본 포스팅은 pandas 패키지 라이브러리 원문을 기반으로 하여 작성하였습니다.
DataFrame은 잠재적으로 다른 유형의 열이 있는 2차원 레이블 데이터 구조입니다.
스프레드시트나 SQL 테이블 또는 Series 개체의 딕셔너리처럼 생각할 수 있습니다.
일반적으로 가장 일반적으로 사용되는 pandas 개체입니다.
Series와 마찬가지로 DataFrame은 다양한 종류의 입력을 허용합니다.
- Dict of 1D ndarrays, lists, dicts, or Series
- 2-D numpy.ndarray
- Structured or record ndarray
- A Series
- Another DataFrame
데이터와 함께 인덱스(행 레이블) 및 열(열 레이블) 인수를 선택적으로 전달할 수 있습니다.
인덱스 및/또는 열을 전달하면 결과 DataFrame의 인덱스 및/또는 열이 보장됩니다.
따라서 Series dict와 특정 인덱스는 전달된 인덱스와 일치하지 않는 모든 데이터를 버립니다.
축 레이블이 전달되지 않으면 상식 규칙에 따라 입력 데이터에서 구성됩니다.
데이터가 dict이고 열이 지정되지 않은 경우 Python 버전 >= 3.6 및 pandas >= 0.23을 사용하는 경우 DataFrame 열은 사전의 삽입 순서에 따라 정렬됩니다. Python < 3.6 또는 pandas < 0.23을 사용하고 열이 지정되지 않은 경우 DataFrame 열은 사전 순으로 정렬된 사전 키 목록이 됩니다.
From dict of Series or dicts
결과 인덱스는 다양한 시리즈 인덱스의 합집합이 됩니다.
중첩된 dict가 있으면 먼저 Series로 변환됩니다. 열이 전달되지 않으면 열은 dict 키의 정렬된 목록이 됩니다.


행 및 열 레이블은 인덱스 및 열 속성에 액세스하여 각각 액세스 할 수 있습니다.
Note: 특정 열 집합이 data dict과 함께 전달되면 전달된 열이 dict의 key를 재정의합니다.

From dict of ndarrays / lists
ndarrays의 길이는 모두 같아야 합니다. 인덱스가 전달되면 배열과 길이가 동일해야 합니다. 인덱스가 전달되지 않으면 결과는 range(n)이 됩니다. 여기서 n은 배열 길이입니다.

From structured or record array
이 경우는 배열의 dict과 동일하게 처리됩니다.

Note: DataFrame은 2차원 NumPy ndarray처럼 정확하게 작동하지 않습니다.
From a list of dicts
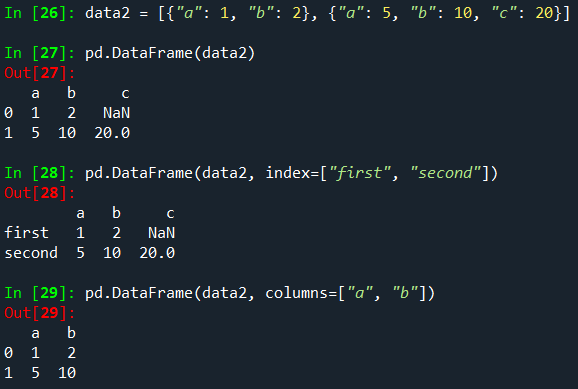
From a dict of tuples
튜플 딕셔너리를 전달하여 MultiIndexed 프레임을 자동으로 생성할 수 있습니다.

From a Series
결과는 입력 시리즈와 인덱스가 동일하고 이름이 시리즈의 원래 이름인 열 하나가 있는 DataFrame이 됩니다
(다른 열 이름이 제공되지 않은 경우에만).
From a list of namedtuples
리스트에서 첫 번째 명명된 튜플의 필드 이름은 DataFrame의 열을 결정합니다. 나머지 명명된 튜플(또는 튜플)은 단순히 압축을 풀고 해당 값이 DataFrame의 행에 공급됩니다. 이러한 튜플 중 하나가 첫 번째 명명된 튜플보다 짧으면 해당 행의 나중 열이 결측 값으로 표시됩니다. 첫 번째 명명된 튜플보다 긴 것이 있으면 ValueError가 발생합니다.

