본 포스팅은 Pandas 패키지 라이브러리 원문을 기반으로 하여 작성하였습니다.
데이터 구조 소개
pandas의 기본 데이터 구조에 대한 개요부터 알아보도록 하겠습니다. 데이터 유형, 인덱싱 및 축 레이블 지정/정렬에 대한 기본 동작은 모든 개체에 적용됩니다. 시작하려면 NumPy와 pandas 라이브러리를 먼저 로드하도록 하겠습니다.
import numpy as np
import pandas as pd
다음은 반드시 알아야 할 기본 원칙입니다. 데이터 정렬은 본질적입니다. 레이블과 데이터 간의 연결은 사용자가 명시적으로 수행하지 않는 한 끊어지지 않습니다. 데이터 구조에 대해서 간략히 소개하고, 별도의 섹션에서 광범위한 기능 및 메서드 범주를 모두 알아보겠습니다.
Series
Series는 모든 데이터 유형(정수, 문자열, 부동 소수점 숫자, Python 개체 등)을 보유할 수 있는 1차원 레이블 배열입니다. 축 레이블을 집합적으로 인덱스라고 합니다. 시리즈를 만드는 기본 방법은 아래와 같습니다.
s = pd.Series(data, index=index)
여기서 데이터는 여러 가지가 될 수 있습니다.
- a Python dict
- an ndarray
- a scalar value (like 5)
전달된 인덱스는 축 레이블 리스트입니다. 따라서 이것은 데이터가 무엇인지에 따라 몇 가지 경우로 나뉩니다.
1) From ndarray
데이터가 ndarray인 경우 인덱스는 데이터와 길이가 같아야 합니다. 인덱스가 전달되지 않으면 값이 [0, ..., len(data) - 1]인 인덱스가 생성됩니다.
s = pd.Series(np.random.randn(5), index=["a", "b", "c", "d", "e"])
s

s.index
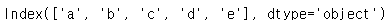
pd.Series(np.random.randn(5))

Note: pandas는 고유하지 않은 인덱스 값을 지원합니다. 중복 인덱스 값을 지원하지 않는 작업을 시도하면 그 때 예외가 발생합니다. 게으른 이유는 거의 모든 성능을 기반으로 합니다(인덱스가 사용되지 않는 GroupBy의 일부와 같이 계산에 많은 인스턴스가 있음).
2) From dict
dicts에서 series를 인스턴스화할 수 있습니다.
d = {"b": 1, "a": 0, "c": 2}
pd.Series(d)

Note: 데이터가 딕셔너리이고, 인덱스가 전달되지 않은 경우 Python 버전 >= 3.6 및 pandas 버전 >= 0.23을 사용하는 경우 Series 인덱스는 딕셔너리의 삽입 순서에 따라 정렬됩니다. Python < 3.6 또는 pandas < 0.23을 사용 중이고 인덱스가 전달되지 않은 경우 Series 인덱스는 사전적으로 정렬된 딕셔너리 키 리스트가 됩니다.
위의 예에서 Python 버전이 3.6 미만이거나 pandas 버전이 0.23 미만인 경우 Series는 사전 키의 어휘 순서에 따라 정렬됩니다(즉, ['b', 'a', 'c']가 아니라 ['a', 'b', 'c' ]).
인덱스가 전달되면 인덱스의 레이블에 해당하는 데이터의 값이 제거됩니다.
d = {"a": 0.0, "b": 1.0, "c": 2.0}
pd.Series(d)

pd.Series(d, index=["b", "c", "d", "a"])
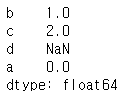
Note: NaN(숫자가 아님)은 pandas에서 사용되는 표준 누락 데이터 마커입니다.
3) From scalar value
데이터가 스칼라 값이면 인덱스를 제공해야 합니다. 인덱스의 길이와 일치하도록 값이 반복됩니다.
pd.Series(5.0, index=["a", "b", "c", "d", "e"])
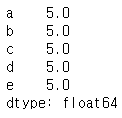
ndarray와 유사한 Series
Series는 ndarray와 매우 유사하게 작동하며 대부분의 NumPy 함수에 대한 유효한 인수입니다. 그러나 슬라이싱과 같은 작업은 인덱스도 슬라이싱 합니다.

NumPy 배열과 마찬가지로 pandas Series에는 dtype이 있습니다.
s.dtype
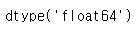
이것은 종종 NumPy dtype입니다. 그러나 pandas 및 타사 라이브러리는 NumPy의 유형 시스템을 몇 군데에서 확장합니다. 이 경우 dtype은 ExtensionDtype이 됩니다. pandas의 몇 가지 예는 범주형 데이터 및 Nullable 정수 데이터 유형입니다. 자세한 내용은 dtypes를 참조하세요.
Series를 지원하는 실제 array가 필요한 경우 Series.array를 사용하시면 됩니다.
s.array
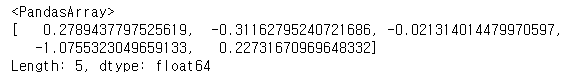
배열에 액세스하는 것은 인덱스 없이 일부 작업을 수행해야 할 때 유용할 수 있습니다
(예: 자동 정렬을 비활성화하기 위해).
Series.array는 항상 ExtensionArray입니다. ExtensionArray는 numpy.ndarray와 같은 하나 이상의 구체적인 배열을 둘러싼 얇은 래퍼입니다. pandas는 ExtensionArray를 가져와 Series 또는 DataFrame의 열에 저장할 수 있습니다.
Series는 ndarray와 유사하지만 실제 ndarray가 필요한 경우 Series.to_numpy()를 사용하시면 됩니다.
s.to_numpy()
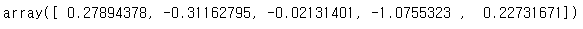
Series가 ExtensionArray에 의해 지원되더라도 Series.to_numpy()는 NumPy ndarray를 반환합니다.
딕셔너리와 유사한 시리즈
Series는 인덱스 레이블로 값을 가져오고 설정할 수 있다는 점에서 고정 크기의 딕셔너리와 같습니다.

