본 내용을 보기 전에 Python 사전 준비 및 Python 완전 기초를 먼저 이해하셔야 합니다.
본 포스팅은 pandas 공식 홈페이지를 기반으로 작성하였습니다.
실습에 활용할 데이터는 titanic 승객 데이터입니다. 우선 python 내 데이터 프레임으로 변환하겠습니다.
import pandas as pd
titanic = pd.read_csv("D:/python_exer/titanic.csv")
titanic.head()

1. 요약통계량 생성 방안

1.1 타이타닉 승객의 평균 연령 구하기
titanic.mean()

다양한 통계량을 사용할 수 있고, 숫자 데이터가 있는 열에 적용할 수 있습니다. 일반적으로 누락된 데이터는 제외하고 기본적으로 여러 행에서 대해서 작업합니다.

1.2. 타이타닉 승객의 연령 및 항공권 운임 가격의 중위수 구하기
titanic[["Age", "Fare"]].mean()

DataFrame의 여러 열에 적용된 통계(두 열을 선택하면 DataFrame이 반환됨)는 각 숫자 열에 대해 계산됩니다. 또한, 요약 통계량을
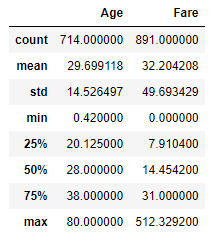
titanic[["Age", "Fare"]].describe()
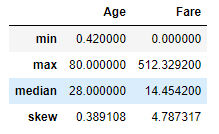
사전 정의된 통계량 대신 DataFrame.agg() 메서드를 사용하여 주어진 열에 대한 요약 통계량의 특정 조합을 정의할 수 있습니다.
titanic.agg(
____{
________"Age" : ["min","max","median","skew"] ,
________"Fare" : ["min","max","median","mean"]
____}
)
2. 범주별로 그룹화된 통계 집계
2.1. 타이타닉 승객 남녀의 평균 연령 구하기
titanic[["Age","Sex"]].groupby("Sex").mean()

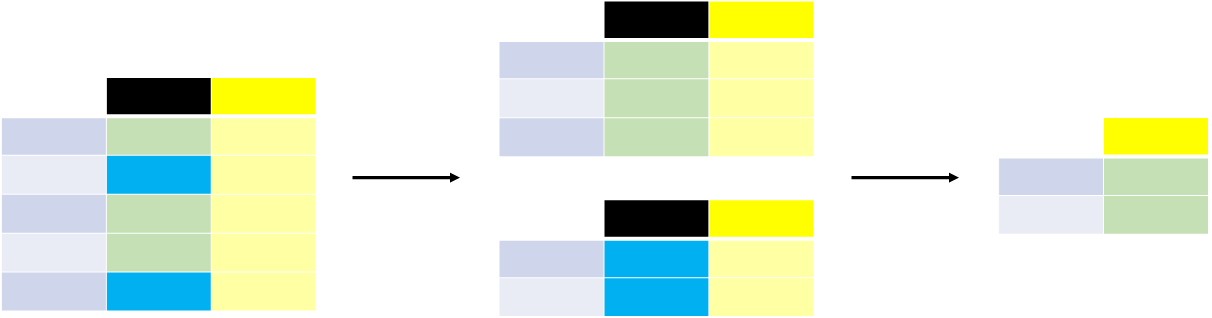
우리의 관심은 각 성별의 평균 연령이므로 이 두열(성별, 연령)에 대한 하위 선택(titanic[["Sex", "Age"]])이 먼저 이루어집니다. 다음으로 Groupby() 메서드를 Sex 칼럼에 적용하여 카테고리별로 그룹을 만든다. 각 성별의 평균 연령을 계산하여 반환합니다. 열의 각 범주(예: 성별 열의 남성/여성)에 대해 주어진 통계(예: 평균 연령)를 계산하는 것은 일반적인 패턴입니다. groupby 방법은 이러한 유형의 작업을 지원하는 데 사용됩니다. 더 일반적으로 이것은 더 일반적인 split-apply-combine 패턴에 맞습니다.
- Split: 데이터를 그룹으로 분할
- apply: 각 그룹에 독립적으로 기능 적용
- combine: 결과를 데이터 구조로 결합
적용 및 결합 단계는 일반적으로 pandas에서 함께 수행됩니다. 이전 예에서는 명시적으로 2개의 열을 먼저 선택했습니다. 그렇지 않은 경우 평균 함수가 숫자 열을 포함하는 모든 열에 적용됩니다.
titanic.groupby("Sex").mean()
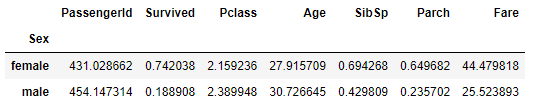
Pclass의 평균값을 구하는 것은 별로 의미가 없습니다. 각 성별의 평균 연령에만 관심이 있는 경우 그룹화된 데이터에서도 열 선택(평소처럼 대괄호 [])이 지원됩니다.
titanic.groupby("Sex")["Age"].mean()

Pclass 열은 숫자 데이터를 포함하지만 실제로는 각각 '1', '2' 및 '3' 레이블로 3개의 범주(또는 요인)를 나타냅니다. 이것에 대한 통계를 계산하는 것(ex. 평균값 등)은 별로 의미가 없습니다. 따라서 pandas는 이러한 유형의 데이터를 처리하기 위해 범주형 데이터 유형을 제공합니다.
2.2. 각 성별 및 객실 클래스 조합에 대한 평균 항공권 운임 구하기
titanic.groupby(["Age","Pclass"])["Fare"].mean()

그룹화는 동시에 여러 열로 수행할 수 있습니다. groupby() 메서드에 열 이름을 리스트로 제공합니다.
3. 범주별 레코드 수 계산
3.1. 각 객실 클래스의 승객 수 구하기
titanice["Pclass"].value_counts()

value_counts() 메서드는 열의 각 범주에 대한 레코드 수를 계산합니다. 이 기능은 실제로 각 그룹 내의 레코드 수를 계산하는 것과 결합된 groupby 작업이므로 바로 가기 함수입니다.
titanic.groupby("Pclass")["Pclass"].count()

size와 count 모두 groupby와 함께 사용할 수 있습니다. size는 NaN 값을 포함하고 행 수(테이블 크기)만 제공하는 반면 count는 누락된 값을 제외합니다. value_counts 메서드에서 dropna 인수를 사용하여 NaN 값을 포함하거나 제외합니다.
4. Remember!
- 전체 열 또는 행에 대해 집계 통계를 계산할 수 있습니다.
- groupby는 split-apply-combin 패턴의 힘을 제공합니다.
- value_counts는 변수의 각 범주에 있는 항목 수를 계산하는 편리한 바로 가기 함수입니다.
'Python > Pandas' 카테고리의 다른 글
| Pandas 활용 테이블 결합 방법 (0) | 2021.08.19 |
|---|---|
| Pandas 테이블 구조 변경 방법 (0) | 2021.08.18 |
| Pandas 신규 Column 생성 (0) | 2021.08.16 |
| Pandas에서 플롯 생성 방안 (0) | 2021.08.15 |
| Pandas 데이터프레임의 부분 데이터 세트 선택 방법 (0) | 2021.08.14 |




댓글