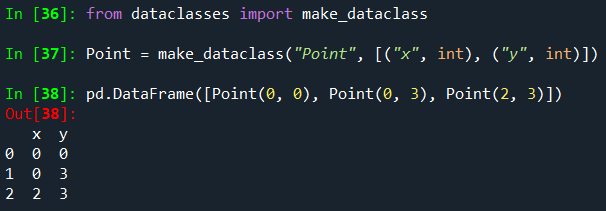
From a list of dataclasses
PEP557에 도입된 데이터 클래스는 DataFrame 생성자로 전달할 수 있습니다.
데이터 클래스 리스트를 전달하는 것은 사전 리스트를 전달하는 것과 같습니다.
리스트의 모든 값은 데이터 클래스여야 하며 리스트의 유형을 혼합하면 TypeError가 발생합니다.
Missing data
Missing data 섹션에서 이 주제에 대해 더 많이 설명할 것입니다.
누락된 데이터로 DataFrame을 구성하기 위해 np.nan을 사용하여 누락된 값을 나타냅니다.
또는 numpy.MaskedArray를 DataFrame 생성자에 대한 데이터 인수로 전달할 수 있으며
마스킹된 항목은 누락된 것으로 간주됩니다.
Alternate constructors
DataFrame.from_dict
DataFrame.from_dict는 dict의 dict 또는 배열과 유사한 시퀀스의 dict를 사용하여 DataFrame을 반환합니다.
기본적으로 '열'인 오리엔트 매개변수를 제외하고 DataFrame 생성자처럼 작동하지만,
사전 키를 행 레이블로 사용하기 위해 '인덱스'로 설정할 수 있습니다.

orient='index'를 전달하면 키가 행 레이블이 됩니다. 이 경우 원하는 열 이름을 전달할 수도 있습니다.

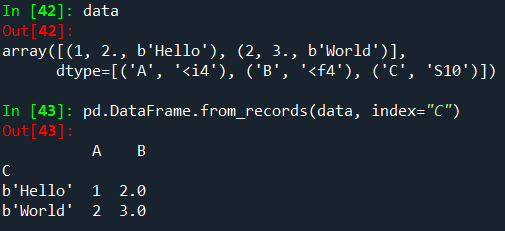
DataFrame.from_records
DataFrame.from_records는 구조화된 dtype이 있는 튜플 또는 ndarray 목록을 사용합니다.
결과 DataFrame 인덱스가 구조화된 dtype의 특정 필드일 수 있다는 점을 제외하고는
일반 DataFrame 생성자와 유사하게 작동합니다.
예를 들어
Column selection, addition, deletion
DataFrame은 인덱스가 유사한 Series 객체의 dict처럼 의미적으로 취급할 수 있습니다.
열 가져오기, 설정 및 삭제는 유사한 dict 작업과 동일한 구문으로 작동합니다.
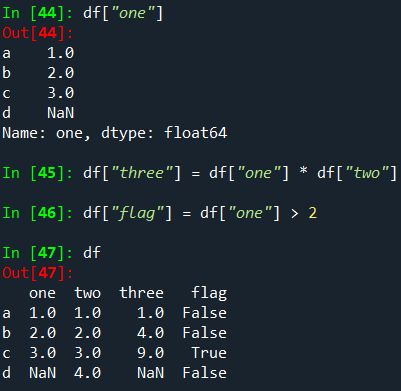
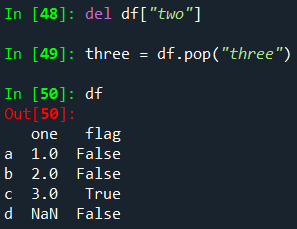
딕셔너리와 같이 열을 삭제하거나 팝할 수 있습니다.
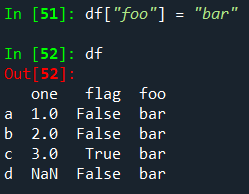
스칼라 값을 삽입하면 열을 채우기 위해 자연스럽게 전파됩니다.
DataFrame과 동일한 인덱스가 없는 Series를 삽입할 때 DataFrame의 인덱스를 따릅니다.
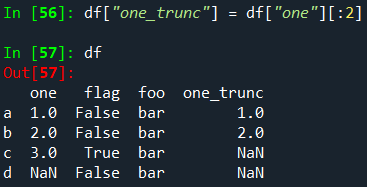
원시 ndarray를 삽입할 수 있지만 길이는 DataFrame의 인덱스 길이와 일치해야 합니다.
