Pandas는 파이썬에서
데이터 정리와 관련하여
국제적 표준과도 같습니다.
Pandas는 다차원 배열을 지원하는
Numpy를 기반으로 합니다.
Pandas는 Data Science 도구 상자에
추가할 때 장점이 될 수 있습니다.
pandas에서는 1인치 길이의
아인슈타인 방정식 { E=mc**2 }보다
길지 않은 간단한 함수를 사용하여
짧은 시간에 큰 작업을
수행할 수 있습니다.
Pandas 기능
Pandas는 큰 작업을
쉽게 수행할 수 있게 해주는
매우 빠른 도구입니다.
여기에는
데이터 정리,
누락된 값 채우기,
데이터 정규화,
통계 분석
등이 포함됩니다.
Jupyter Notebook에 Pandas 설치
Pandas는 Anaconda 배포판의 일부이며
다음 명령으로 Anaconda
프롬프트를 사용하여
쉽게 설치할 수 있습니다.
{ conda install pandas }
혹은
{ pip install pandas }
이제 pandas를 jupyter notebook으로
가져올 준비가 되었습니다.
설치 여부를 확인하려면
다음을 실행하세요.
import pandas as pd
오류 메시지가 표시되면
설치되지 않았다는 의미이고,
오류 메시지가 없다면,
계속 진행하시면 됩니다.
Kaggle FIFA Dataset
이러한 함수들을 설명하기 위해
Kaggle에서 널리 사용되는
FIFA 데이터 세트를 이용하겠습니다.
관련 자료는 아래 링크를 참고하세요.
FIFA 21 complete player dataset
18k+ players, 100+ attributes extracted from the latest edition of FIFA
www.kaggle.com
1. 파일 읽기
위의 자료는 엑셀 형태로 구성된
데이터입니다.
엑셀에 저장된 데이터를 읽으려면
아래 명령을 사용할 수 있습니다.
fifa21 = pd.read_excel("C:\Career Mode player datasets - FIFA 15-21.xlsx", sheet_name = "FIFA 21")
데이터 세트의 처음 5개 행 가져오기
데이터 세트의 처음 5개 행에
액세스 하려면
head() 함수를 사용하세요.
기본적으로 처음 5개 행이 반환됩니다.
head 내부에서 액세스 하려는
행의 갯수를 수정할 수도 있어요.
예를 들어,
head()의 인수에 10을 입력하면(head(10))
처음 10개의 행에 접근할 수 있어요.
import pandas as pd
import numpy as np
## FIFA 자료 중 21년 자료만 읽기
fifa21 = pd.read_excel("C:\Career Mode player datasets - FIFA 15-21.xlsx", sheet_name = "FIFA 21")
## 데이터 세트의 행과 열의 개수 확인
fifa21.shape()
# (18944, 106)
## 화면에 보이는 최대 칼럼 수를
## 데이터 세트의 열의 개수로 세팅
pd.set_option('display.max_columns', 106)
fifa21.head()
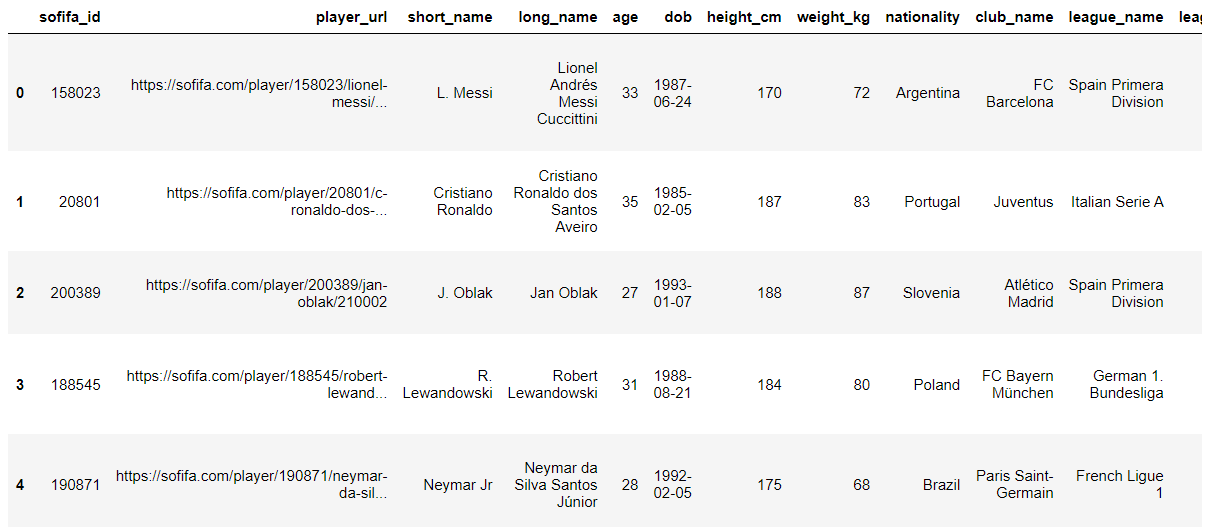
2. 데이터 세트의 모든 열 가져오기
열의 개수가 이와 같이 많을 경우,
데이터 세트를 처리할 때,
모든 열을 가져오기가 어렵습니다.
