본 포스팅은 R for Data Science 를 기반으로 작성되었습니다.
1. 날짜와 시간 생성하기
시간에 있어 순간을 참조하기 위한 세 가지 유형의 데이터가 있습니다.1) 날짜(Data), 2) 시간(Time), 3) 날짜와 시간 병합(Date-Time) : 이 유형은 3가지 특정 시점을 유니크하게 식별할 수 있습니다.
현재 날짜를 알고 싶으면 today() 함수를 사용하면 되고, 현재 날짜와 시간을 동시에 알고 싶으면 now() 함수를 사용하면 됩니다.

만약 특정 날짜 혹은 특정 시간을 생성하려면 아래 3가지 방법이 있습니다.
1) 문자열 활용
2) 날짜와 시간 구성 요소 활용
3) 기존에 존재하는 날짜와 시간 object 활용
1.1. 문자열 활용
날짜와 시간 데이터는 자주 문자열로 제공됩니다. 날짜와 시간 데이터에 접근하기 가장 쉬운 방법은 lubridate package를 사용하는 것입니다. lubridata package는 날짜와 시간을 구성하는 요소들의 순서를 지정하면 자동으로 날짜와 시간 형식을 계산합니다. 사용방법은 날짜 데이터에 연(year), 월(month), 일(day)이 나타나는 순서를 확인한 다음 "y", "m", "d"를 같은 순서로 정렬해 주시면 됩니다.
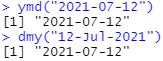
"y", "m", "d" 를 활용하는 이러한 함수는 인용 부호가 없는 숫자에도 사용합니다. 날짜와 시간 데이터를 필터링할 때 필요할 수 있는 단일 날짜와 시간 object를 만드는 가장 간결한 방법입니다. ymd 함수는 간단하고, 명확합니다.
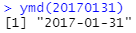
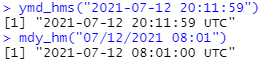
ymd와 함께 시간(hour), 분(minute), 초(second)를 나타내는 표현들을 추가하여 날짜를 생성할 수 있습니다. 날짜와 시간 데이터를 생성하려면 파싱 함수의 이름에 밑줄과 "h", "m", "s" 중 하나 이상을 추가하면 됩니다.
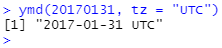
또한, 시간대(time zone)를 제공함으로서 날짜에서 날짜와 시간 데이터를 강제로 생성할 수도 있습니다.
1.2. 날짜와 시간의 개별 구성요소 활용
날짜와 시간 데이터가 단일 문자열 대신 여러 열의 개별 구성 요소로 분산되어 있는 경우도 있습니다. 아래는 nycflights13 라이브러리에 있는 flights 데이터입니다.
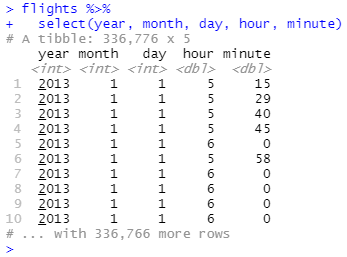
날짜와 시간을 나타내는 여러 열의 개별 구성 요소로 이루어진 데이터에서 날짜와 시간을 생성하려면 날짜 데이터에 make_date() 함수를 사용하거나 날짜와 시간 데이터에 make_datetime()을 사용하면 됩니다.
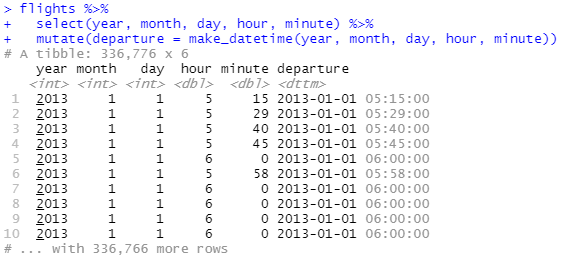
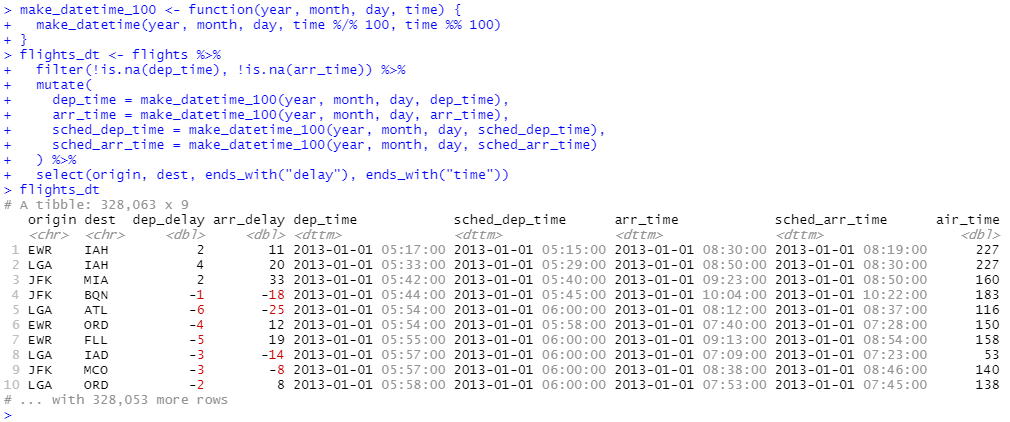
flights 데이터에서 시간을 나타내는 4개의 열에 대해 동일한 작업을 수행해 보겠습니다. 시간 데이터가 약간 이상한 형식으로 값이 들어가 있어, 모듈러스 산술을 사용하여 시간 및 분 구성요소를 추출합니다. 일단, 날짜와 시간 데이터 변수를 만든 후에는 이 장의 나머지 부분에서 탐색할 변수에 중점을 두도록 하겠습니다.
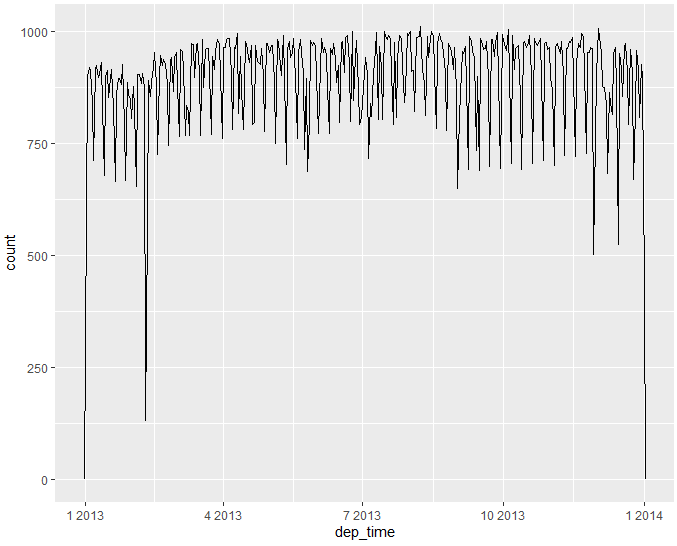
이 데이터를 사용하여 연도별 출발 시간 분포를 시각화할 수 있습니다.

