본 내용을 보기 전에 Python 사전 준비 및 Python 완전 기초를 먼저 이해하셔야 합니다.
본 포스팅은 pandas 공식 홈페이지를 기반으로 작성하였습니다.
이번 포스팅에서 사용할 실습 데이터는 Air quality data입니다. 아래 데이터를 활용하시면 됩니다.
(air_quality_no2_long.csv: NO2 및 2.5 마이크로미터 미만의 미립자 물질에 대한 대기 품질 데이터로, openaq에서 제공하고 py-openaq 패키지를 사용하여 다운로드합니다. 파리, 앤트워프 및 런던에 있는 측정 스테이션 FR04014, BETR801 및 런던 웨스트민스터에 대한 NO2 값을 제공합니다.)
import pandas as pd
import matplotlib.pyplot as plt
air_quality = pd.read_csv("D:/python_exer/air_quality_no2_long.csv")
air_quality = air_quality.rename(columns = {"date.utc" : "datetime"})
air_quality.head()

1. 시계열 데이터 다루기
1.1. pandas datetime 속성 사용
1.1.1. 일반 텍스트 대신 datetime 개체로 datetime 열의 날짜 다루기
air_quality["datetime"] = pd.to_datetime(air_quality["datetime"])
air_quality["datetime"]

처음에 datetime의 값은 문자열이며, datetime 형식의 데이터 작업을 제공하지 않습니다(예: 연도, 요일 추출 등). to_datetime 함수를 적용하여 pandas는 문자열을 해석하고 이를 datetime(예: datetime64[ns, UTC]) 객체로 변환합니다. pandas에서는 표준 라이브러리의 datetime.datetime과 유사한 이러한 datetime 객체를 pandas.Timestamp라고 부릅니다. (Note: 많은 데이터 세트가 열 중 하나에 날짜/시간 정보를 포함하기 때문에 pandas.read_csv() 및 pandas.read_json()과 같은 pandas 입력 함수는 parse_dates 매개변수를 사용하여 데이터를 읽을 때 날짜로 변환할 열 목록(tiemstamp)이 있습니다.
pd.read_csv("../data/air_quality_no2_long.csv", parse_dates=["datetime"])
이 pandas.Timestamp 객체가 유용한 이유는 아래의 몇 가지 사례를 통해 설명하겠습니다.
▶ 우리가 실습하고 있는 시계열 데이터 세트의 시작 날짜와 종료 날짜 구하기
air_quality["datetime"].min(), air_quality["datetime"].max()

날짜 시간에 pandas.Timestamp를 사용하면 날짜 정보로 계산하고 비교할 수 있습니다. 따라서 이것을 사용하여 시계열의 길이를 얻을 수 있습니다.
air_quality["datetime"].max() - air_quality["datetime"].min()

결과는 표준 Python 라이브러리의 datetime.timedelta와 유사하고 기간을 정의하는 pandas.Timedelta 객체입니다.
1.1.2. 측정 월만 포함한 새 열 추가하기
air_quality["month"] = air_quality["datetime"].dt.month
air_quality.head()

날짜에 Timestamp 개체를 사용하면 pandas에서는 많은 시간 관련 속성을 제공합니다. 예를 들어, 월뿐만 아니라 연도, 주중, 분기 등 이러한 모든 속성은 dt 접근자로 액세스 할 수 있습니다.
1.1.3. 각 측정 위치에 대한 요일별 평균 NO2 농도 구하기
air_quality.groupby([air_quality["datetime"].dt.weekday, "location"])["value"].mean()
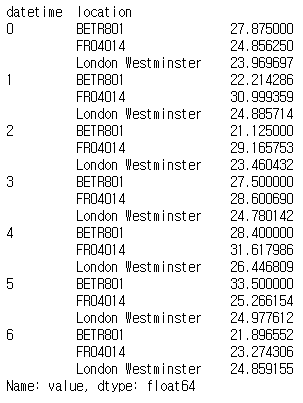
2021.08.17 - [Python/Pandas 기초익히기] - Pandas 활용 요약통계량 생성하기에서 groupby가 제공하는 split-apply-combine 패턴을 배웠습니다. 이번 포스팅에서는 각 요일 및 각 측정 위치에 대해 주어진 통계(예: 평균 NO2)를 계산하려고 합니다. 요일별 그룹화를 위해 dt 접근자에서도 액세스 할 수 있는 pandas Timestamp의 datetime 속성 weekday(월요일=0 및 일요일=6)를 사용합니다. 위치와 요일 모두에 대한 그룹화를 수행하여 이러한 각 조합에 대한 평균 계산을 분할할 수 있습니다(주의: 이 예에서 매우 짧은 시계열로 작업하기 때문에 분석은 장기적인 대표 결과를 제공하지 않습니다!).
1.1.4. 모든 관측소에 대한 시간대별 평균 NO2 수치 변화 패턴 나타내기
fig, axs = plt.subplots(figsize=(12, 4))
air_quality.groupby(air_quality["datetime"].dt.hour)["value"].mean().plot(kind='bar', rot=0, ax=axs)
plt.xlabel("Hour of the day")
plt.ylabel("$NO_2 (µg/m^3)$")

