본 내용을 보기 전에 Python 사전 준비 및 Python 완전 기초를 먼저 이해하셔야 합니다.
본 포스팅은 pandas 공식 홈페이지를 기반으로 작성하였습니다.
본 포스팅의 실습을 위해 사용할 2개의 데이터 세트는 아래와 같습니다.
(NO2에 대한 대기질 데이터로, openaq에서 제공하고 py-openaq 패키지를 사용하여 다운로드 가능. air_quality_no2_long.csv 데이터 세트는 각각 파리, 앤트워프 및 런던에 있는 측정 스테이션 FR04014, BETR801 및 런던 웨스트민스터에 대한 NO2 값 제공)
import pandas as pd
air_quality_no2 = pd.read_csv("D:/python_exer/air_quality_no2_long.csv", parse_dates = True)
air_quality_no2 = air_quality_no2[["date.utc", "location", "parameter", "value"]]
air_quality_no2.head()
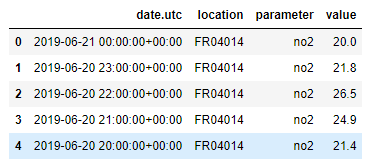
(2.5마이크로미터 미만의 미립자 물질에 대한 대기질 데이터로, openaq에서 제공하고 py-openaq 패키지를 사용하여 다운로드 가능. air_quality_pm25_long.csv 데이터 세트는 각각 파리, 앤트워프 및 런던에 있는 측정 스테이션 FR04014, BETR801 및 런던 웨스트민스터에 대한 PM25 값 제공)
air_quality_pm25 = pd.read_csv("D:/python_exer/air_quality_pm25_long.csv", parse_dates=True)
air_quality_pm25 = air_quality_pm25[["date.utc", "location", "parameter", "value"]]
air_quality_pm25.head()

1. 테이블 결합 방법
1.1. 객체 연결
1.1.1. 비슷한 구조의 두 테이블인 NO2와 PM25의 측정값을 하나의 테이블에 결합하기
air_quality = pd.concat([air_quality_no2, air_quality_pm25], axis = 0)
air_quality
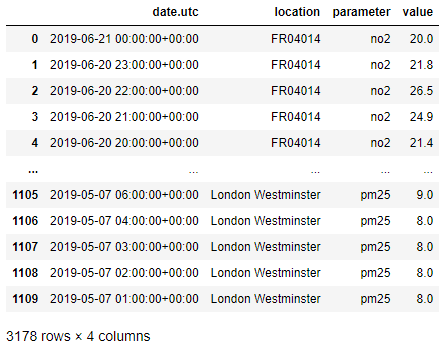
concat() 함수는 축 중 하나를 따라 여러 테이블의 연결 작업을 수행합니다(행 또는 열). 기본적으로 연결은 축 0을 따르므로 결과 테이블은 입력 테이블의 행을 결합합니다. 원본과 연결된 테이블의 형태를 확인하여 어떻게 동작 하는 지 확인해 보겠습니다.
print('Shape of the ''air_quality_no2'' table: ', air_quality_no2)
print('Shape of the ''air_quality_pm25'' table: ', air_quality_pm25)
print('Shape of the resulting ''air_quality'' table: ', air_quality)
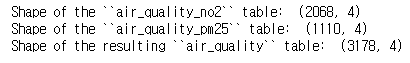
따라서 결과 테이블에는 3178 = 1110 + 2068 행이 있습니다. (Note: axis 인수는 축을 따라 적용할 수 있는 여러 pandas 메서드에서 반환됩니다. DataFrame에는 두 개의 해당 축이 있습니다. 첫 번째는 행(축 0)을 가로질러 수직으로 아래쪽으로 실행되고 두 번째는 열(축 1)을 가로질러 가로로 실행됩니다. 연결 또는 요약 통계와 같은 대부분의 작업은 기본적으로 행(축 0)에 걸쳐 있지만 열에도 적용될 수 있습니다.)
날짜/시간 정보에 대한 테이블 정렬은 원본 테이블을 정의하는 매개변수 열과 함께 두 테이블의 조합을 보여줍니다(테이블 air_quality_no2의 no2 또는 테이블 air_quality_pm25의 pm25).
air_quality = air_quality.sort_values(by = "date.utc")
air_quality.head()
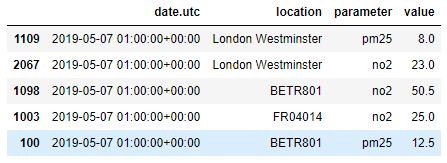
이 특정 예에서 데이터가 제공하는 매개변수 열은 원본 테이블 각각을 식별할 수 있도록 합니다. 항상 그런 것은 아닙니다. concat 함수는 추가(계층적) 행 인덱스를 추가하여 keys 인수로 편리한 솔루션을 제공합니다. 아래의 예시를 보겠습니다.
air_quality = pd.concat([air_quality_pm25,air_quality_no2], keys = ["pm25","no2"])
air_quality.head()
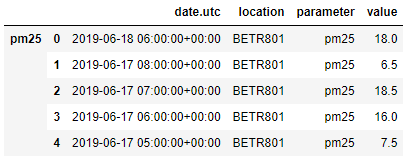
(Note: 동시에 여러 행/열 인덱스의 존재는 본 포스팅에서는 언급하지 않았습니다. 계층적 인덱싱 또는 MultiIndex는 고차원 데이터를 분석하는 강력한 고급 pandas 기능입니다. MultiIndexing은 이 pandas 소개의 범위를 벗어납니다. 잠시 동안 reset_index 함수를 사용하여 인덱스의 모든 수준을 열로 변환할 수 있습니다(ex. air_quality.reset_index(level=0)).
2. 공통 식별자를 사용하여 테이블 조인