또는 하루 동안의 출발 시간 분포를 구해볼 수 있습니다.


히스토그램과 같이 숫자 컨텍스트에서 날짜와시간 데이터를 사용할 때 1은 1초를 의미하므로 binwidth = 86400은 하루를 의미합니다. 날짜 데이터의 경우 1은 1일을 의미합니다.
1.3. 기타 다른 형태 활용
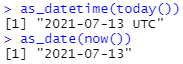
날짜와 시간 데이터 <-> 날짜 데이터를 서로 변환하고 싶을 때도 있을 꺼에요. 이럴 경우, as_datetime() 함수와 as_date() 함수를 사용하면 됩니다.
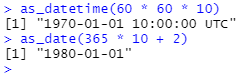
때로는 1970-01-01을 기준으로 날짜와 시간 데이터를 숫자 오프셋으로 얻을 수 있습니다.
2. 날짜와 시간 데이터 구성요소
이번 장에서는 날짜와 시간 데이터의 개별 구성 요소를 가져오고 설정할 수 있는 함수에 중점을 두도록 하겠습니다.
2.1. 구성 요소 가져오기
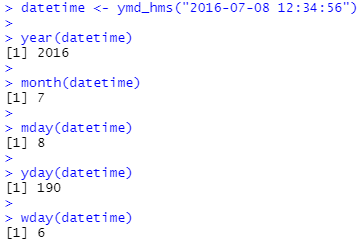
여러분들은 함수 year(), month(), mday() (day of the month), yday() (day of the year), wday() (day of the week), hour(), minute(), and second()를 사용하여 날짜의 개별 구성요소들을 가져올 수 있습니다.
month() 및 wday() 함수의 경우 label = TRUE 옵션을 설정하여 해당 월 또는 요일의 축약된 이름을 반환할 수 있습니다. 만약, 전체 이름을 반환하려면 abbr = FALSE 옵션을 설정하시면 됩니다.

