본 포스팅은 pandas 패키지 라이브러리 원문을 기반으로 하여 작성하였습니다.
1. Stack
tuples = list(
_______________zip(
____________________*[ ["bar", "bar", "baz", "baz", "foo", "foo", "qux", "qux"],
_____________________["one", "two", "one", "two", "one", "two", "one", "two"], ]
___________________)
______________)
tuples

index = pd.MultiIndex.from_tuples(tuples, names=["first", "second"])
index

df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=["A", "B"])
df
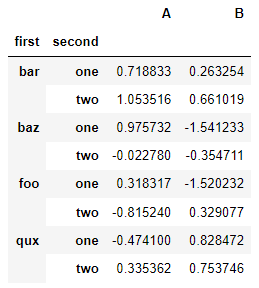
stack() 메서드는 DataFrame 열의 수준을 "압축"합니다.
stacked = df2.stack()
stacked

"stacked" DataFrame 또는 Series(MultiIndex를 인덱스로 사용)에서 stack()의 역 연산은 기본적으로 마지막 레벨을 unstack 하는 unstack()입니다.
stacked.unstack()
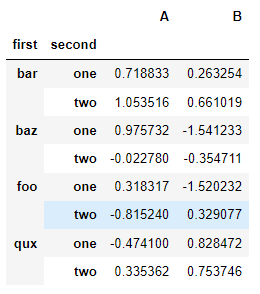
stacked.unstack(1)
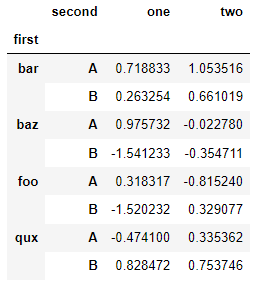
stacked.unstack(0)
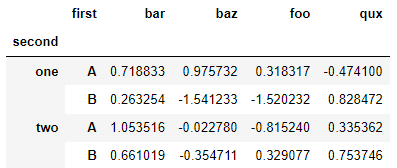
2. Pivot tables
df = pd.DataFrame(
______________{ "A": ["one", "one", "two", "three"] * 3,
_______________"B": ["A", "B", "C"] * 4,
_______________"C": ["foo", "foo", "foo", "bar", "bar", "bar"] * 2,
_______________"D": np.random.randn(12),
_______________"E": np.random.randn(12),
______________} )
df
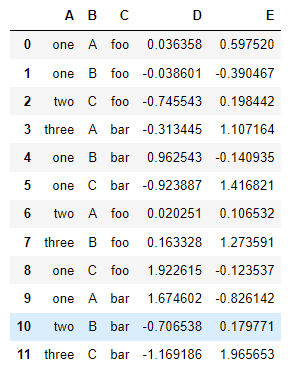
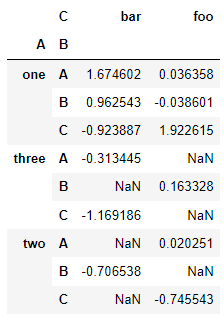
이 데이터에서 매우 쉽게 피벗 테이블을 생성할 수 있습니다.
pd.pivot_table(df, values="D", index=["A", "B"], columns=["C"])
반응형
'Python > Pandas' 카테고리의 다른 글
| Pandas Categoricals (0) | 2021.09.21 |
|---|---|
| Pandas Time series (0) | 2021.09.20 |
| Pandas Grouping (0) | 2021.09.18 |
| Pandas Merge (0) | 2021.09.17 |
| Pandas Operations (0) | 2021.09.16 |




댓글