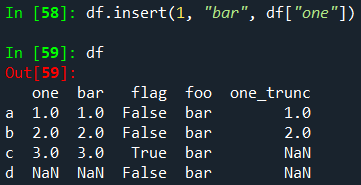
기본적으로 열은 끝에 삽입됩니다. insert 함수는 열의 특정 위치에 삽입할 수 있습니다.
Assigning new columns in method chains
dplyr의 mutate 동사에서 영감을 받은 DataFrame에는
기존 열에서 잠재적으로 파생된 새 열을 쉽게 만들 수 있는 assign() 메서드가 있습니다.
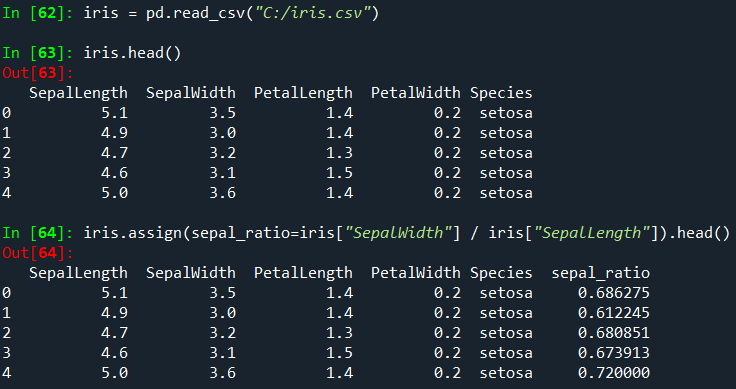
위의 예에서는 미리 계산된 값을 삽입했습니다.
할당되는 DataFrame에서 평가할 인수 하나의 함수를 전달할 수도 있습니다.
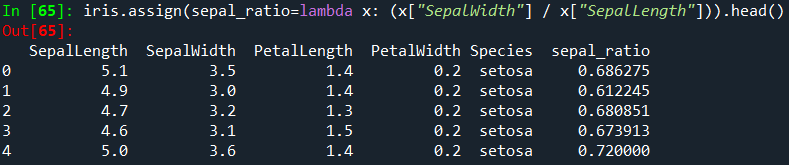
assign은 항상 데이터 복사본을 반환하고 원본 DataFrame은 그대로 둡니다.
삽입할 실제 값과 반대로 호출 가능을 전달하는 것은 손에 DataFrame에 대한 참조가 없을 때 유용합니다.
이는 작업 체인에서 할당을 사용할 때 일반적입니다.
예를 들어, Sepal Length가 5보다 큰 관측으로 DataFrame을 제한하고, 비율을 계산하고, 플롯 할 수 있습니다.
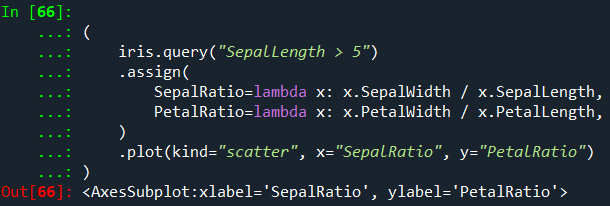
함수가 전달되기 때문에 함수는 할당되는 DataFrame에서 계산됩니다.
이것은 꽃받침 길이가 5보다 큰 행으로 필터링된 DataFrame입니다.
필터링이 먼저 발생하고 비율 계산이 수행됩니다.
이것은 사용 가능한 필터링된 DataFrame에 대한 참조가 없는 예입니다.
assign에 대한 함수 서명은 단순히 **kwargs입니다.
키는 새 필드의 열 이름이고 값은 삽입할 값(예: Series 또는 NumPy 배열)이거나
DataFrame에서 호출할 한 인수의 함수입니다.
새 값이 삽입된 원본 DataFrame의 복사본이 반환됩니다.
Python 3.6부터 **kwargs의 순서가 유지됩니다.
이것은 **kwargs의 뒷부분 식이 동일한 assign()에서 이전에 생성된 열을 참조할 수 있는 종속 할당을 허용합니다.
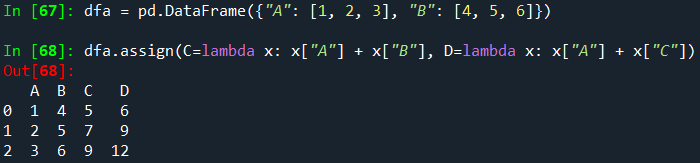
두 번째 표현식에서 x['C']는 dfa['A'] + dfa['B']와 동일한 새로 생성된 열을 참조합니다.