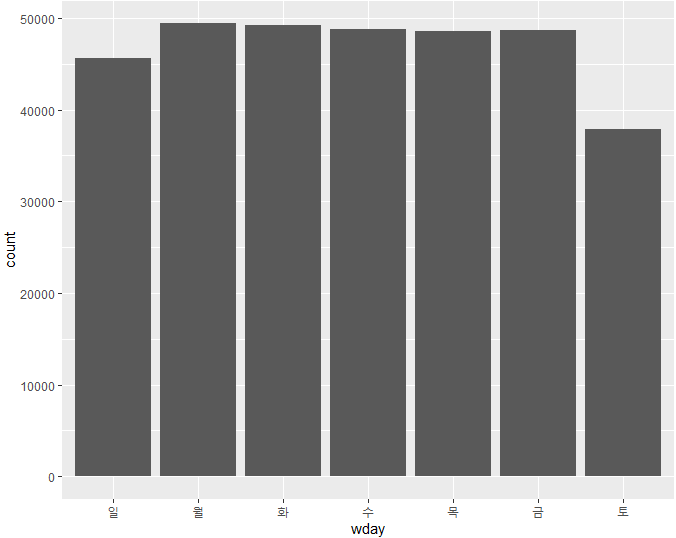
wday() 함수를 사용하면 주말보다 주중에 더 많은 항공편이 출발하는지도 확인할 수 있습니다.

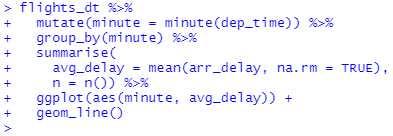
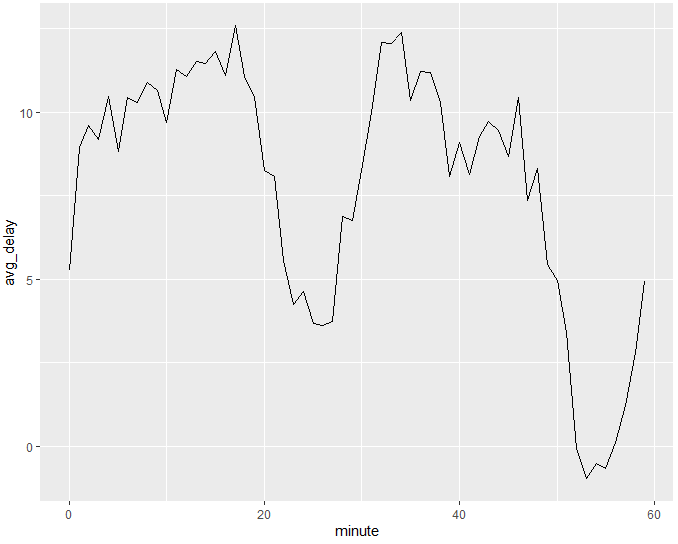
한 시간 안에 분 단위로 평균 출발 지연을 보면 흥미로운 패턴을 발견할 수 있습니다. 아래 그래프를 보면, 20-30분 및 50-60분에 출발하는 항공편이 나머지 시간보다 지연 시간이 훨씬 적은 것 같습니다!
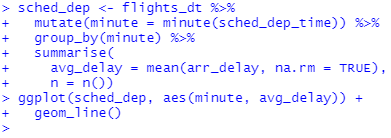
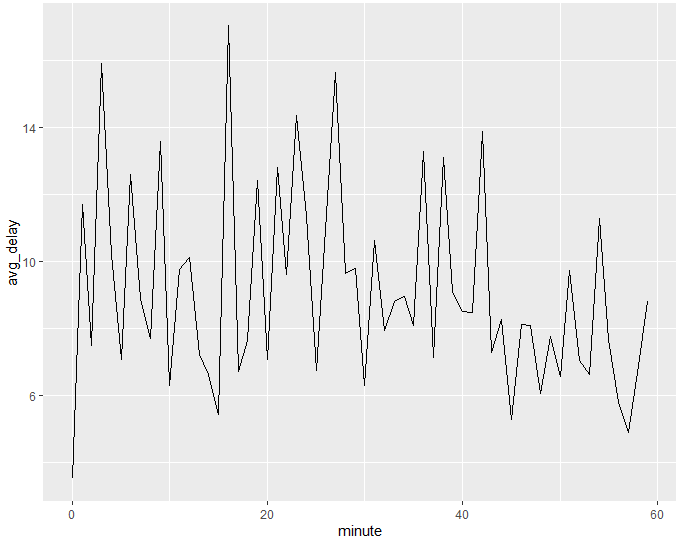
흥미롭게도 예정된 출발 시간을 보면 그렇게 강한 패턴을 볼 수 없습니다.
2.2. 반올림
개별 구성 요소를 다루는 다른 방법은 floor_date(), round_date() 및 ceiling_date() 함수를 사용하여 날짜를 가까운 시간 단위로 반올림하는 것입니다. 위에 나열된 각 함수는 조정할 날짜 벡터를 취한 다음, 단위 이름을 내림, 올림 또는 반올림합니다. 예를 들어 이를 통해 주당 항공편 수를 표시할 수 있습니다.

