우리가 현실에서 마주하게 되는
실제 데이터 세트는
정리되지 않은 지저분한(?) 형태이므로
데이터가 분석에 적합하도록
데이터 전처리 또는 정리가 필수적입니다.
데이터 정리에는
1) 데이터 간격 정리
2) 데이터 오류 수정
3) 데이터 세트 결합
4) 데이터 집계
5) 새로운 feature 생성
등이 포함됩니다.
이번 포스팅에서는 pandas를 사용하여
'Marks_data'라는
매우 간단한 데이터 세트를 활용해서
데이터 정리 방법에 대해 설명합니다.
위의 데이터 세트를 다운로드하여
pandas 패키지로 로딩합니다.
import pandas as pd
# 데이터 로딩
marksData = pd.read_csv('C:\marks_data.csv')
marksData

marksData.shape
# (19, 3)
# 19개의 데이터와
# 3개의 feature로 구성
1. 결측치 처리하기
결측치를 처리하는 방법은
데이터를 얼마나 이해하는지에
달려 있습니다.
상황에 따라 결측 값을
처리하기 위한 전략이 있습니다.
예를 들어,
데이터가 입력되지 않았거나
사용할 수 없어서
누락되었을 수 있습니다.
pandas는 누락된 값을
NaN으로 나타냅니다.
1.1. 누락된 값을 값으로 채우기
정리된 데이터를 저장할 cleanData라는
새로운 데이터 프레임을 만들겠습니다.
인덱스 8과 16에 누락된 값(NaN)이 있네요.
fillna() 함수를 사용하여
NaN 값을 "unknown"으로 대체하겠습니다.
# NaN을 "unknown"으로 채우기
cleanedData = marksData.fillna('unknown')
cleanedData

위의 데이터 프레임에서
인덱스 8과 16의 NaN 값이
"알 수 없음"으로 대체되었습니다.
1.2. dropna() 함수를 사용하여 누락된 데이터가 있는 행 삭제
결측 값을 처리하는 다른 방법은
결측 값이 있는 행을 삭제하는 것입니다.
아래 코드를 사용하여
인덱스 8과 16에서 NaN 값을
삭제할 것입니다.
# 결측치 삭제
cleaneData = marksData.dropna()
cleanedData
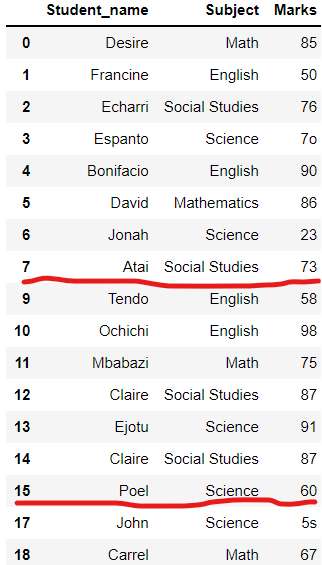
위의 데이터 프레임에서
인덱스 8과 16이 삭제되었음을
알 수 있습니다.
2. 중복 값 처리
데이터 세트를 잘 보시면,
인덱스 12와 14가 완전히
동일한 데이터라는 사실을
알았을 것입니다.
이러한 작은 데이터 세트에서도
중복 값을 찾기가 쉽지 않고,
특히 매우 큰 데이터 세트에서는
더욱 어렵습니다.
중복 값을 찾는 데 사용되는 코드는
DataFrame. duplicated()입니다.
중복 값을 처리하는 일반적인 전략은
중복 값을 삭제하는 것입니다.
drop_duplicates() 함수를 사용하여
중복을 찾아 삭제합니다.
# 모든 칼럼이 동일한 데이터 찾기
duplicateRows = marksData[marksData.duplicated()]
duplicateRows