주어진 데이터 세트의
모든 열을 확인하려면,
DataFrames.colums를
이용하면 됩니다.
fifa21.columns

칼럼의 리스트를
모두 출력하고자 한다면,
리스트로 변환하면 됩니다.
list(fifa21.columns)
# 출력 예시 생략
3. 열 삭제
실제로 필요한 데이터 세트에
불필요한 열이 있습니다.
따라서 불필요한 열을
제거하기 위해
DataFrames.drop()
함수를 사용합니다.
fifa21.drop(columns = ['player_url', 'short_name', 'dob']).head()
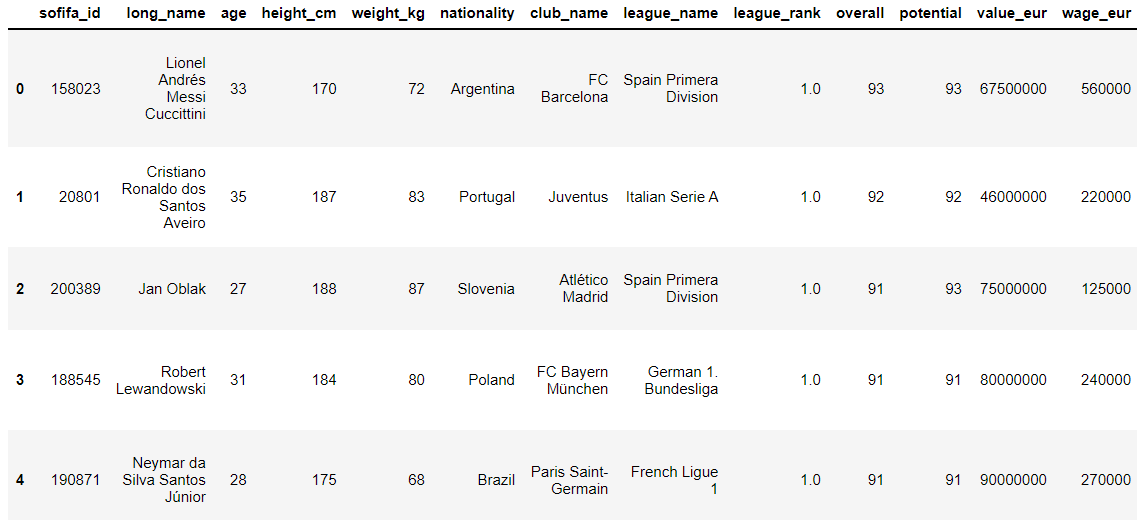
4. DataFrame의 길이
데이터 세트의 데이터 프레임
길이를 표시하기 위해서는
len() 함수를 사용합니다.
len() 함수는
총 행 수를 반환합니다.
len(fifa21)
# 18944
5. df. query
조건문을 사용하여
필터링/쿼리 할 수 있습니다.
이 예에서는
'overall' 및 'potential' 열을
사용하겠습니다.