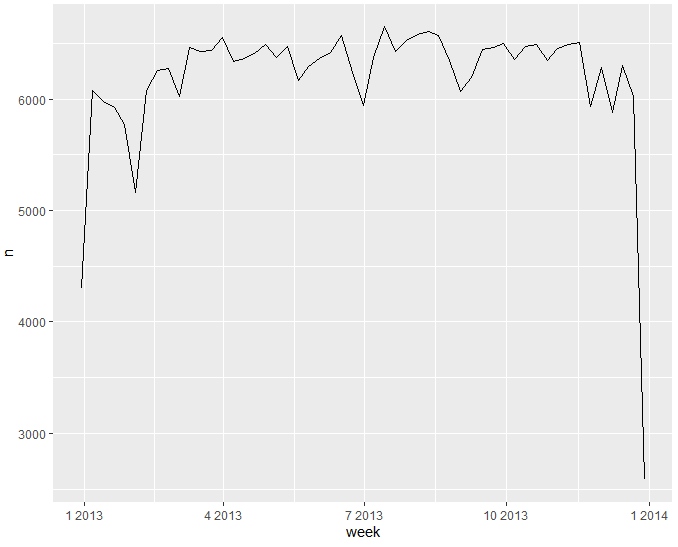
반올림 날짜와 반올림되지 않은 날짜 간의 차이를 계산하는 것이 특히 유용할 수 있습니다.
2.3. 구성 요소 설정
날짜와 시간 데이터에 대한 함수를 사용하여 날짜와 시간 데이터의 구성 요소를 설정할 수 있습니다.
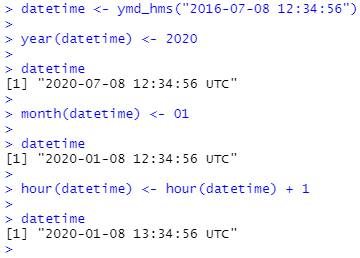
구성요소의 자리를 수정하는 대신 update() 함수를 사용하여 새로운 날짜와 시간 데이터를 만들 수 있습니다. 이렇게 하면 한 번에 여러 값을 설정할 수도 있습니다.

값이 너무 크면 롤오버됩니다.
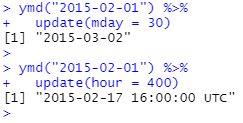
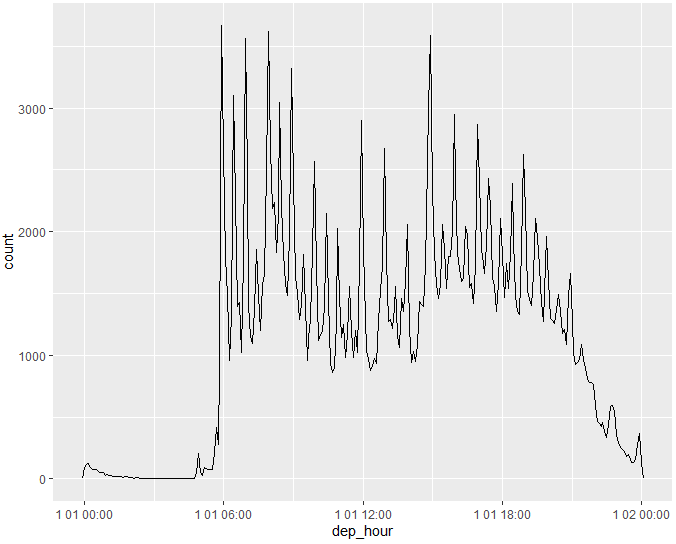
update()를 사용하여 연중 매일의 하루 중 항공편 분포를 표시할 수 있습니다.

