이번 포스팅에서는 데이터 분석에 자주 사용되는
30가지의 유용한 python-pandas 함수/메서드를
정리하겠습니다.
1. 데이터 로드 및 이해
2. 열 또는 행 선택
3. 하나 이상의 열을 사용한 데이터 필터링
4. 데이터 정렬 및 열 삭제
5. 데이터 요약
사용한 데이터는 Kaggle의 Airlines.csv입니다.
pandas 패키지를 로드하는 것으로
시작하겠습니다.
import pandas as pd
1. CSV 파일 로드
# 1. csv 파일의 데이터를 메모리에 로딩
airlines = pd.read_csv("C:/Python_apply/Airlines.csv")
2. 데이터 프레임의 행과 열 수 얻기
# 2. Shape of a dataframe
airlines.shape
# 결과: (539383, 9)
3. 데이터 프레임의 처음/마지막 몇 행 가져오기
# 3.1. 데이터 프레임의 첫 부분 가져오기
airlines.head(n=10)

# 3.2. 데이터 프레임의 끝 부분 가져오기
airlines.tail(n=10)

4. 열의 데이터 유형 가져오기
# 4. 열의 데이터 유형
airlines.dtypes

5. 열 이름을 리스트로 가져오기
airlines.columns.tolist()

6. 숫자 열에 대한 요약 통계 가져오기
airlines.describe()

7. 열의 NA 값 수 얻기
airlines.isna().sum()
8. 데이터 유형이 object/int64인 열 선택
# 8.1. 데이터 유형이 object인 열 선택하기
airlines.select_dtypes(include = 'object').columns
# 결과: Index(['id', 'Flight', 'DayOfWeek', 'Time', 'Length', 'Delay'], dtype='object')
# 8.2. 데이터 유형이 int64인 열 선택하기
airlines.select_dtypes(include = 'int64').columns
# 결과: Index(['id', 'Flight', 'DayOfWeek', 'Time', 'Length', 'Delay'], dtype='object')
9. 열의 값 수 얻기
airlines['Airline'].value_counts(ascending=True)

10. 열에서 고유 값 가져오기
airlines['Airline'].unique()
# 결과: array(['CO', 'US', 'AA', 'AS', 'DL', 'B6', 'HA', 'OO', '9E', 'OH', 'EV', 'XE', 'YV', 'UA', 'MQ', 'FL', 'F9', 'WN'],
# dtype=object)
11. 몇 개의 열 선택
airlines[['id', 'Airline', 'Flight']]

12. .iloc을 사용하여 몇 개의 행 선택
airlines.iloc[:10,]

13. .loc을 사용하여 몇 개의 행과 열을 함께 선택
airlines.loc[:5, ['id', 'Airline', 'Flight']]

14. 열을 사용하여 데이터 필터링
airlines[airlines['Airline'] == 'US']

15. 여러 열을 사용하여 데이터 필터링
airlines[(airlines['Airline'] == 'US') & (airlines['AirportFrom'] == 'PHX') & (airlines['DayOfWeek'] == 1)]
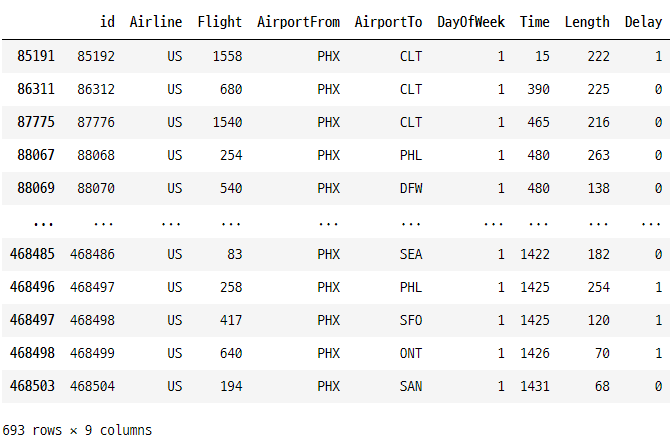
16. OR 조건을 사용하여 데이터 필터링
airlines[(airlines['Airline'] == 'US') | (airlines['AirportFrom'] == 'PHX')]

17. 리스트를 사용한 데이터 필터링
airlineList = ['DL','US']
airlines[airlines['Airline'].isin(airlineList)]

18. 리스트에 없는 데이터 필터링
airlineList = ['DL','US']
airlines[~airlines['Airline'].isin(airlineList)]

19. 열을 사용한 데이터 정렬
airlines.sort_values(by='Airline',ascending=False)

20. 열 이름 바꾸기
airlines.rename(columns={"Airline": "Airline_Code", "AirportFrom":"Airport_From"})

21. groupby를 사용한 데이터 요약
airlines.groupby(['Airline','AirportFrom','AirportTo'], as_index=False)['id'].agg('count')

22. 요약 및 정렬
airlinesSum = airlines.groupby(['Airline','AirportFrom','AirportTo'], as_index=False)['id'].agg('count')
airlinesSum.sort_values(by='id', ascending = False)

23. 여러 값에 대한 요약
airlines.groupby(['Airline','AirportFrom','AirportTo'])['Time'].agg(['sum','count']).reset_index()

24. 여러 열 및 값에 대한 요약
airlines.groupby(['Airline','AirportFrom','AirportTo']).aggregate({'id':'count','Time':'sum'}).reset_index()

25. 새 열 추가
airlines['Country'] = 'USA'
26. 기존 열을 사용하여 열 추가
airlines['CO_SFO'] = (airlines['Airline'] =='CO') & (airlines['AirportFrom'] == 'SFO')
airlines

27. 열 삭제
airlines.drop(['CO_SFO'], axis = 1)
28. 집계와 함께 pivot_table을 사용하여 요약
airlines.pivot_table(index = ['Airline','AirportFrom','AirportTo'], values = ['Time'], aggfunc=['sum','count']).reset_index(col_level=1)

29. 인덱스 열에 고유한 행을 사용할 수 없는 pivot_table을 사용한 데이터 피벗
airlines.pivot_table(index = 'Airline', columns='DayOfWeek', values='id',aggfunc='count', fill_value = 0).reset_index()

30. groupby 및 피벗을 사용하여 요약
airlines1 = airlines.groupby(['Airline','DayOfWeek'], as_index=False)['id'].agg('count').reset_index()
airlines1.pivot(index = ['Airline'], columns = 'DayOfWeek', values = 'id').reset_index()

반응형
'Python > Pandas' 카테고리의 다른 글
| 특정 행(Row) 혹은 열(Column) 선택을 위한 Pandas 함수 - filter (0) | 2023.05.21 |
|---|---|
| 데이터 랭글링(데이터 분석을 위한 15가지 Pandas 기능) (0) | 2023.02.24 |
| 거의 모든 데이터 분석 작업을 해결하는 Pandas 필터링 방법 (0) | 2022.07.02 |
| 알아두면 유용한 pandas 단편 정보들 (0) | 2022.06.30 |
| Map(), Apply(), ApplyMap() 함수 사용 방법 (0) | 2022.06.11 |
댓글