xlim = c(5, 7), ylim = c(10, 30))
mpg %>%
filter(displ >= 5, displ <= 7, hwy >= 10, hwy <= 30) %>%
ggplot(aes(displ, hwy)) +
geom_point(aes(color = class)) +
geom_smooth()
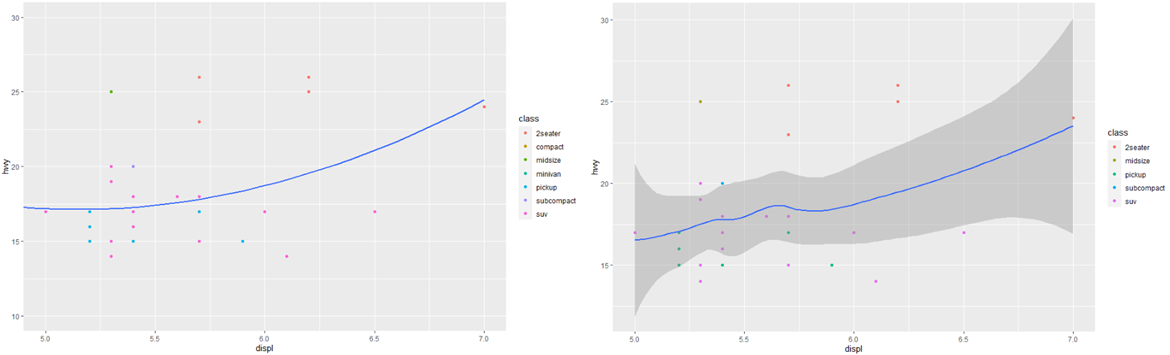
개별 scale에 대한 제한을 설정할 수도 있습니다. 한계를 줄이는 것은 기본적으로 데이터의 부분 집합과 동일합니다. 예를 들어 서로 다른 플롯에서 scale을 일치시키기 위해 한계를 확장하려는 경우 일반적으로 더 유용합니다. 예를 들어 두 종류의 자동차를 추출하여 따로 플로팅하면 3가지 스케일(x축, y축, 색상 미학)이 모두 범위가 다르기 때문에 플롯을 비교하기 어렵습니다.
suv <- mpg %>% filter(class == "suv")
compact <- mpg %>% filter(class == "compact")
ggplot(suv, aes(displ, hwy, colour = drv)) +
geom_point()
ggplot(compact, aes(displ, hwy, colour = drv)) +
geom_point()
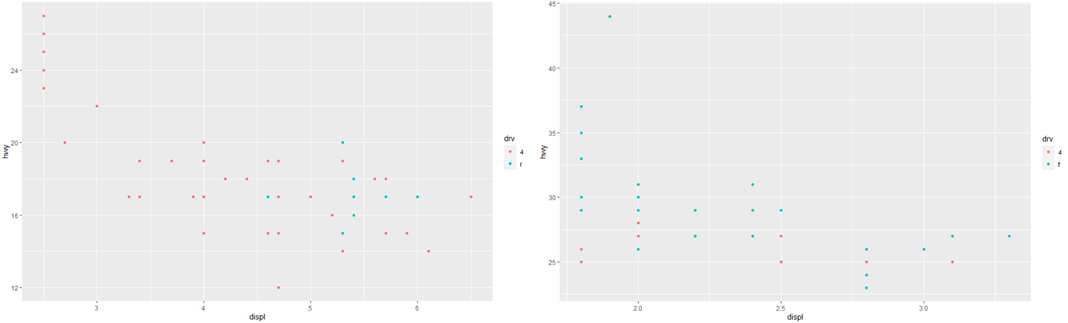
이 문제를 해결하기 위한 한 가지 방법은 전체 데이터가 가질 수 있는 범위로 scale을 맞추고, 여러 플롯에서 이 scale을 공유하는 것입니다.