3. 시간 범위
다음으로는 덧셈, 뺄셈, 나눗셈을 포함하여 날짜를 사용한 산술이 작동하는 방식에 대해 배워 보겠습니다. 그 과정에서 시간 범위를 나타내는 세 가지 중요한 클래스에 대해 배우게 됩니다.
duration: 정확한 시간(초)을 나타내는 지속 시간
period: 주 및 월과 같은 단위를 나타내는 기간
intervals: 시작점과 끝점을 나타내는 간격
3.1. Duration
R에서 두 날짜를 빼면 difftime 객체를 얻습니다.

difftime 클래스 객체는 초, 분, 시간, 일 또는 주의 시간 범위를 기록합니다. 이러한 모호성은 difftime을 사용하는 데 약간의 혼란을 줄 수 있어 lubridate 패키지는 항상 초를 사용하는 대안인 지속 시간을 제공합니다. 이를 duration이라고 합니다.

Duration에는 아래의 예시처럼 편리하게 생성할 수 있는 함수가 많이 있습니다.
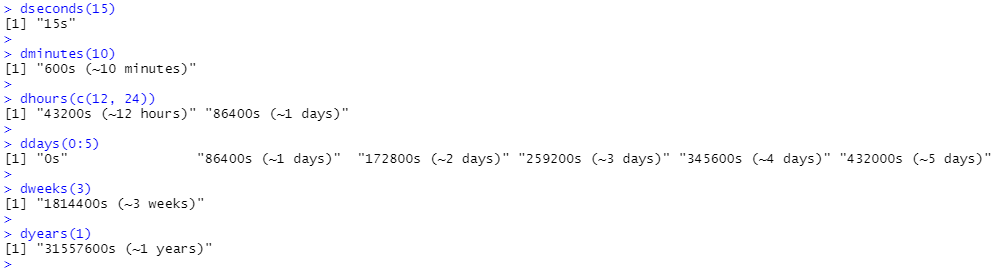
duration은 항상 시간 범위를 초 단위로 기록합니다. 더 큰 단위는 표준 비율(분에 60초, 한 시간에 60분, 하루에 24시간, 일주일에 7일, 한 주에 365일)에서 분, 시간, 일, 주 및 년을 초로 변환하여 생성됩니다. duration을 더하고 곱할 수 있습니다.
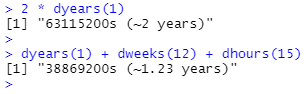
더하거나 뺄 수도 있습니다.
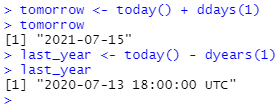
그러나 duration은 정확한 초 수를 나타내기 때문에 때때로 원하지 않은 결과가 나타날 수 있습니다.
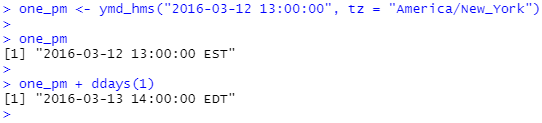
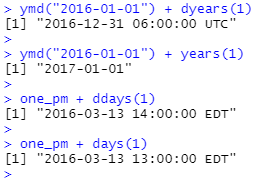
3월 12일 오후 1시 하루를 더했는데, 왜 3월 13일 오후 2시일까요? 날짜를 자세히 보시면 시간대가 변경되었음을 알 수 있습니다. DST로 인해 3월 12일에는 23시간만 있으므로 전체 일에 해당하는 초를 추가하면 다른 시간이 됩니다.
3.2. Period
앞선 문제를 해결하기 위해 lubridate 패키지는 기간(period)을 제공합니다. period는 시간 범위이지만 초 단위로 고정된 길이가 아니라 일 및 월과 같은 "인간" 시간으로 작동합니다. 이를 통해 보다 직관적인 방식으로 작업할 수 있습니다.
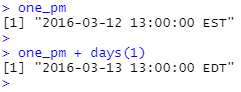
duration과 마찬가지로 여러 친숙한 생성자 함수를 사용하여 기간을 만들 수 있습니다.