Indexing / selection
인덱싱의 기본은 다음과 같습니다.
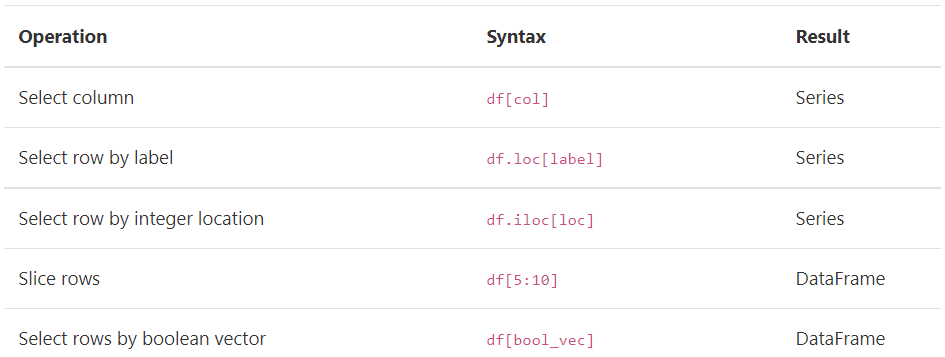
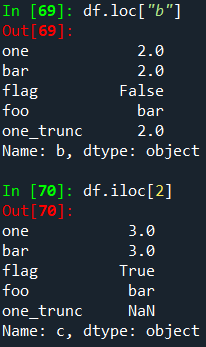
예를 들어 행 선택은 인덱스가 DataFrame의 열인 Series를 반환합니다.
Data alignment and arithmetic
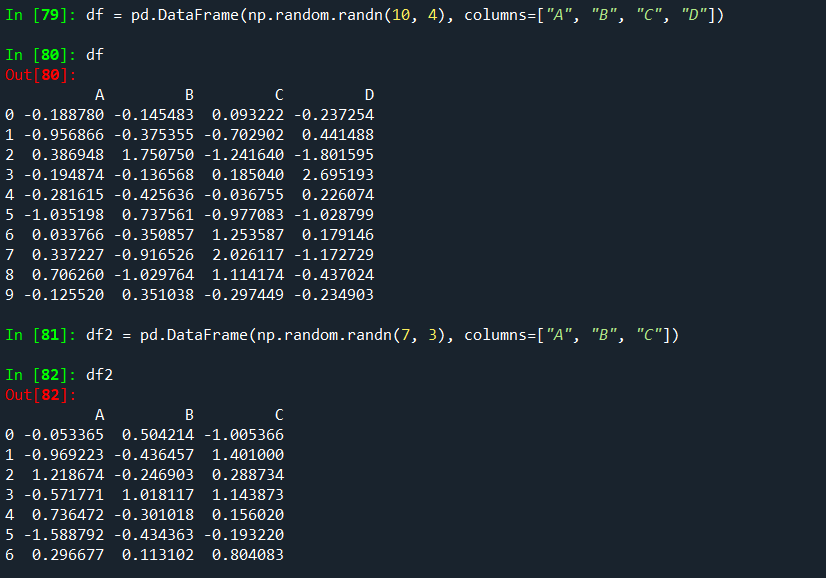
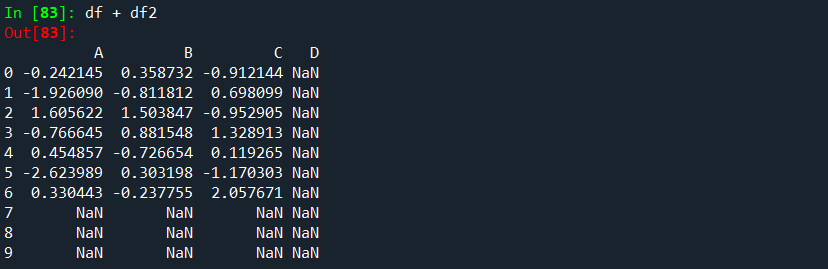
DataFrame 개체 간의 데이터 정렬은 열과 인덱스(행 레이블) 모두에 자동으로 정렬됩니다.
다시 말하지만 결과 개체에는 열 및 행 레이블의 합집합이 있습니다.