2.1. 역의 좌표(위도, 경도)를 측정 테이블의 해당 행에 추가하기
공기질 측정 역의 좌표는 py-openaq 패키지를 사용하여 다운로드하여 air_quality_stations.csv 형식으로 저장합니다. 아래 데이터를 다운로드 받으시면 됩니다.
stations_coord = pd.read_csv("D:/python_exer/air_quality_stations.csv")
stations_coord.head()

(Note: 이 예에서 사용된 스테이션(FR04014, BETR801 및 London Westminster)은 메타데이터 테이블에 등록된 세 개의 항목일 뿐입니다. air_quality 테이블의 해당 행에 있는 이 세 개의 좌표만 측정 테이블에 추가하려고 합니다.)
air_quality.head()
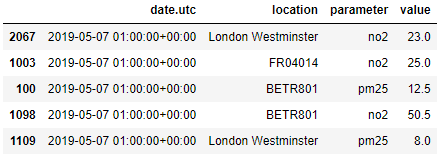
air_quality = pd.merge(air_quality, stations_coord, how="left", on="location")
air_quality.head()
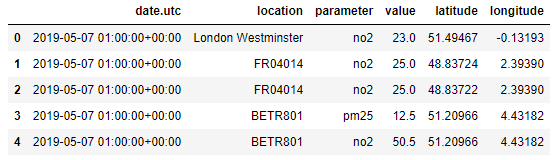
merge() 함수를 사용하여 air_quality 테이블의 각 행에 대해 stations_coord 테이블에서 해당 좌표가 추가됩니다. 두 테이블에는 정보를 결합하는 키로 사용되는 공통 열 location이 있습니다. left join을 선택하면 air_quality(왼쪽) 테이블에서 사용 가능한 location(예: FR04014, BETR801 및 London Westminster)만 결과 테이블에 표시됩니다. merge 함수는 데이터베이스 스타일 작업과 유사한 여러 조인 옵션을 지원합니다.
2.2. 매개변수 전체 설명 및 이름 추가하기
이의 예제를 위해 아래 데이터를 다운로드합니다.
air_quality_parameters = pd.read_csv("D:/python_exer/air_quality_parameters.csv") air_quality_parameters.head()

air_quality = pd.merge(air_quality, air_quality_parameters, how='left', left_on='parameter', right_on='id')
air_quality.head()

앞의 예와 비교하여 공통된 열 이름이 없습니다. 그러나 air_quality 테이블의 매개변수 열과 air_quality_parameters_name의 id 열은 모두 공통 형식으로 측정된 변수를 제공합니다. left_on 및 right_on 인수는 두 테이블의 join key 인수입니다.
3. REMEMBER !
- concat 함수를 사용하여 여러 테이블을 열 및 행 단위로 연결할 수 있습니다.
- 데이터베이스와 같은 테이블 병합/조인의 경우 병합 기능을 사용합니다.
'Python > Pandas' 카테고리의 다른 글
| Pandas 텍스트 데이터 다루기 (0) | 2021.08.21 |
|---|---|
| Pandas 시계열 데이터 다루기 (0) | 2021.08.20 |
| Pandas 테이블 구조 변경 방법 (0) | 2021.08.18 |
| Pandas 활용 요약통계량 생성하기 (0) | 2021.08.17 |
| Pandas 신규 Column 생성 (0) | 2021.08.16 |




댓글