period도 더하고 곱할 수 있습니다.
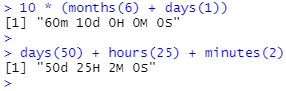
날짜에 추가해 보세요. duration에 비해 period는 우리가 예상한 대로 수행될 가능성이 더 높습니다.
period를 사용하여 비행 날짜와 관련된 이상한 점을 수정해 보겠습니다. 일부 비행기는 뉴욕시에서 출발하기 전에 목적지에 도착한 것으로 보입니다.
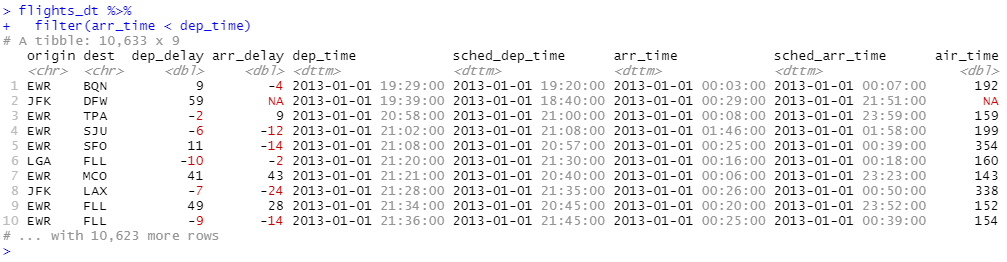
야간비행이 있습니다. 출발시간과 도착시간 모두 같은 날짜 정보를 사용했지만 이 항공편은 다음날 도착했습니다. 각 야간 항공편의 도착 시간에 일(1)을 추가하여 이 문제를 해결할 수 있습니다. 이제 우리의 모든 비행은 물리 법칙을 따릅니다.

3.3. Intervals
dyears(1) / ddays(365)가 무엇인지는 분명합니다. duration은 항상 초로 표시되고, 1년의 기간은 365일의 초로 정의되기 때문입니다. 그렇다면, years(1) / days(1)의 결과는 어떨까요? 연도가 2015년이면 365를 반환해야 하지만 2016년이면 366을 반환해야 합니다! lubridate 패키지가 하나의 명확한 답변을 제공하기에 충분한 정보가 없습니다. 대신 아래와 같은 경고와 함께 추정치를 제공합니다.

더 정확한 측정을 원하면 interval(간격)을 사용해야 합니다. interval은 시작점이 있는 기간입니다. 얼마나 오래 걸리는지 정확히 결정할 수 있도록 정확합니다.
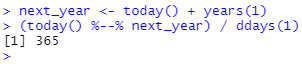
얼마나 많은 기간이 interval에 속하는지 알아보려면 %/%를 사용해야 합니다.

