Pandas는 데이터 처리를 위한
강력한 라이브러리입니다.
데이터를 다루는 다양한 작업에
유용한 기능을 많이 제공하기 때문에
데이터 과학을 위한 맥가이버 칼과 같습니다.
이 도구를 효과적으로 사용하려면
몇 가지 트릭을 알아야 합니다.
본 포스팅에서는
정기적으로 사용하는
유용한 pandas 단편 정보에 대해
자세히 설명하겠습니다.
Pandas 라이브러리에 대한
이해가 있는 경우
아래 정보들이 유용할 수 있습니다.
Pandas에 익숙하지 않은 분들을 위해
몇 가지 예를 통해 라이브러리를
더 잘 이해하는 데 도움이 되도록 하겠습니다.
이 포스팅에서 사용된 데이터 세트는
Kaggle에 있는 자료입니다.
(https://www.kaggle.com/competitions/house-prices-advanced-regression-techniques/data)
Reading Data
read_csv는 단순히
데이터를 읽는 것 이상의
작업을 수행할 수 있습니다.
import pandas as pd
housePrices = pd.read_csv("C:/Temp/Temp1/python_exer/train.csv")
housePrices.head()

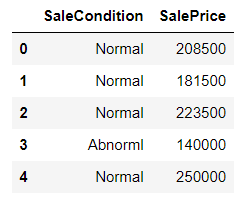
1. 열 필터링
전체 데이터세트에서 특정 몇 개의 열만 필요합니까? => usecols
import pandas as pd
housePrices = pd.read_csv("C:/Temp/Temp1/python_exer/train.csv", usecols = ["SaleCondition", "SalePrice"])
housePrices.head()
2. Parse dates on read
pd.to_datetime을 수행할 필요가 없습니다.
읽을 때 파싱처리를 수행합니다.
tesla = pd.read_csv("C:/Temp/Temp1/python_exer/Tesla.csv", parse_dates = ["Date"])
tesla.head()

3. 데이터 유형 지정
읽을 때 범주 데이터 유형을 설정하면
데이터 프레임에 대한
엄청난 양의 메모리를 절약할 수 있습니다.
housePrices = pd.read_csv("C:/Temp/Temp1/python_exer/train.csv", dtype = {"HouseStyle":"category"})
housePrices["HouseStyle"]

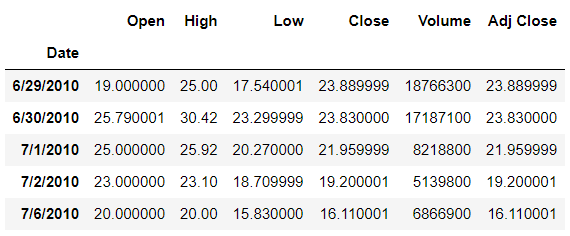
4. Set index
인덱스 설정은 시계열 데이터에
특히 유용합니다.
tesla = pd.read_csv("C:/Temp/Temp1/python_exer/Tesla.csv", index_col = "Date")
tesla.head()
5. 읽을 행 수 지정
수백만 개의 행이 있는
데이터 세트를 살펴보기 전에
데이터를 읽고 싶지 않습니까? => nrows!
tesla = pd.read_csv("C:/Temp/Temp1/python_exer/Tesla.csv", nrows = 2)
tesla

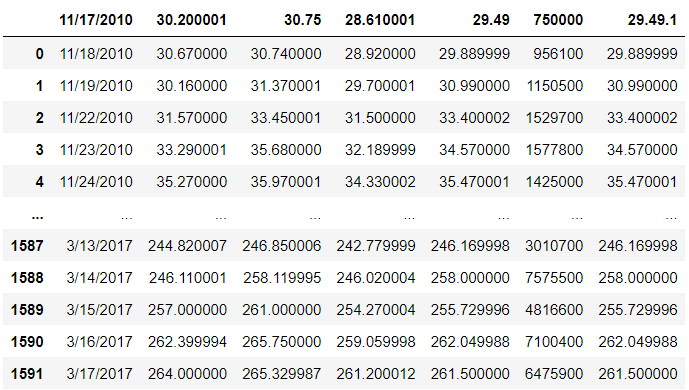
6. Skip rows
데이터 세트에 잘못된 데이터가
있는 행이 있습니까? => skiprows
# skips line 1 and 5
pd.read_csv("C:/Temp/Temp1/python_exer/Tesla.csv", skiprows = [1, 5])