이전의 경우와 유사하게 하루의 각 시간에 대해 평균 NO2를 계산하고 분할-적용-결합 접근 방식을 다시 사용할 수 있습니다. 이 경우 dt 접근자도 액세스 할 수 있는 pandas Timestamp의 datetime 속성 hour를 사용합니다.
1.2. 인덱스로서의 datetime
2021.08.18 - [Python/Pandas 기초익히기] - Pandas 테이블 구조 변경 방법에서 각 측정 위치를 별도의 열로 사용하여 데이터 테이블을 재구성하기 위해 pibot() 함수를 사용했습니다.
no_2 = air_quality.pivot(index="datetime", columns="location", values="value")
no_2.head()

(Note: 데이터를 피벗함으로써 날짜/시간 정보가 테이블의 인덱스가 되었습니다. 일반적으로 열을 인덱스로 설정하는 것은 set_index 함수로 가능합니다.)
날짜/시간 인덱스(예: DatetimeIndex)로 작업하면 강력한 기능을 제공합니다. 예를 들어 시계열 속성을 가져오기 위해 dt 접근자가 필요하지 않지만 이러한 속성을 인덱스에서 직접 사용할 수 있습니다.
no_2.index.year, no_2.index.weekday

몇 가지 다른 장점은 기간의 편리한 부분 집합 또는 플롯에 적응된 시간 척도입니다. 이를 데이터에 적용해 보겠습니다.
1.2.1. 5월 20일부터 5월 21일 말까지 관측소에서 측정된 NO2 값 그리기
no_2["2019-05-20":"2019-05-21"].plot()

datetime으로 구문 분석하는 문자열을 제공하여 DatetimeIndex에서 데이터의 특정 하위 집합을 선택할 수 있습니다.
1.3. 시계열을 다른 빈도로 리샘플링하기
1.3.1. 현재 시간별 시계열 값을 각 스테이션의 월별 최댓값 계산하기
monthly_max = no_2.resample("M").max()
monthly_max

날짜/시간 인덱스가 있는 시계열 데이터에 대한 매우 강력한 방법은 시계열을 다른 빈도로 resample()하는 기능입니다(예: 두 번째 데이터를 5분 데이터로 변환).
resample() 함수는 groupby 작업과 유사합니다.
- 목표 빈도를 정의하는 문자열(예: M, 5H,…)을 사용하여 시간 기반 그룹화를 제공합니다.
- 평균, 최댓값과 같은 집계 함수가 필요합니다.
정의된 경우 시계열의 빈도는 freq 속성에 의해 제공됩니다.
monthly_max.index.freq

1.3.2. 각 스테이션의 일일 평균 NO2 값 그리기
no_2.resample("D").mean().plot(style="-o", figsize=(10, 5))

2. Remeber !
- 유효한 날짜 문자열은 to_datetime 함수를 사용하거나 읽기 함수의 일부로 datetime 객체로 변환할 수 있습니다.
- pandas의 날짜/시간 개체는 dt 접근자를 사용하여 계산, 논리 연산 및 편리한 날짜 관련 속성을 지원합니다.
- DatetimeIndex는 이러한 날짜 관련 속성을 포함하고 편리한 슬라이싱을 지원합니다.
- Resample은 시계열의 빈도를 변경하는 강력한 방법입니다.
'Python > Pandas' 카테고리의 다른 글
| Pandas 객체 생성 (0) | 2021.09.12 |
|---|---|
| Pandas 텍스트 데이터 다루기 (0) | 2021.08.21 |
| Pandas 활용 테이블 결합 방법 (0) | 2021.08.19 |
| Pandas 테이블 구조 변경 방법 (0) | 2021.08.18 |
| Pandas 활용 요약통계량 생성하기 (0) | 2021.08.17 |




댓글