아래와 같이 실행하면
'potential'이 'overall'보다
큰 행만 반환됩니다.
fifa21.query("overall < potential")
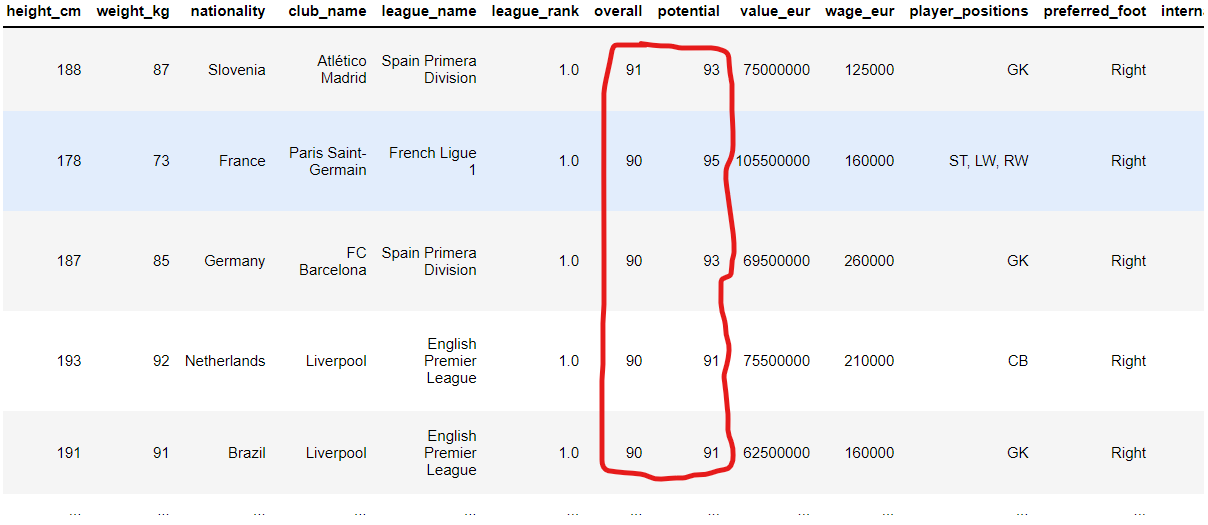
6. df.iloc( )
이 함수는 행과 열 인덱스를
사용하여 DataFrame의 하위 집합을
반환합니다.
예를 들어, 아래의 명령어는
처음 10개의 행을 취하고,
6-10번째 열을 인덱싱을 나타냅니다.
fifa21.iloc([:10, 5:10])
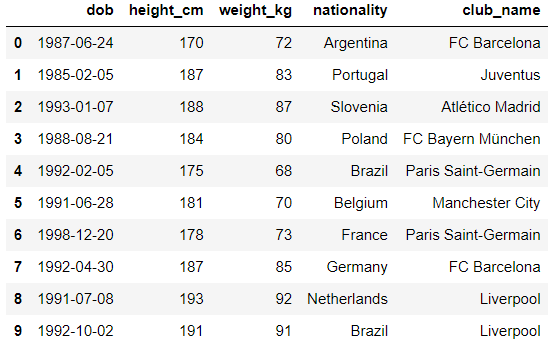
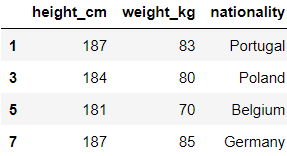
7. df.loc()
이 함수는 .iloc()과
거의 동일하게 수행됩니다.
원하는 행 인덱스를
정확히 지정하고,
열 이름도 지정할 수 있습니다.
fifa21.loc[[1,3,5,7], ['height_cm', 'weight_kg', 'nationality']]
8. 데이터 세트의 데이터 유형 확인(dtypes)
데이터 랭글링이 관련 작업을
신속하게 수행하려면
데이터의 특성과 각 열의
데이터 유형을 이해하는 것이
중요합니다.
fifa21.dtypes

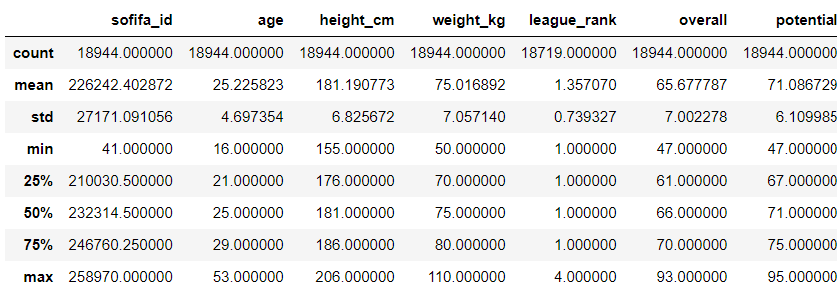
9. 기술 통계
describe() 함수를 적용하면,
데이터 세트의 요약 또는
설명 통계가 제공됩니다.