# skips the first 100 lines
pd.read_csv("C:/Temp/Temp1/python_exer/Tesla.csv", skiprows = 100)
# skip 90% of the rows
import numpy as np
pd.read_csv("C:/Temp/Temp1/python_exer/Tesla.csv", skiprows = lambda x: x > 0 and np.random.rand() > 0.1)

7. NA 값 지정
데이터에 "?"와 같은 값을
NA로 처리하고 싶은 경우,
데이터를 읽어 올 때,
바로 처리할 수 있습니다.
# "RL"을 NA 값으로 대체하고 싶을 때,
housePrices = pd.read_csv("C:/Temp/Temp1/python_exer/train.csv", na_values = ["RL"])
housePrices.head()

housePrices = pd.read_csv("C:/Temp/Temp1/python_exer/train.csv")
housePrices.head()

8. 부울 값 설정
부울 값을 의미하는 열이 있나요?
해당 값을 설정할 수 있습니다.
# 열의 값이 "yes" 면 true로 간주함
# 열의 값이 "no" 면 false로 간주함
pd.read_csv("C:/Temp/Temp1/python_exer/Tesla.csv", true_values=["yes"], false_values=["no"])
9. 여러 파일에서 읽기
데이터가 여러 파일에 있나요?
glob으로 모두 읽어올 수 있습니다.
import glob
import os
files = glob.glob("C:/Temp/Temp1/python_exer/tesla/Tesla_*.csv")
teslaTotal = pd.concat([pd.read_csv(f) for f in files], ignore_index=True)
Exploratory Data Analysis (EDA)
1. EDA cheat
데이터 세트를 시각화하고 싶지만
코드는 작성하고 싶지 않나요?
=> pandas_profiling
import pandas_profiling
housePrice = pd.read_csv("C:/Temp/Temp1/python_exer/train.csv")
profile = housePrice.profile_report(title = "Pandas Profiling Report")
profile.to_file(output_file = "C:/Temp/Temp1/python_exer/output.html")
Data Types (dtypes)
1. dtype으로 열 필터링
# 선택
housePrices.select_dtypes(include = "number")
housePrices.select_dtypes(include = ["object", "datetime"])
# 제외
housePrices.select_dtypes(exclude = "object")
2. dtype 추론
숫자 열을 개체(object)로 읽었습니까?
pandas에서 변환 작업을 하면 됩니다.
housePrices.infer_objects().dtypes
3. Downcasting
Pandas의 to_numeric에는
유형을 다운캐스팅하는 기능이 있어
데이터 프레임의 크기를
줄일 수 있습니다.
pd.to_numeric(housePrices.MSSubClass, downcast="integer")

pd.to_numeric(housePrices.LotFrontage, downcast="float")

4. 수동 변환
데이터에 NaN 값이 있는 경우
errors = "coerce"는 이러한
심각한 오류를 방지하는 데
도움이 될 수 있습니다.
동시에 .fillna를 사용하여
해당 NA 값을 합리적인 값으로
채울 수 있습니다.
# 전체 데이터 프레임에 적용
housePrice = housePrice.apply(pd.to_numeric, errors = "coerce")
# 특정 칼럼에 적용
pd.to_numeric(housePrice.MSSubClass, errors = "coerce")
# NA 값을 0으로 대체
pd.to_numeric(df.MSSubClass, errors="coerce").fillna(0)
errors: error는 총 3개의 옵션이 존재합니다.
숫자로 변경할 수 없는 값이 존재할 경우,
- errors = 'ignore'
: 숫자로 변경하지 않고 원본 데이터를 그대로 반환
- errors = 'coerce' ->
: 기존 데이터를 지우고 NaN으로 설정하여 반환
- errors = 'raise' ->
: 에러를 일으키며 코드를 중단합니다.
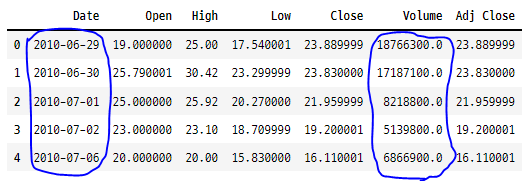
5. 한 번에 여러 열의 데이터 유형 변환하기
tesla.head()

tesla = tesla.astype(
{
"Date": "datetime64[ns]",
"Volume": "float"
}
)
tesla.head()
열 작업
1. 열 이름 변경
tesla = tesla.rename({"Date" : "baseYmd", "Volume" : "amt"}, axis = 1)
tesla.head()
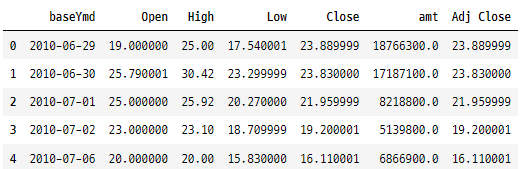
2. 접미사 및 접두사 추가
tesla.add_prefix("pre_").head()

