본 포스팅은 Pandas 패키지 라이브러리 원문을 기반으로 하여 작성하였습니다.
"group by"는 다음 단계 중 하나 이상을 포함하는 프로세스를 나타냅니다.
- Splitting: 일부 기준에 따라 데이터를 그룹으로 분할
- Applying: 각 그룹에 독립적으로 기능 적용
- Combining: 결과를 데이터 구조로 결합
import numpy as np
import pandas as pd
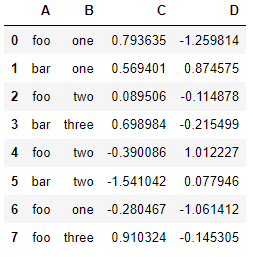
df = pd.DataFrame(
________{
__________"A": ["foo", "bar", "foo", "bar", "foo", "bar", "foo", "foo"],
__________"B": ["one", "one", "two", "three", "two", "two", "one", "three"],
__________"C": np.random.randn(8),
__________"D": np.random.randn(8),
________} )
df
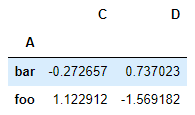
그룹화한 다음 결과 그룹에 sum() 함수 적용
df.groupby("A").sum()
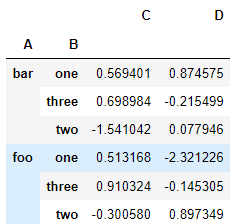
만약, 여러 열로 그룹화하면 계층적 인덱스가 형성되고, 다시 sum() 함수를 적용할 수 있습니다.
df.groupby(["A", "B"]).sum()
반응형
'Python > Pandas' 카테고리의 다른 글
| Pandas Time series (0) | 2021.09.20 |
|---|---|
| Pandas Reshaping (0) | 2021.09.19 |
| Pandas Merge (0) | 2021.09.17 |
| Pandas Operations (0) | 2021.09.16 |
| Pandas Missing data (0) | 2021.09.15 |




댓글