이 기능은 데이터가
숫자 형식인 경우에만 작동합니다.
범주형 데이터의 경우 describe( ) 함수는
데이터 세트의 값(value)만
계산(count)합니다.
fifa21.describe()
10. unique values 찾기
범주형 값이 있을 때 매우 유용합니다.
데이터 세트의 범주형 열에서
unique 한 값을 파악하는 데 사용됩니다.
여기서는 데이터 세트의
"club_name" 열에 적용했습니다.
fifa21.club_name.unique()

11. 데이터 세트에서 샘플링
방대한 데이터 세트가 있는 경우
데이터 세트에서 작은 대표 샘플을
가져올 수 있습니다.
예를 들어, 데이터 세트에서
25% random sampling을 수행했습니다.
fifa21.sample(frac = 0.25)
12. 열의 unique value 확인
이 함수는 데이터 세트의 특정 열에 있는
고유 값의 총개수를 반환합니다.
얼마나 많은 유럽리그가 있는지
확인하고 싶다면?
fifa21.league_name.nunique()
# 52
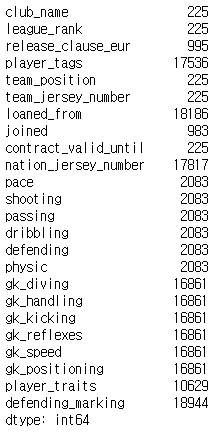
13. 결측치
데이터 세트의 Null 값을 확인하려면
isnull().sum()을 사용하여
각 열의 null 값 수를 반환할 수 있습니다.
fifa21.isnull().sum()[fifa21.isnull().sum() > 0]
14. 칼럼명 변경
DataFrames.rename를 사용하여
데이터 세트의 특정 열 이름을
바꿀 수 있습니다.
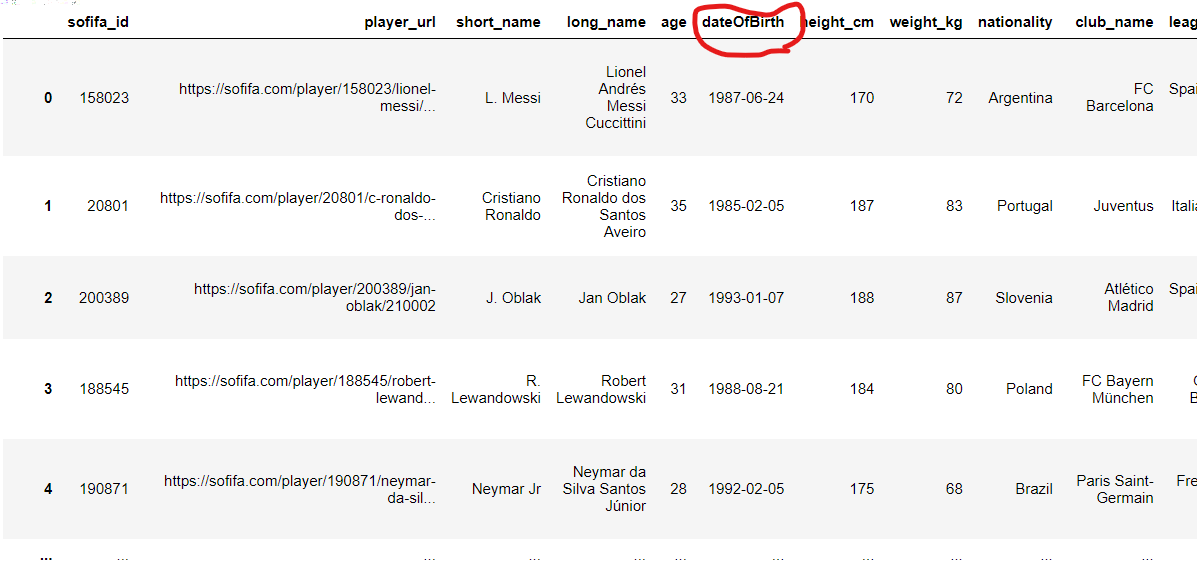
'dob'를 'dateOfBirth'로 변경합니다.
fifa21.rename(columns = {"dob": "dateOfBirth"})
15. Null 값 채우기
데이터 유형에 따라
다양한 접근 방식으로
null 값을 채울 수 있습니다.