3.4. 요약
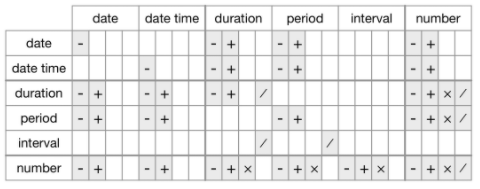
duration, period 및 intervals 중에서 선택하는 기준 무엇일까요? 항상 그렇듯이 문제를 해결하는 가장 간단한 데이터 구조를 선택하시면 됩니다. 물리적 시간만 고려한다면 duration을 사용하세요. 인간적인 시간을 추가해야 하는 경우 period를 사용하세요. 인간적인 단위로 얼마나 긴지 알아내야 하는 경우라면 intervals을 사용하시면 됩니다. 서로 다른 데이터 유형 간에 허용되는 산술 연산을 요약합니다.
3.5. Time zone (시간대)
시간대는 지정학적 위치와의 상호 작용 때문에 매우 복잡한 주제입니다. 다행스럽게도 모든 세부 사항이 데이터 분석에 중요하지 않기 때문에 모든 세부 사항을 파헤칠 필요는 없지만, 해결해야 할 몇 가지 문제가 있습니다.
첫 번째 문제는 시간대의 일상적인 이름이 모호한 경향이 있다는 것입니다. 예를 들어, 미국인이라면 EST 또는 동부 표준시(Eastern Standard Time)에 익숙할 것입니다. 그러나 호주와 캐나다에도 EST가 있습니다! 혼란을 피하기 위해 R은 국제 표준 IANA 시간대를 사용합니다. 이들은 일반적으로 "<대륙>/<도시>" 형식의 일관된 명명 체계 "/"를 사용합니다(모든 국가가 대륙에 있는 것은 아니기 때문에 몇 가지 예외가 있습니다). 예로는 "America/New_York", "Europe/Paris" 및 "Pacific/Auckland"가 있습니다.
일반적으로 표준 시간대를 국가 또는 국가 내의 지역과 관련된 것으로 생각할 때 표준 시간대에 도시가 사용되는 이유는 IANA 데이터베이스 수십 년 동안의 표준 시간대 규칙을 기록해야 하기 때문입니다. 수십 년 동안 국가는 이름을 상당히 자주 변경(또는 분리)하지만 도시 이름은 그대로 유지되는 경향이 있습니다. 또 다른 문제는 이름이 현재 행동뿐만 아니라 전체 기록을 반영해야 한다는 것입니다. 예를 들어 "America/New_York" 및 "America/Detroit" 모두에 대한 시간대가 있습니다. 이 두 도시는 현재 동부 표준시를 사용하지만 1969-1972년에 미시간(디트로이트가 위치한 주)에서는 DST를 따르지 않았으므로 다른 이름이 필요합니다. 이러한 이야기 중 일부를 읽기 위해 원시 시간대 데이터베이스(http://www.iana.org/time-zones에서 사용 가능)를 읽을 가치가 있습니다!
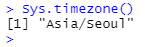
Sys.timezone() 함수를 사용하여 R 환경에서의 현재 시간대를 알 수 있습니다.
OlsonNames() 함수를 사용하면 R에서 제공하는 모든 시간대 이름의 목록을 확인할 수 있습니다.

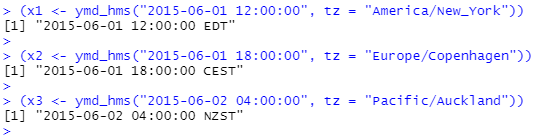
R에서 시간대는 인쇄만 제어하는 날짜-시간 속성입니다. 예를 들어, 다음 세 객체는 동일한 순간을 나타냅니다.
빼기를 사용하면 동일한 시간인지 확인할 수 있습니다.

lubridate 패키지의 디폴트는 항상 UTC를 사용합니다. UTC(협정 세계시)는 과학계에서 사용하는 표준 시간대이며 이전 GMT(그리니치 표준시)와 거의 동일합니다. DST가 없으므로 계산에 편리한 표현입니다. c()와 같이 날짜와 시간 데이터를 결합하는 작업은 종종 표준 시간대를 삭제하게 됩니다. 이 경우 날짜와 시간 데이터는 현지 시간대로 표시됩니다.

두 가지 방법으로 시간대를 변경할 수 있습니다. 첫번째 방법은 순간을 동일하게 유지하고 표시 방식을 변경합니다. 순간이 맞지만 좀 더 자연스러운 표현을 원할 때 사용하세요.

두번째 방법은 기본 순간을 변경합니다. 잘못된 시간대 레이블이 지정된 인스턴트가 있고 수정해야 할 때 사용합니다.

이상으로 날짜와 시간 형식의 데이터에 대해서 공부해 보았습니다. 신용평가모형과 관련된 업무를 수행하게 될 때, 날짜와 관련된 연산을 굉장히 많이 사용합니다. 그도 그럴 것이 누가 언제 어떤 신용거래를 일으켰는지에 대한 데이터가 가장 많기 때문입니다. 날짜와 시간 형식의 데이터. 꼭! 알아두시길 바랍니다!
'R 프로그래밍 > R advance' 카테고리의 다른 글
| 와이드 포맷과 롱 포맷 간 데이터 변환 (0) | 2021.12.28 |
|---|---|
| [R그래픽스]커뮤니케이션을 위한 그래픽 (0) | 2021.07.20 |
| [R데이터다루기]데이터 변환 (0) | 2021.07.18 |
| [R그래픽스]데이터 시각화 (0) | 2021.07.17 |
| [R데이터구조]Tibble (0) | 2021.07.15 |




댓글