DataFrame과 Series 간에 작업을 수행할 때 기본 동작은
DataFrame 열에 Series 인덱스를 정렬하여 행 단위로 브로드캐스트하는 것입니다. 예를 들어
스칼라 연산은 예상대로입니다.
부울 연산자도 작동합니다.
Transposing
전치하려면 ndarray와 유사한 T 속성(전치 기능도 포함)에 액세스합니다.

DataFrame interoperability with NumPy functions
Elementwise NumPy ufuncs(log, exp, sqrt, …) 및 기타 다양한 NumPy 함수는
Series 및 DataFrame에서 문제없이 사용할 수 있으며, 내부 데이터가 숫자라고 가정합니다.
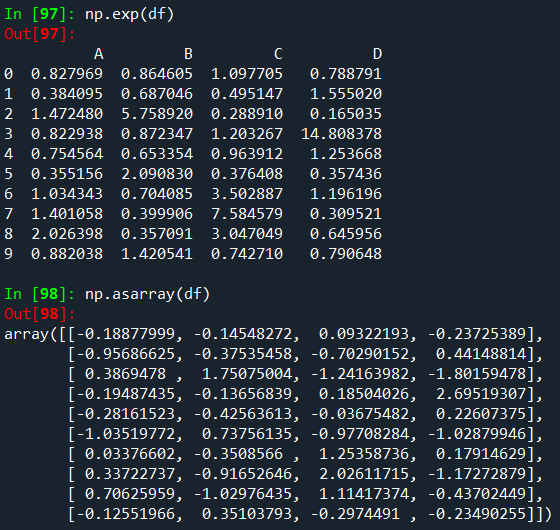
DataFrame은 인덱싱 의미 체계와 데이터 모델이 n차원 배열과 상당히 다르기 때문에 ndarray를 대체할 수 없습니다.
시리즈는 __array_ufunc__를 구현하므로 NumPy의 범용 함수와 함께 작동할 수 있습니다.
ufunc는 Series의 기본 배열에 적용됩니다.
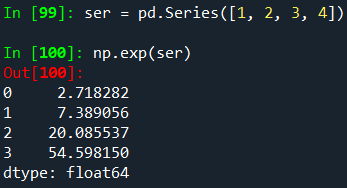
바이너리 ufunc가 Series 및 Index에 적용되면 Series 구현이 우선적으로 적용되고 Series가 반환됩니다.
Console display
매우 큰 DataFrame은 콘솔에 표시하기 위해 잘립니다.
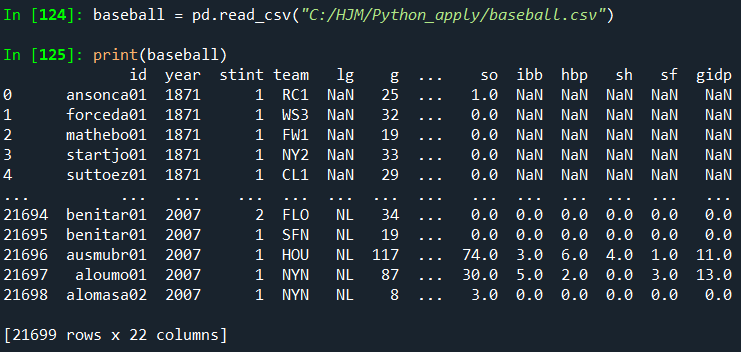
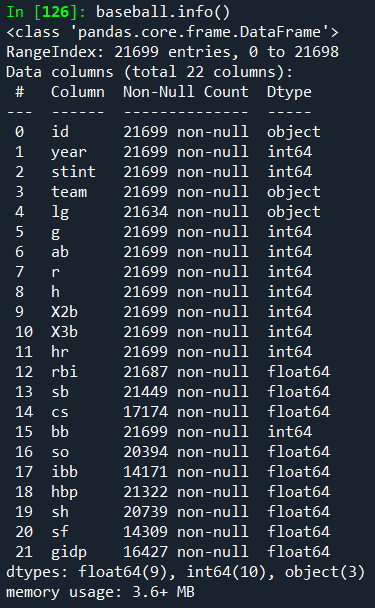
info()를 사용하여 요약을 얻을 수도 있습니다.
(여기서 plyr R 패키지에서 야구 데이터 세트의 CSV 버전을 읽고 있습니다)
그러나 to_string을 사용하면 DataFrame의 문자열 표현을 테이블 형식으로 반환하지만
항상 콘솔 너비에 맞지는 않습니다.