tesla.add_suffix("_suff").head()
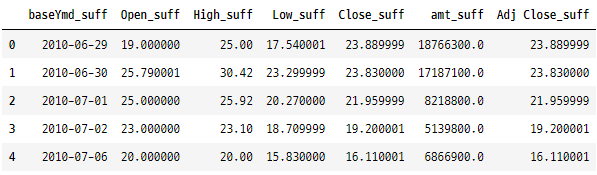
3. 새로운 열 생성(dplyr 용어로 변경)
tesla.assign( amt_10000 = lambda x : x.amt / 10000).head()
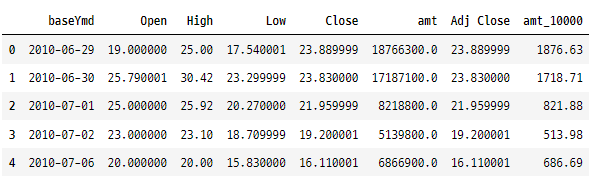
4. 특정 위치에 열 삽입
import numpy as np
randomNumber = np.random.randint(10, size = len(tesla))
# 3번째 열 다음 위치에 삽입
tesla.insert(3, 'temp', randomNumber).head()
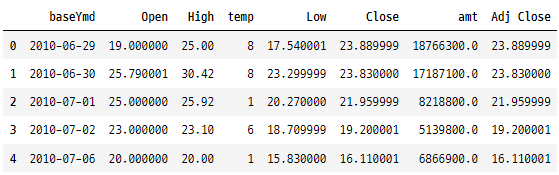
5. if-then-else
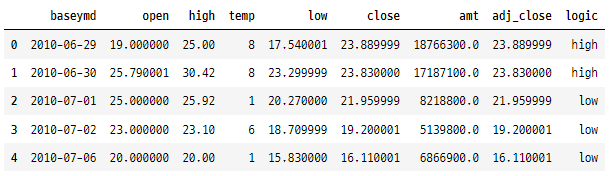
tesla["logic"] = np.where(tesla["amt"] > 10000000, "high", "low")
tesla.head()

6. 열 삭제
## temp 열 삭제
# case1
tesla.drop('temp', axis = 1, inplace = True)
# case2
tesla = tesla.pop('temp')
# case3
del df['temp']
# case4 - 위치기반 삭제
tesla.drop(tesla.columns[3], inplace=True)
# temp 및 logic 열 삭제
tesla = tesla.drop(['temp','logic'], axis=1)
문자열 연산
1. 열 이름 관련
# 모든 열 이름을 소문자로 변환
tesla.columns = tesla.columns.str.lower()
tesla.head()

# 열의 공백을 '_'로 변경
tesla.columns = tesla.columns.str.replace(' ', '_')
tesla.head()
2. 포함 여부 확인
# 'SaleCondition' 열에 'Nor' 문자열 포함여부
housePrice['SaleCondition'].str.contains("Nor").head()

# 'SaleCondition' 열의 값 중에서 7개의 문자로 구성되고 있고, 두 번째 문자가 'b'이고, 다섯 번째 문자가 'r'인지 여부
housePrice['SaleCondition'].str.contains(".b..r..", regex = True).head() # regex