범주형 데이터의 경우
mode(최빈값)를 사용하는 것이 좋으며,
숫자형의 경우
평균과 중앙값을 사용합니다.
여기에서 범주형 열
'nation_position' 및 'league_name'에 대한 mode로
null 값을 채웠습니다.
cols = ['nation_position','league_name']
fifa21[cols] = fifa21[cols].fillna(fifa21[cols].mode().iloc[0])
fifa21.isnull().sum()[fifa21.isnull().sum() > 0]
16. Group By
데이터 집계에서
가장 많이 사용되는 함수(요약 형식).
데이터를 그룹화하고
그룹에 대한 유용한 정보를
파악할 수 있습니다.
여기서는 국가별로 데이터를 그룹화하고
각 국적에 대한 평균 'age'을
계산해 보겠습니다.
fifa21.groupby("nationality")["age"].mean()

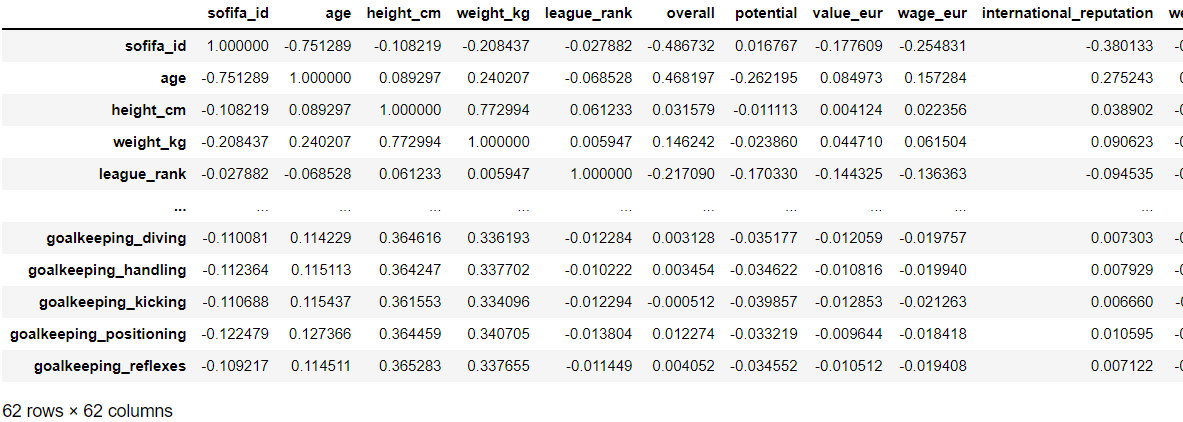
17. 상관 행렬
데이터 세트에서
두 변수 간의 관계를 찾기 위해
corr( )을 사용합니다.
두 변수의 관계 정도를 보여줍니다.
관계의 강도를 명확하게 보기 위해
seaborn(시각화 라이브러리)을 사용하여
Heatmap을 그릴 수 있습니다.
여기서는 Pearson 상관계수를
사용했습니다.
fifa21.corr(method = 'pearson')
18. 구간화 방법
데이터를 특정 범위로 나누기 위해
binning 할 수 있습니다.
Binning 방법은 데이터에서
노이즈를 제거하여 데이터를 정규화하고
매끄럽게 만드는 데 사용됩니다.
여기에서 주어진 'age' 열에 대해
5개의 빈을 만들어 보겠습니다.