x_scale <- scale_x_continuous(limits = range(mpg$displ))
y_scale <- scale_y_continuous(limits = range(mpg$hwy))
col_scale <- scale_colour_discrete(limits = unique(mpg$drv))
ggplot(suv, aes(displ, hwy, colour = drv)) +
geom_point() +
x_scale +
y_scale +
col_scale
ggplot(compact, aes(displ, hwy, colour = drv)) +
geom_point() +
x_scale +
y_scale +
col_scale
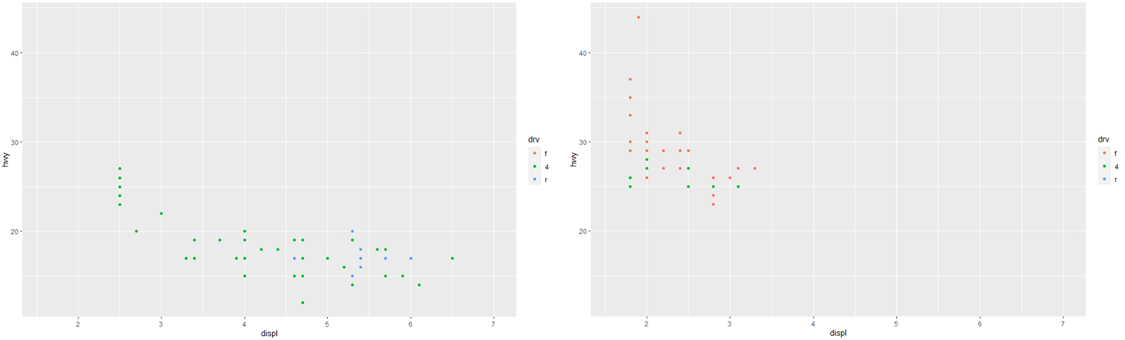
이 특별한 경우에는 단순히 facet을 사용할 수도 있지만, facet은 보고서의 여러 페이지에 플롯을 분산하려는 경우에 더 일반적으로 유용합니다.
6. 테마
마지막으로 플롯의 데이터가 아닌 요소를 테마로 사용자 정의할 수 있습니다.
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = class)) +
geom_smooth(se = FALSE) +
theme_bw()
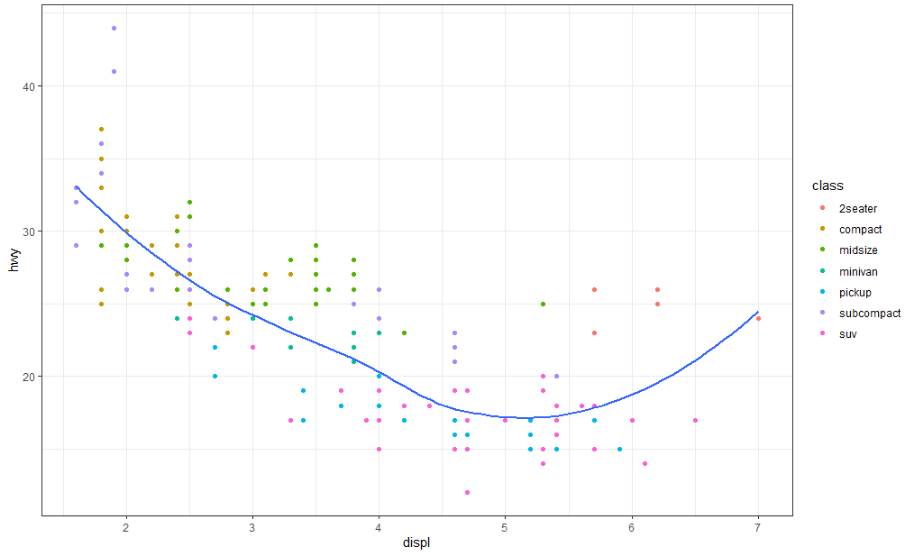
ggplot2에는 아래와 같이 기본적으로 8개의 테마가 포함되어 있습니다.