Missing values
1. 모든 열에 대해서 missing values 비율 확인
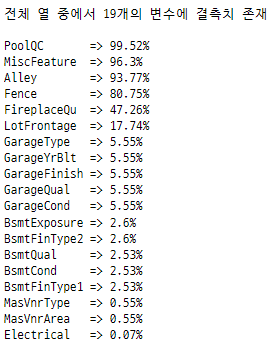
def missing_value_check(df):
"""열 이름과 missing value 비율 출력"""
missing = [
(housePrice.columns[idx], perc)
for idx, perc in enumerate(housePrice.isna().mean() * 100)
if perc > 0
]
if len(missing) == 0:
return "no missing values"
# sort desc by perc
missing.sort(key = lambda x: x[1], reverse = True)
print(f"전체 열 중에서 {len(missing)}개의 변수에 결측치 존재\n")
for tup in missing:
print(str.ljust(f"{tup[0]:<12} => {round(tup[1], 2)}%", 1))
missing_value_check(housePrice)
2. 결측치 처리하기
# 결측치가 있는 행 삭제
housePrice.dropna(axis=0)
# 결측치가 있는 열 삭제
housePrice.dropna(axis=1)
## 결측치 대체
# 0으로 대체
housePrice.fillna(0)
# 결측치의 바로 앞에 있는 값으로 대체
housePrice.fillna(method="ffill")
# 결측치의 바로 뒤에 있는 값으로 대체
housePrice.fillna(method='bfill')
# -999를 결측치로 대체
housePrice.replace( -999, np.nan)
# "?"를 결측치로 대체
housePrice.replace("?", np.nan)
# 보간법 사용
# 시계열 데이터의 시간 간격 고려
ts.interpolate()
# 앞에서부터 모든 연속된 값으로 보간
housePrice.interpolate()
# 연속된 결측치 중 제일 처음 나오는 결측치 1개만 보간
housePrice.interpolate(limit=1)
# 연속된 결측치 중 제일 처음 마지막 결측치 1개만 보간
housePrice.interpolate(limit=1, limit_direction = "backward")
# 양 방향으로 보간
housePrice.interpolate(limit_direction="both")
날짜 연산
1. 기본
from datetime import date
# 오늘 + 후에
date.today() + datetime.timedelta(hours = 30)
# datetime.date(2022, 7, 1)
date.today() + datetime.timedelta(days = 30)
# datetime.date(2022, 7, 30)
date.today() + datetime.timedelta(weeks = 30)
# datetime.date(2023, 1, 26)
# 오늘 - 전에
date.today() - datetime.timedelta(days = 365)
# datetime.date(2021, 6, 30)
2. 두 날짜 사이 조건
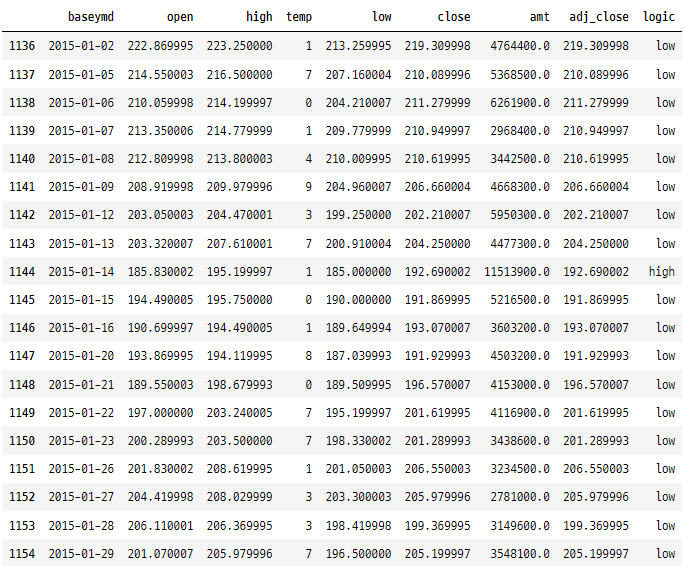
tesla[(tesla["baseymd"] > "2015-01-01") & (tesla["baseymd"] < "2015-01-30")]
3. 일/월/년으로 필터링
# 특정일로 필터링
tesla[tesla["baseymd"].dt.strftime("%Y-%m-%d") == "2017-03-01"]