pd.cut(fifa21['age'], bins = 5).value_counts()

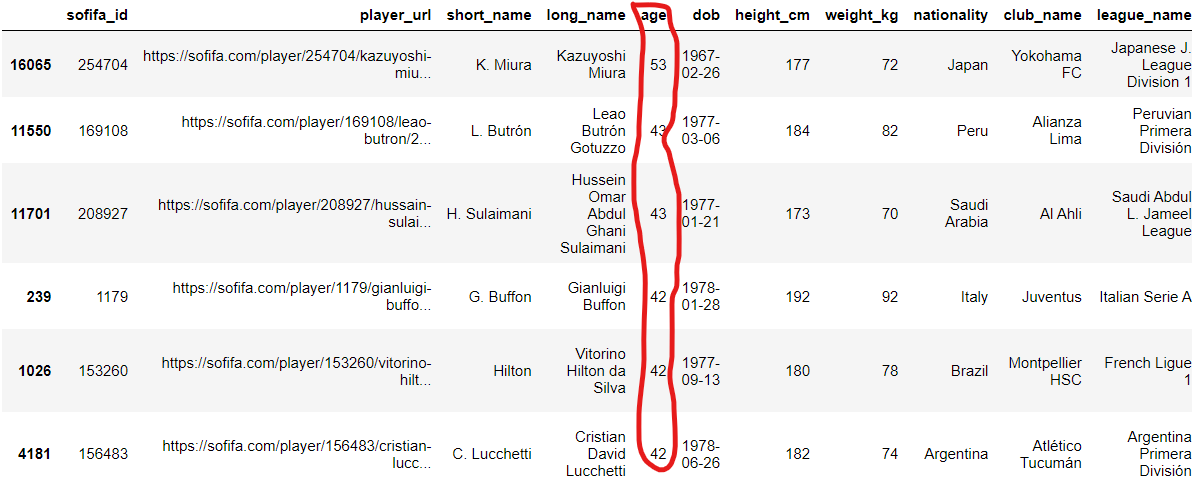
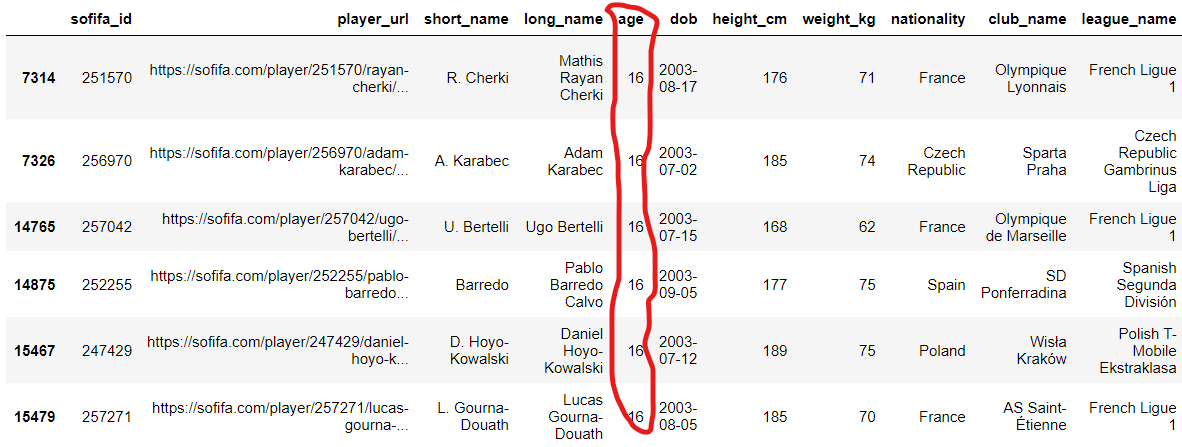
19. n개의 가장 큰 값과 가장 작은 값 찾기
주어진 특정 변수에서
n개의 가장 큰 값 또는
가장 작은 값이 있는
데이터를 제공합니다.
'age' 열의 상위 6개가 있는 행에
접근하려고 했습니다.
fifa21.nlargest(6, "age")
fifa21.nsmallest(6, "age")
20. Dataframe에 대한 정보 얻기
info() 함수는
DataFrame에 대한 정보를 반환합니다.
이 정보에는
열 수,
열 레이블,
열 데이터 유형,
메모리 사용량,
범위 인덱스,
각 열의 셀 수(null이 아닌 값)가 포함됩니다.
fifa21.info(memory_usage = 'deep')

'Python > 데이터 다루기' 카테고리의 다른 글
| Python에서 JSON을 사용하는 방법(for 초급자) (0) | 2022.05.13 |
|---|---|
| JSON에 대한 소개 (0) | 2022.05.08 |
| pandas를 활용한 데이터 정리 (0) | 2022.04.30 |
| 파일 입/출력(with 파이썬) (0) | 2022.03.01 |
| 오픈 API를 활용한 공공데이터 불러오기(데이터 포맷: json) with Python (4) | 2022.01.29 |
댓글