많은 사람들이 왜 기본 테마에 회색 배경이 있는 이유를 궁금해합니다. 그리드 선을 계속 표시하면서 데이터를 앞으로 보내기 때문에 이는 신중한 선택이었습니다. 흰색 격자선은 볼 수 있지만(위치 판단에 크게 도움이 되기 때문에 중요함) 시각적 영향이 거의 없고 쉽게 조정할 수 있습니다. 회색 배경은 플롯에 텍스트와 유사한 인쇄상의 색상을 제공하여 그래픽이 밝은 흰색 배경으로 튀어나오지 않고 문서의 흐름에 맞도록 합니다. 마지막으로 회색 배경은 플롯이 단일 시각적 개체로 인식되도록 하는 연속적인 색상 필드를 만듭니다.
y축에 사용되는 글꼴의 크기와 색상과 같은 각 테마의 개별 구성 요소를 제어하는 것도 가능합니다. 특정 기업 또는 저널 스타일과 일치시키려는 경우 자신만의 테마를 만들 수도 있습니다.
7. 플롯 저장
R에서 플롯을 가져와서 최종 작성에 넣는 두 가지 주요 방법(ggsave() 와 knitr)이 있습니다. ggsave()는 가장 최근의 플롯을 디스크에 저장합니다.
ggplot(mpg, aes(displ, hwy)) + geom_point()
ggsave("my-plot.pdf")
#> Saving 7 x 4.33 in image
너비와 높이를 지정하지 않으면 현재 플로팅 장치의 치수에서 가져옵니다. 재현 가능한 코드를 위해 너비와 높이를 지정하고 싶을 것입니다. 그러나 일반적으로 R Markdown을 사용하여 최종 보고서를 조합해야 한다고 생각하기 때문에 그래픽에 대해 알아야 할 중요한 코드 청크 옵션에 초점을 맞추고 싶습니다. 문서에서 ggsave()에 대해 자세히 알아볼 수 있습니다.
7.1. 그림 크기
R Markdown에서 그래픽의 가장 큰 과제는 그림을 올바른 크기와 모양으로 만드는 것입니다. Figure 크기를 제어하는 다섯 가지 주요 옵션(fig.width, fig.height, fig.asp, out.width 및 out.height)이 있습니다. 이미지 크기 조정은 두 가지 크기(R로 생성된 그림의 크기와 출력 문서에 삽입되는 크기)와 크기를 지정하는 여러 방법(즉, 높이, 너비 및 종횡비: 3개 중 2개 선택)이 있기 때문에 어렵습니다.
다섯 가지 옵션 중 세 가지만 사용합니다.
- 플롯의 일관된 너비: 이를 적용하기 위해 기본값에서 fig.width = 6(6") 및 fig.asp = 0.618(황금 비율) 설정. 그런 다음 개별 청크에서 fig.asp만 조정합니다.
- out.width를 사용하여 출력 크기 제어 및 선 너비의 백분율 설정: 기본적으로 out.width = "70%" 및 fig.align = "center" 사용. 너무 많은 공간을 차지하지 않고 플롯에 여백을 제공
- 여러 플롯을 단일 행에 배치하려면 out.width를 2개의 플롯에 대해 50%, 3개의 플롯에 대해 33%, 또는 4개의 플롯에 대해 25%로 설정하고 fig.align = "default"로 설정합니다. 설명하려는 내용(예: 데이터 표시 또는 플롯 변형 표시)에 따라 아래에 설명된 대로 fig.width도 조정할 것입니다.
플롯의 텍스트를 읽기 어렵다면 fig.width를 조정해야 합니다. fig.width가 최종 문서에서 그림이 렌더링된 크기보다 크면 텍스트가 너무 작아집니다. fig.width가 작으면 텍스트가 너무 커집니다. 문서의 fig.width와 최종 너비 사이의 올바른 비율을 알아내기 위해 약간의 실험을 해야 하는 경우가 종종 있습니다. 원리를 설명하기 위해 다음 세 가지 그림의 너비는 fig.width 값이 각각 4, 6, 8입니다.