# 연속되지 않은 특정일 2개로 필터링
tesla[tesla["baseymd"].dt.strftime("%Y-%m-%d").isin(["2017-03-01","2017-03-03"])]

# 특정 월로 필터링
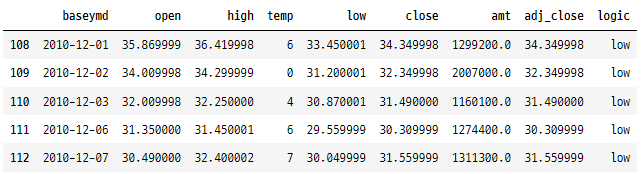
tesla[tesla["baseymd"].dt.strftime("%m") == "12"].head()
# 특정년으로 필터링
tesla[tesla["baseymd"].dt.strftime("%Y") == "2017"].head()
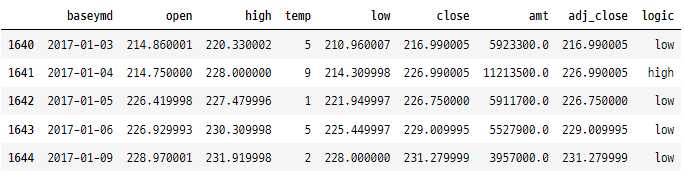
데이터 프레임 스타일 지정
1. 숫자 형식
formatDict = {
"baseymd": "{:%d/%m/%y}",
"open": "${:.2f}",
"close": "${:.2f}",
"amt": "{:,}",
}
tesla.style.format(formatDict)
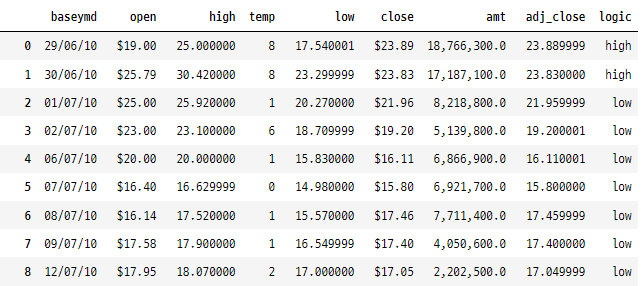
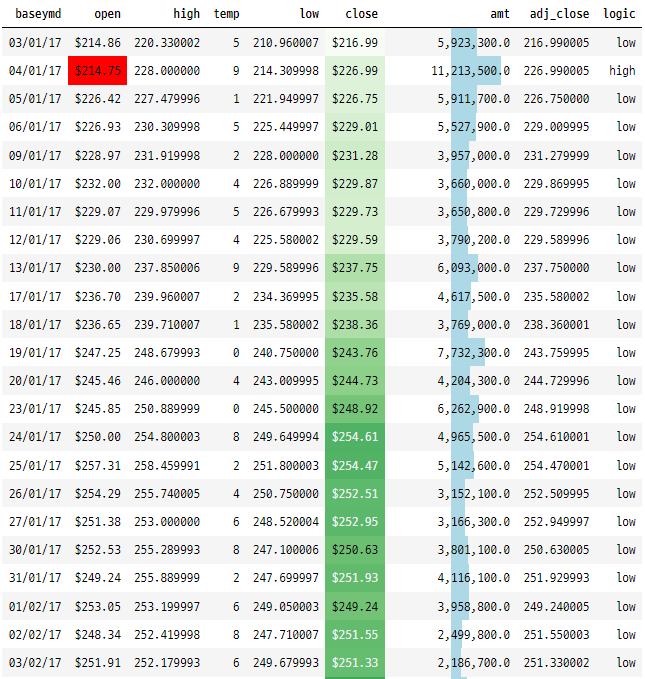
2. 색상 설정
(
tesla[tesla["baseymd"].dt.strftime("%Y") == "2017"].style.format(formatDict)
.hide_index()
.highlight_min(["open"], color="red")
.highlight_max(["open"], color="green")
.background_gradient(subset="close", cmap="Greens")
.bar('amt', color='lightblue', align='zero')
.set_caption('2017년 테슬라 주가')
)
기타
1. 열의 최대 및 최소 Index 가져오기
tesla['amt'].idxmin()
# 82
tesla['amt'].idxmax()
# 723
2. 데이터 프레임에 함수 적용
tesla[["open","high","temp","low","close","amt"]].applymap(lambda x : np.log(x)).head()

3. 무작위로 데이터 섞기
tesla.sample(frac = 1, random_state = 7).reset_index(drop = True).head()
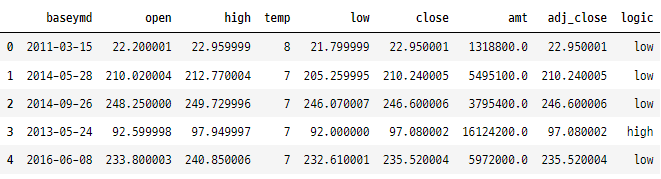
4. 순위 지정
# amt 열의 순위 생성
tesla['amtRank'] = tesla['amt'].rank()
tesla.head()
5. 리스트 값을 여러 행으로 분해
df.explode("col_name").reset_index(drop=True)
6. 작은 범주를 "other"로 변환
subClass = housePrice["LotShape"]
subClass.value_counts()

topTwo = subClass.value_counts().nlargest(2).index
subClassNew = subClass.where(subClass.isin(topTwo), other = "other")
subClassNew.value_counts()

'Python > Pandas' 카테고리의 다른 글
| Python-Pandas 함수 및 메서드(30) (0) | 2022.09.18 |
|---|---|
| 거의 모든 데이터 분석 작업을 해결하는 Pandas 필터링 방법 (0) | 2022.07.02 |
| Map(), Apply(), ApplyMap() 함수 사용 방법 (0) | 2022.06.11 |
| Pandas 데이터를 그룹화하는 가장 좋은 방법(groupby, Grouper) (0) | 2022.06.01 |
| pandas value_counts() 함수 (0) | 2022.05.02 |
댓글