레이블이 포함되어 있지 않으면 예외가 발생합니다.
s["f"]

get 메서드를 사용하면 누락된 레이블이 None 또는 지정된 기본값을 반환합니다.
s.get("f")
s.get("f", np.nan)
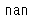
Series를 사용한 벡터화된 작업 및 레이블 정렬
원시 NumPy 배열로 작업할 때 값 별로 루핑 하는 것은 일반적으로 필요하지 않습니다. pandas에서 Series로 작업할 때도 마찬가지입니다. 시리즈는 ndarray를 기대하는 대부분의 NumPy 메서드에 전달할 수도 있습니다.
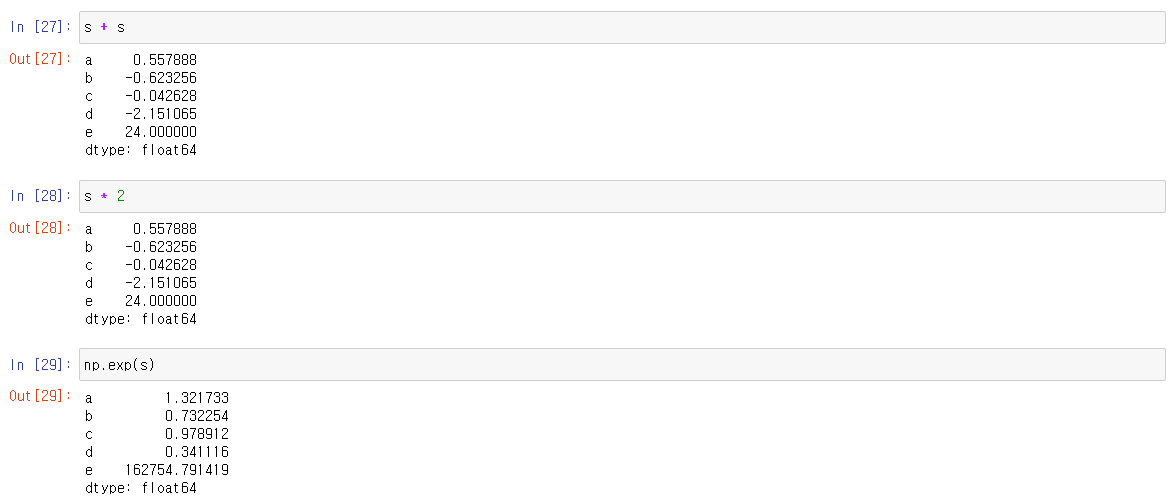
Series와 ndarray의 주요 차이점은 Series 간의 작업이 레이블을 기반으로 데이터를 자동으로 정렬한다는 것입니다. 따라서 관련된 Series에 동일한 레이블이 있는지 여부를 고려하지 않고 계산을 작성할 수 있습니다.
s[1:] + s[:-1]
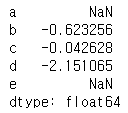
정렬되지 않은 Series 간의 작업 결과에는 관련된 인덱스의 합집합이 있습니다. 한 Series 또는 다른 Series에서 레이블을 찾을 수 없는 경우 결과는 누락된 NaN으로 표시됩니다. 명시적인 데이터 정렬을 수행하지 않고 코드를 작성할 수 있다는 것은 대화형 데이터 분석 및 연구에서 엄청난 자유와 유연성을 부여합니다. pandas 데이터 구조의 통합 데이터 정렬 기능은 레이블이 지정된 데이터 작업을 위한 대부분의 관련 도구와 pandas를 구분합니다.
Note: 일반적으로 정보 손실을 방지하기 위해 서로 다르게 인덱싱 된 개체 간의 작업의 기본 결과가 인덱스의 합집합을 생성하도록 선택했습니다. 데이터가 누락된 경우에도 인덱스 레이블을 갖는 것은 일반적으로 계산의 일부로 중요한 정보입니다. 물론 dropna 기능을 통해 누락된 데이터가 있는 레이블을 삭제할 수도 있습니다.
이름 속성
Series에는 다음과 같은 이름 속성도 있을 수 있습니다.
s = pd.Series(np.random.randn(5), name="something")
s
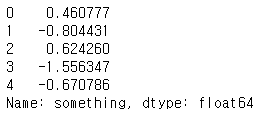
s.name

Series 이름은 많은 경우, 특히 아래에서 볼 수 있는 것처럼 DataFrame의 1D 슬라이스를 가져올 때 자동으로 할당됩니다. pandas.Series.rename() 메서드를 사용하여 Series의 이름을 바꿀 수 있습니다.
s2 = s.rename("different") s2.name
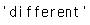
s와 s2는 다른 객체를 참조합니다.
다음 포스팅에서는 다른 데이터 구조인 DataFrame에 대해서 알아보겠습니다.
'Python > Pandas' 카테고리의 다른 글
| pandas 데이터 결합 함수 merge() (0) | 2022.02.13 |
|---|---|
| pandas 데이터 구조 소개(DataFrame) (0) | 2022.01.29 |
| Pandas Getting data in/out (0) | 2021.09.23 |
| Pandas Plotting (0) | 2021.09.22 |
| Pandas Categoricals (0) | 2021.09.21 |



댓글