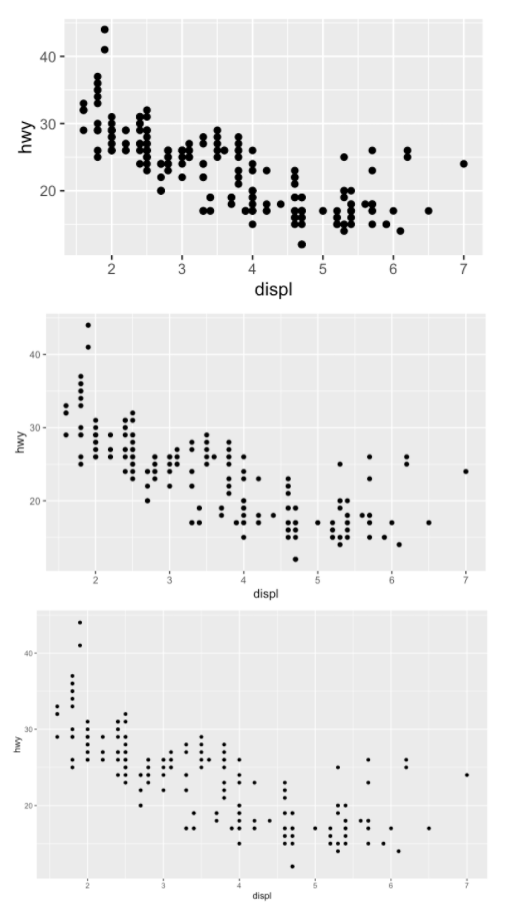
모든 그림에서 글꼴 크기를 일관되게 유지하려면 out.width를 설정할 때마다 기본 out.width와 동일한 비율을 유지하도록 fig.width도 조정해야 합니다. 예를 들어 기본 fig.width가 6이고 out.width가 0.7인 경우 out.width = "50%"를 설정할 때 fig.width를 4.3(6 * 0.5 / 0.7)으로 설정해야 합니다.
7.2. 다른 중요한 옵션들
코드와 텍스트를 혼합할 때 코드 뒤에 플롯이 표시되도록 fig.show = "hold"로 설정하는 것이 좋습니다. 이것은 설명과 함께 큰 코드 블록을 강제로 분해해야 하는 즐거운 부작용이 있습니다.
플롯에 캡션을 추가하려면 fig.cap을 사용하시면 됩니다. R Markdown에서는 그림이 인라인에서 "플로팅"으로 변경됩니다.
PDF 출력을 생성하는 경우 기본 그래픽 유형은 PDF입니다. 이것은 PDF가 고품질 벡터 그래픽이기 때문에 좋은 기본값입니다. 그러나 수천 개의 점을 표시하는 경우 매우 크고 느린 플롯을 생성할 수 있습니다. 이 경우 dev = "png"를 설정하여 PNG를 강제로 사용합니다. 품질은 약간 떨어지지만 훨씬 더 컴팩트합니다.
다른 청크에 일상적으로 레이블을 지정하지 않더라도 숫자를 생성하는 코드 청크의 이름을 지정하는 것이 좋습니다. 청크 라벨은 디스크에 있는 그래픽의 파일 이름을 생성하는 데 사용되므로 청크에 이름을 지정하면 플롯을 선택하고 다른 상황에서 재사용하기가 훨씬 쉽습니다. (즉, 이메일이나 트윗에 하나의 플롯을 빠르게 삭제하려는 경우)
8. 더 배우기
더 자세히 배울 수 있는 가장 좋은 곳은 ggplot2 책(ggplot2: 데이터 분석을 위한 우아한 그래픽)입니다. 기본 이론에 대해 훨씬 더 깊이 들어가고 실제 문제를 해결하기 위해 개별 조각을 결합하는 방법에 대한 더 많은 예가 있습니다. 또 다른 훌륭한 리소스는 ggplot2 확장 갤러리 https://exts.ggplot2.tidyverse.org/gallery/입니다. 이 사이트는 ggplot2를 새로운 형태와 스케일로 확장하는 많은 패키지를 나열합니다. ggplot2로 어려워 보이는 일을 시작하려는 경우 시작하기에 좋은 곳입니다.
'R 프로그래밍 > R advance' 카테고리의 다른 글
| 오픈 API를 활용한 공공데이터 불러오기(데이터 포맷: xml) (25) | 2022.01.07 |
|---|---|
| 와이드 포맷과 롱 포맷 간 데이터 변환 (0) | 2021.12.28 |
| [R데이터다루기]데이터 변환 (0) | 2021.07.18 |
| [R그래픽스]데이터 시각화 (0) | 2021.07.17 |
| [R데이터구조]Tibble (0) | 2021.07.15 |




댓글