# 모든 칼럼이 동일한 데이터 제외하기
uniqueData = marksData[~marksData.duplicated()]
uniqueData
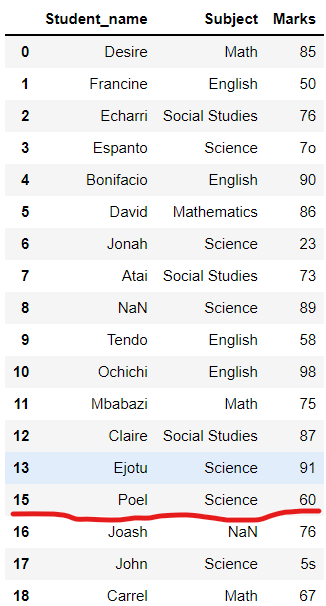
위의 데이터 프레임에서
인덱스 14가 삭제되었음을
알 수 있습니다.
3. 일치하지 않는 라벨 수정
데이터 세트에서
일관성 없는 레이블이
있음을 알 수 있습니다.
예를 들어,
'Math'와 'Mathmathics'가 있습니다.
이러한 데이터 세트에서
다른 과목(Subject)을 찾기 위해
코드를 실행하면
'Math'와 'Mathmathics'을
다른 과목으로 인식하여
4개 대신 5개를 찾게 됩니다.
결국, 컴퓨터는 다르게 인식하지만,
우리는 'Math'와 'Mathmathics'이
같다는 것을 알 수 있습니다.
# distinct 한 과목 리스트 구하기
subjects = marksData.Subject.dropna().unique()
sorted(subjects)
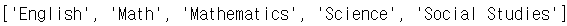
데이터 세트의 unique 한
과목 리스트를 가져온 후,
과목을 기준으로 정렬된
리스트를 가져옵니다.
# 동일한 데이터 프레임을 (깊은) 복사하기
cleanedData = marksData.copy(deep = True)
# 일치하지 않는 레이블 수정
cleanedData.update(pd.Series(['Math'], name='Subject', index=[5]))
cleanedData
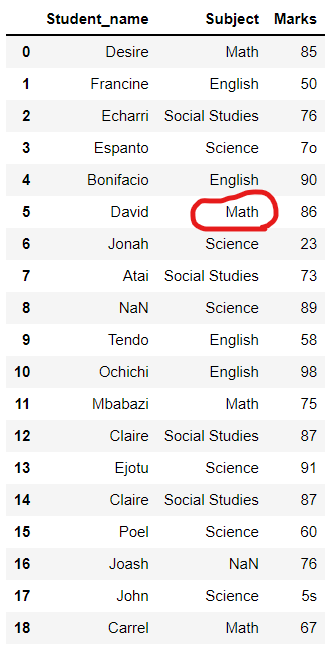
update() 함수를 사용하여
인덱스 5에 있는 과목 열의
'Mathmathics'에서 'Math'로 값을
업데이트하여,
인덱스 5의 과목이
'Mathmathics'에서 'Math'로
변경되었습니다.
4. 숫자 내 문자 값 수정
간혹, 인덱스 3과 17과 같이
숫자 안에 문자가 있을 수 있습니다.
이 경우 합계를 시도하면
오류가 발생합니다.
이러한 문제를 해결하기 위해
update() 함수를 이용합니다.
# 숫자 내 문자 값 수정
cleanedData.update(pd.Series([70], name = 'Marks', index=[3]))
cleanedData
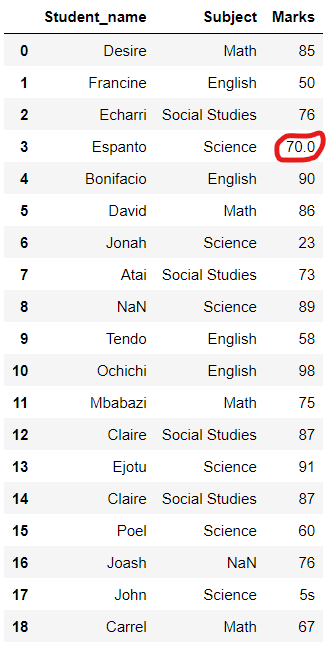
인덱스 3의 출력이 7o에서 70으로
업데이트되었습니다.
이상 pandas를 활용한 데이터 정리를
알아보았습니다.
'Python > 데이터 다루기' 카테고리의 다른 글
| Python에서 JSON을 사용하는 방법(for 초급자) (0) | 2022.05.13 |
|---|---|
| JSON에 대한 소개 (0) | 2022.05.08 |
| 데이터 분석을 위한 강력한 Pandas 함수 1 (0) | 2022.05.01 |
| 파일 입/출력(with 파이썬) (0) | 2022.03.01 |
| 오픈 API를 활용한 공공데이터 불러오기(데이터 포맷: json) with Python (4) | 2022.01.29 |

댓글