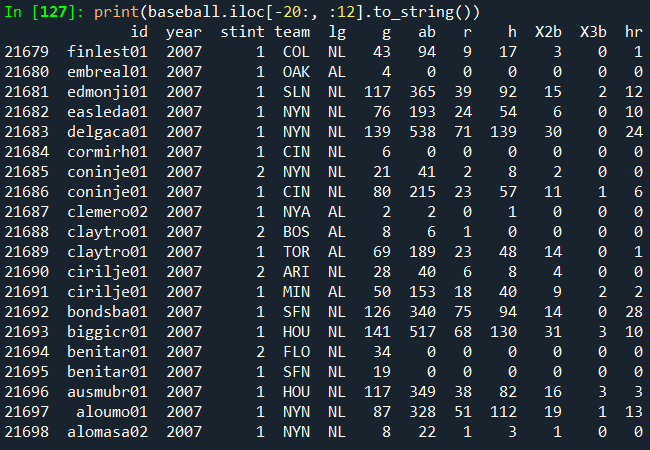
Wide DataFrame은 기본적으로 여러 행에 걸쳐 인쇄됩니다.
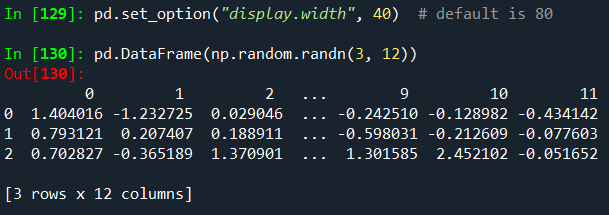
display.width 옵션을 설정하여 단일 행에 인쇄할 양을 변경할 수 있습니다.
display.max_colwidth를 설정하여 개별 열의 최대 너비를 조정할 수 있습니다.
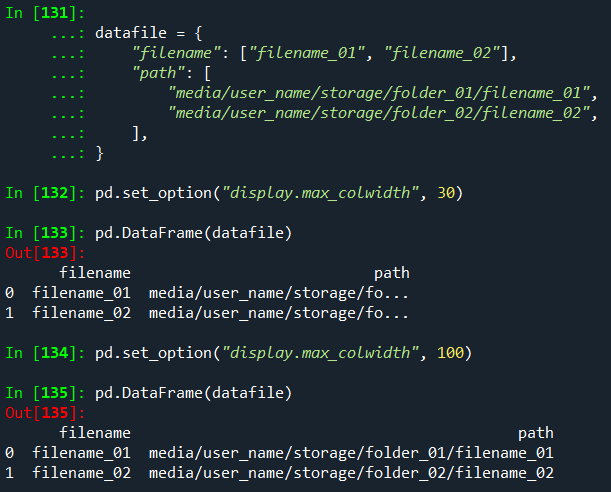
expand_frame_repr 옵션을 통해 이 기능을 비활성화할 수도 있습니다.
이렇게 하면 테이블이 한 블록에 인쇄됩니다.
DataFrame column attribute access and IPython completion
DataFrame 열 레이블이 유효한 Python 변수 이름인 경우 열은 속성처럼 액세스 할 수 있습니다.
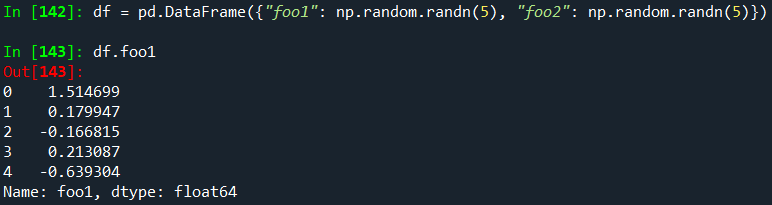
이상, 파이썬의 데이터 구조 중의 하나인 DataFrame에 대해서 알아보았습니다.
'Python > Pandas' 카테고리의 다른 글
| pandas 문자열 메서드 str. (0) | 2022.02.13 |
|---|---|
| pandas 데이터 결합 함수 merge() (0) | 2022.02.13 |
| pandas 데이터 구조 소개(Series) (0) | 2021.10.15 |
| Pandas Getting data in/out (0) | 2021.09.23 |
| Pandas Plotting (0) | 2021.09.22 |


댓글